Capstone2: German credit Risk
Louis Mono
Abstract
A credit score is a numerical expression based on a level analysis of a person’s credit files, to represent the creditworthiness of an individual. Lenders, such as banks and credit card companies, use credit scores to evaluate the potential risk posed by lending money to consumers and to mitigate losses due to bad debt. Generally, financial institutions utilize it as a method to support the decision-making about credit applications. Both Machine learning (ML) and Artificial intelligence (AI) techniques have been explored for credit scoring . Although there are no consistent conclusions on which ones are better, recent studies suggest combining multiple classifiers, i.e., ensemble learning, may have a better performance. In our study, using the german credit data available on the UCI Machine Learning Repository we assessed the performance of different Machine learning techniques based on their overall accuracy, but not only, since we supported our results with accuracy measures such as AUC, F1-score, KS and Gini . Our findings suggest that random forest model with tuning parameters , support vector machine based on vanilladot Linear kernel function and lasso regression, with a good overall accuracy values lead us to the most performant AUC values, 0.7833 , 0.7794 and 0.7675, respectively.
I. Introduction
The purpose of credit scoring is to classify the applicants into two types : applicants with good credit and applicants with bad credits. When a bank receives a loan application , applicants with good credit have great possibility to repay financial obligation. Applicants with bad credit have high possibility of defaulting. The accuracy of credit scoring is critical to financial institutions profitability . Even 1% improvement on the accuracy of credit scoring of applicants with bad credit will decreases a great loss for financial institutions (Hand & Henley, 1997).
This study aims at adressing this classification problem by using the the applicant’s demographic and socio-economic profiles of german credit data to examine the risk of lending loan to the customer. We assessed the performance of different Machine learning algorithms (Logistic regression model , Decision tree, random forests, Support vector machines ,neural networks, Lasso ) in terms of overall accuracy. For the model optimization, we conducted a comparative assessment of different models combining the effects of Gini, KS, F1-score, balanced accuracy and the area under the ROC curve (AUC) values.
The remainder of the report is organized as follow. In section 2, a general insight of the Dataset is presented, with a particular attention to the Data exploration. In section 3, we perform the Data Pre-processing. Section 4 explains the Methods and Analysis over different Machine learning techniques we used and presents the metrics for the models performance evaluation, while section 5 contains our main Results. Section 6 draws Conclusions and suggestions.
II. Dataset
2.1. Overview
Loading library and data
#library
library(tidyverse)
library(rchallenge)
library(caret)
library(RColorBrewer)
library(reshape2)
library(lattice)
library (rpart)
library(rpart.plot)
library(rattle)
library(ROCR)
library(ggpubr)
library(ggthemes)
library(randomForest)
library(Information)
library(VIM)
library(Boruta)
library(e1071)
library(kernlab)
library(gridExtra)
library(nnet)
library(NeuralNetTools)
library(lars)
library(glmnet)
library(kableExtra)
library(doSNOW)
library(doParallel)
library(rmdformats)
#data
data("german")
#get class/glimpse of data
class(german) "data.frame"glimpse(german)Observations: 1,000
Variables: 21
$ Duration <dbl> 6, 48, 12, 42, 24, 36, 24, 36, 12, 3...
$ Amount <dbl> 1169, 5951, 2096, 7882, 4870, 9055, ...
$ InstallmentRatePercentage <dbl> 4, 2, 2, 2, 3, 2, 3, 2, 2, 4, 3, 3, ...
$ ResidenceDuration <dbl> 4, 2, 3, 4, 4, 4, 4, 2, 4, 2, 1, 4, ...
$ Age <dbl> 67, 22, 49, 45, 53, 35, 53, 35, 61, ...
$ NumberExistingCredits <dbl> 2, 1, 1, 1, 2, 1, 1, 1, 1, 2, 1, 1, ...
$ NumberPeopleMaintenance <dbl> 1, 1, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, ...
$ Telephone <fct> none, yes, yes, yes, yes, none, yes,...
$ ForeignWorker <fct> yes, yes, yes, yes, yes, yes, yes, y...
$ CheckingAccountStatus <fct> lt.0, 0.to.200, none, lt.0, lt.0, no...
$ CreditHistory <fct> Critical, PaidDuly, Critical, PaidDu...
$ Purpose <fct> Radio.Television, Radio.Television, ...
$ SavingsAccountBonds <fct> Unknown, lt.100, lt.100, lt.100, lt....
$ EmploymentDuration <fct> gt.7, 1.to.4, 4.to.7, 4.to.7, 1.to.4...
$ Personal <fct> Male.Single, Female.NotSingle, Male....
$ OtherDebtorsGuarantors <fct> None, None, None, Guarantor, None, N...
$ Property <fct> RealEstate, RealEstate, RealEstate, ...
$ OtherInstallmentPlans <fct> None, None, None, None, None, None, ...
$ Housing <fct> Own, Own, Own, ForFree, ForFree, For...
$ Job <fct> SkilledEmployee, SkilledEmployee, Un...
$ Class <fct> Good, Bad, Good, Good, Bad, Good, Go...The German Credit data is a dataset provided by Dr. Hans Hofmann of the University of Hamburg. It’s a publically available from the UCI Machine Learning repository at the following link: https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data). However, this dataset is also built-in in some R packages, like caret , rchallenge or evtree. We decided to use directly the german data from the rchallenge package , which is a transformed version of the GermanCredit dataset with factors instead of dummy variables.
Getting a glimpse of german data, we observe it’s a data frame containing 21 variables for a total of 1,000 observations . The response variable (or outcome,y) in the dataset corresponds to the Class label, which is a binary variable indicating credit risk or credit worthiness with levels Good and Bad. Here, we are going to describe the 20 features and their characteristics:
quantitative features
-Duration : duration in months.
-Amount: credit Amount.
-InstallmentRatePercentage: installment rate in percentage of disposable income.
-ResidenceDuration: present residence since .
-Age : Client’s age.
-NumberExistingCredits: number of existing credits at this bank.
-NumberPeopleMaintenance: number of people being liable to provide maintenance.
qualitative features
-Telephone: binary variable indicating if customer has a registered telephone number
-ForeignWorker: binary variable indicating if the customer is a foreign worker
-CheckingAccountStatus: factor variable indicating the status of checking account
-CreditHistory: factor variable indicating credit history
-Purpose: factor variable indicating the credit’s purpose
-SavingsAccountBonds: factor variable indicating the savings account/bonds
-EmploymentDuration: ordered factor indicating the duration of the current employment
-Personal: factor variable indicating personal status and sex
-OtherDebtorsGuarantors: factor variable indicating Other debtors
-Property: factor variable indicating the client’s highest valued property
-OtherInstallmentPlans: factor variable indicating other installment plans
-Housing: factor variable indicating housing
-Job: factor indicating employment status
2.2. Data exploration
First,summary statistics of the 21 variables are presented , out of which 7 are numerical attributes. Also, we can identify the various levels for the 14 categorical attributes including the outcome.
summary(german) Duration Amount InstallmentRatePercentage
Min. : 4.0 Min. : 250 Min. :1.000
1st Qu.:12.0 1st Qu.: 1366 1st Qu.:2.000
Median :18.0 Median : 2320 Median :3.000
Mean :20.9 Mean : 3271 Mean :2.973
3rd Qu.:24.0 3rd Qu.: 3972 3rd Qu.:4.000
Max. :72.0 Max. :18424 Max. :4.000
ResidenceDuration Age NumberExistingCredits
Min. :1.000 Min. :19.00 Min. :1.000
1st Qu.:2.000 1st Qu.:27.00 1st Qu.:1.000
Median :3.000 Median :33.00 Median :1.000
Mean :2.845 Mean :35.55 Mean :1.407
3rd Qu.:4.000 3rd Qu.:42.00 3rd Qu.:2.000
Max. :4.000 Max. :75.00 Max. :4.000
NumberPeopleMaintenance Telephone ForeignWorker CheckingAccountStatus
Min. :1.000 none:404 no : 37 lt.0 :274
1st Qu.:1.000 yes :596 yes:963 0.to.200:269
Median :1.000 gt.200 : 63
Mean :1.155 none :394
3rd Qu.:1.000
Max. :2.000
CreditHistory Purpose SavingsAccountBonds
NoCredit.AllPaid: 40 Radio.Television :280 lt.100 :603
ThisBank.AllPaid: 49 NewCar :234 100.to.500 :103
PaidDuly :530 Furniture.Equipment:181 500.to.1000: 63
Delay : 88 UsedCar :103 gt.1000 : 48
Critical :293 Business : 97 Unknown :183
Education : 50
(Other) : 55
EmploymentDuration Personal OtherDebtorsGuarantors
lt.1 :172 Male.Divorced.Seperated: 50 None :907
1.to.4 :339 Female.NotSingle :310 CoApplicant: 41
4.to.7 :174 Male.Single :548 Guarantor : 52
gt.7 :253 Male.Married.Widowed : 92
Unemployed: 62 Female.Single : 0
Property OtherInstallmentPlans Housing
RealEstate:282 Bank :139 Rent :179
Insurance :232 Stores: 47 Own :713
CarOther :332 None :814 ForFree:108
Unknown :154
Job Class
UnemployedUnskilled : 22 Bad :300
UnskilledResident :200 Good:700
SkilledEmployee :630
Management.SelfEmp.HighlyQualified:148
outcome, y : Class
Visual exploration of the outcome, the credit worthiness, shows that there are more people with a good risk than a bad one. In fact, 70% of applicants have a good credit risk while about 30% have a bad credit risk .Then, class are unbalanced and for our subsequent analysis the data splitting in training set and test set should be done with a stratified random sampling method.
#i create Class.prop, an object of Class 'tbl_df', 'tbl' and 'data.frame'.It contains the calculated relative frequencies or proportions for the levels Bad/Good of the credit worthiness in the german credit data.
Class.prop <- german %>%
count(Class) %>%
mutate(perc = n / nrow(german)) # bar plot of credit worthiness
Class.prop %>%
ggplot(aes(x=Class,y= perc,fill=Class))+
geom_bar(stat="identity") +
labs(title="bar plot",
subtitle = "Credit worthiness",
caption=" source: german credit data") +
geom_text(aes(label=scales::percent(perc)), position = position_stack(vjust = 1.01))+
scale_y_continuous(labels = scales::percent)+
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))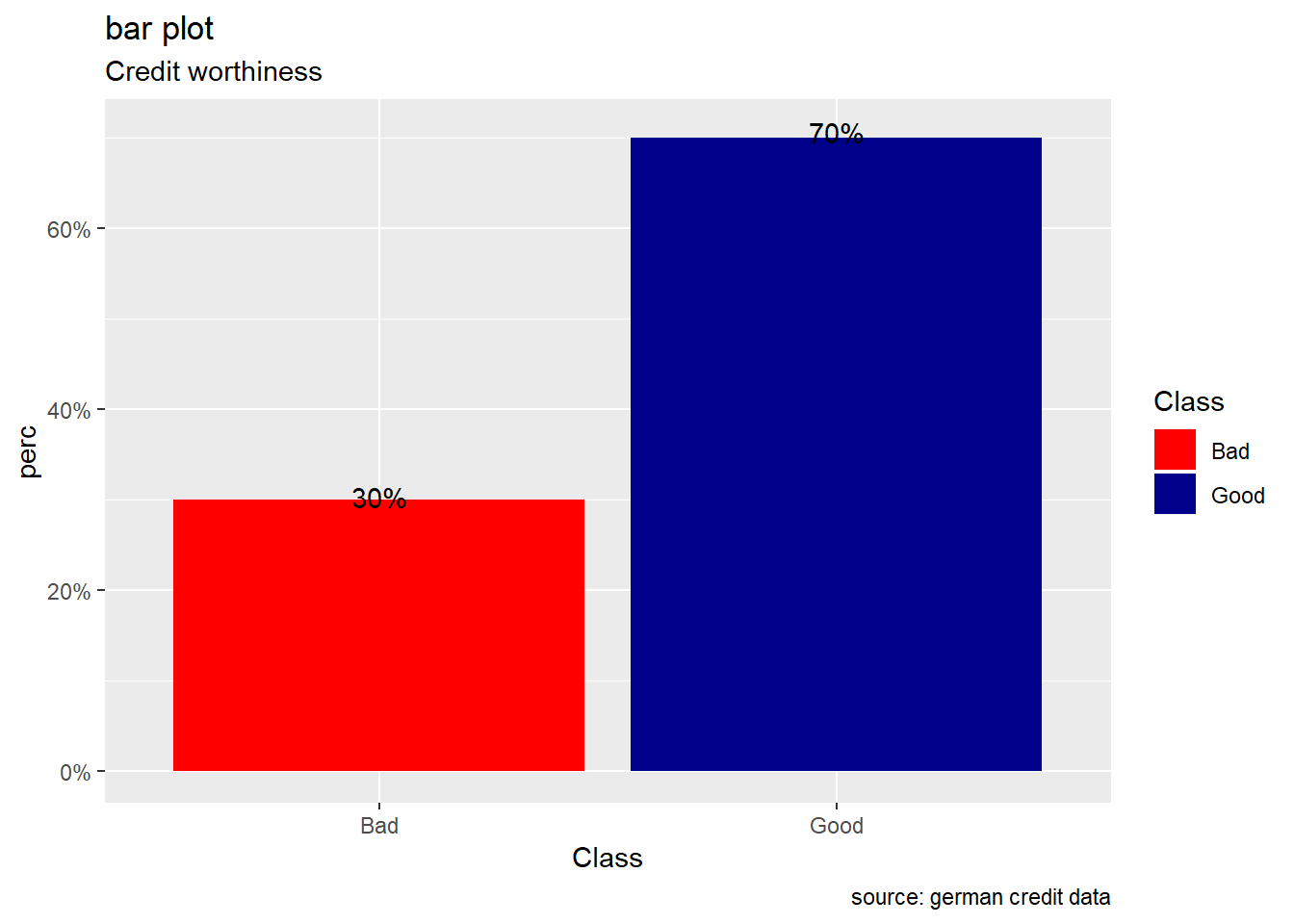
quantitative features.
Data exploration of numerical attributes disclosed the following insights:
Age : From the age variable, we see that the median value for bad risk records is lesser than that of good records, it might be premature to say young people tend to have bad credit records, but we can safely assume it tends to be riskier.
Duration, Amount : Duration in months as well as credit Amount , appears to show higher median value for bad risk with respect to good risk. Also, the range of these two variables, are more wide for the bad risk records than the good ones. When plotting their density curve along the vertical line for their mean value, we observe that neither Duration in months nor Amount credit is normally distributed. Data tends to show a right skewed distribution especially for the Amount credit variable.
InstallmentRatePercentage : The bar plot of installment rate shows a significant difference between good and bad credits risk . The number of good records seem to be the double of bad records. When we look at the Box plot, it reveals that the median value for bad records is higher than the good ones even if the two Classes appear to have the same range.
NumberExistingCredits, ResidenceDuration, NumberPeopleMaintenance : we almost bring up a similar observation for these attributes. While they have their two credit worthiness class “good/bad” which seem to show the same range( cf. boxplot) , good records are always higher than the bad ones(cf bar plot). When we compare some of descriptive statistics of two risks for each of these variable, we observe how mean, median, and sd are almost equal.
client’s Age
ggplot(melt(german[,c(5,21)]), aes(x = variable, y = value, fill = Class)) +
geom_boxplot() +
xlab("Class") +
ylab("Age") +
labs(title="Box plot", subtitle="client's age grouped by credit worthiness", caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))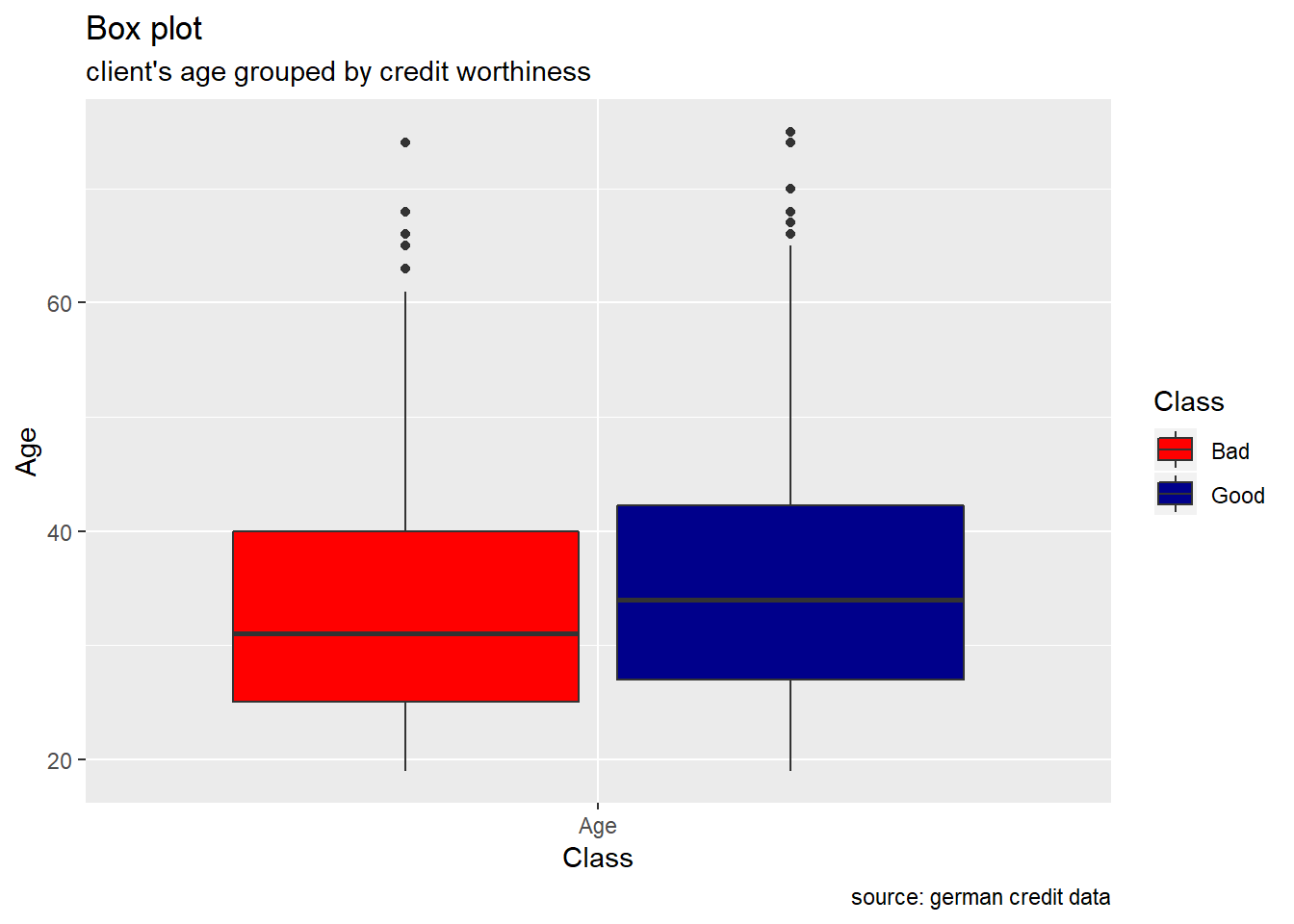
Duration in months
avg.duration <- german %>%
select(Duration, Class) %>%
group_by(Class) %>%
summarise(m=mean(Duration))
german%>%
ggplot(aes(Duration))+
geom_density(aes(fill=Class),alpha=0.7) +
geom_vline(data=avg.duration,aes(xintercept= m , colour= Class), lty = 4 ,size=2)+
labs(title="Density plot",
subtitle="Duration in months grouped by credit worthiness",
caption="Source: german credit data",
x="Duration",
fill="Class") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))
ggplot(reshape2::melt(german[,c(1,21)]), aes(x = variable, y = value, fill = Class)) +
geom_boxplot() +
xlab("Class") +
ylab("Duration") +
labs(title="Box plot", subtitle="Duration in months grouped by credit worthiness", caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))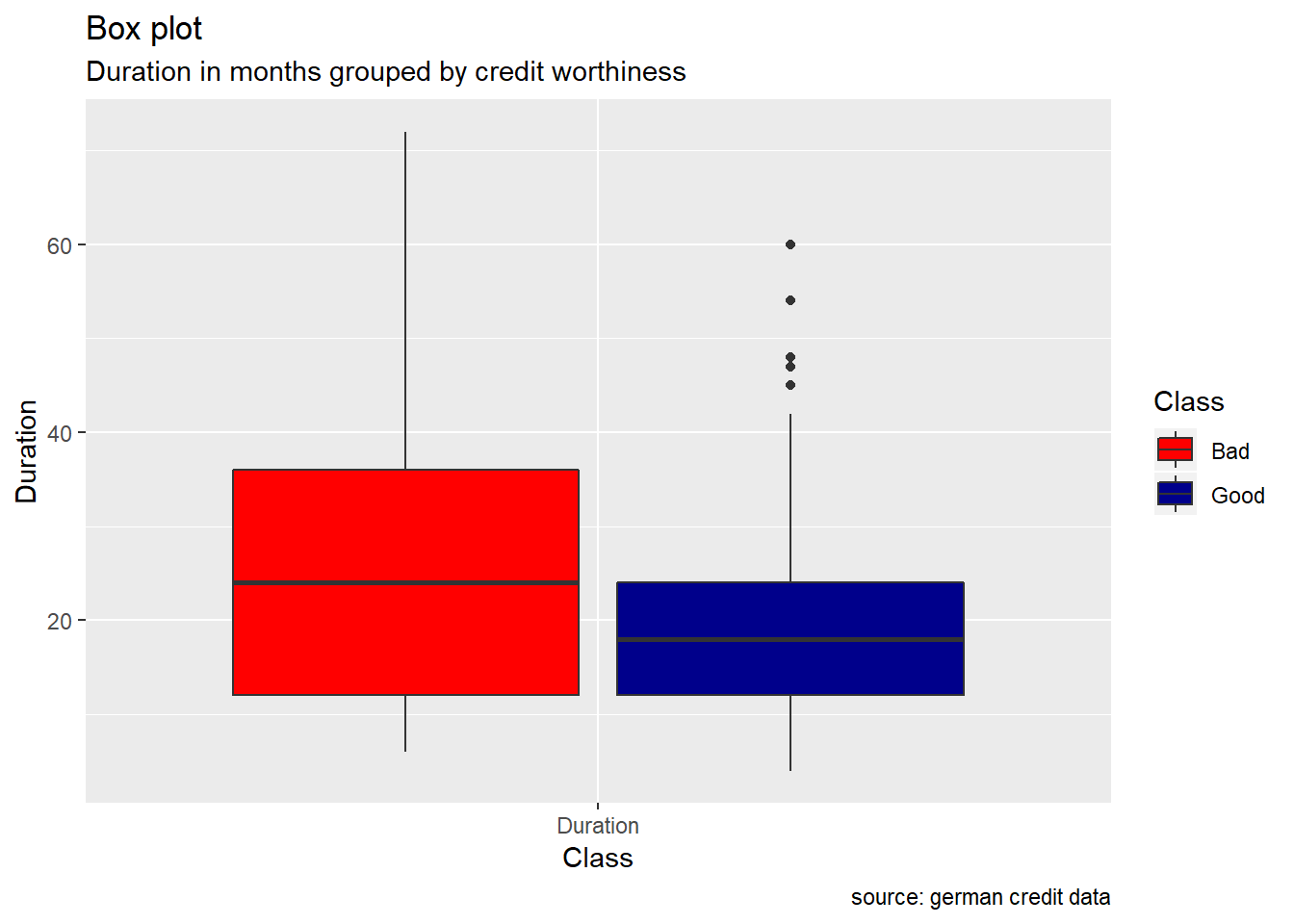
credit Amount
avg.amount <- german %>%
select(Amount, Class) %>%
group_by(Class) %>%
summarise(m=mean(Amount))
german%>%
ggplot(aes(Amount))+
geom_density(aes(fill=Class),alpha=0.7) +
geom_vline(data=avg.amount,aes(xintercept= m , colour= Class), lty = 4 ,size=2)+
labs(title="Density plot",
subtitle="credit amount grouped by credit worthiness",
caption="Source: german credit data",
x="Amount",
fill="Class") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))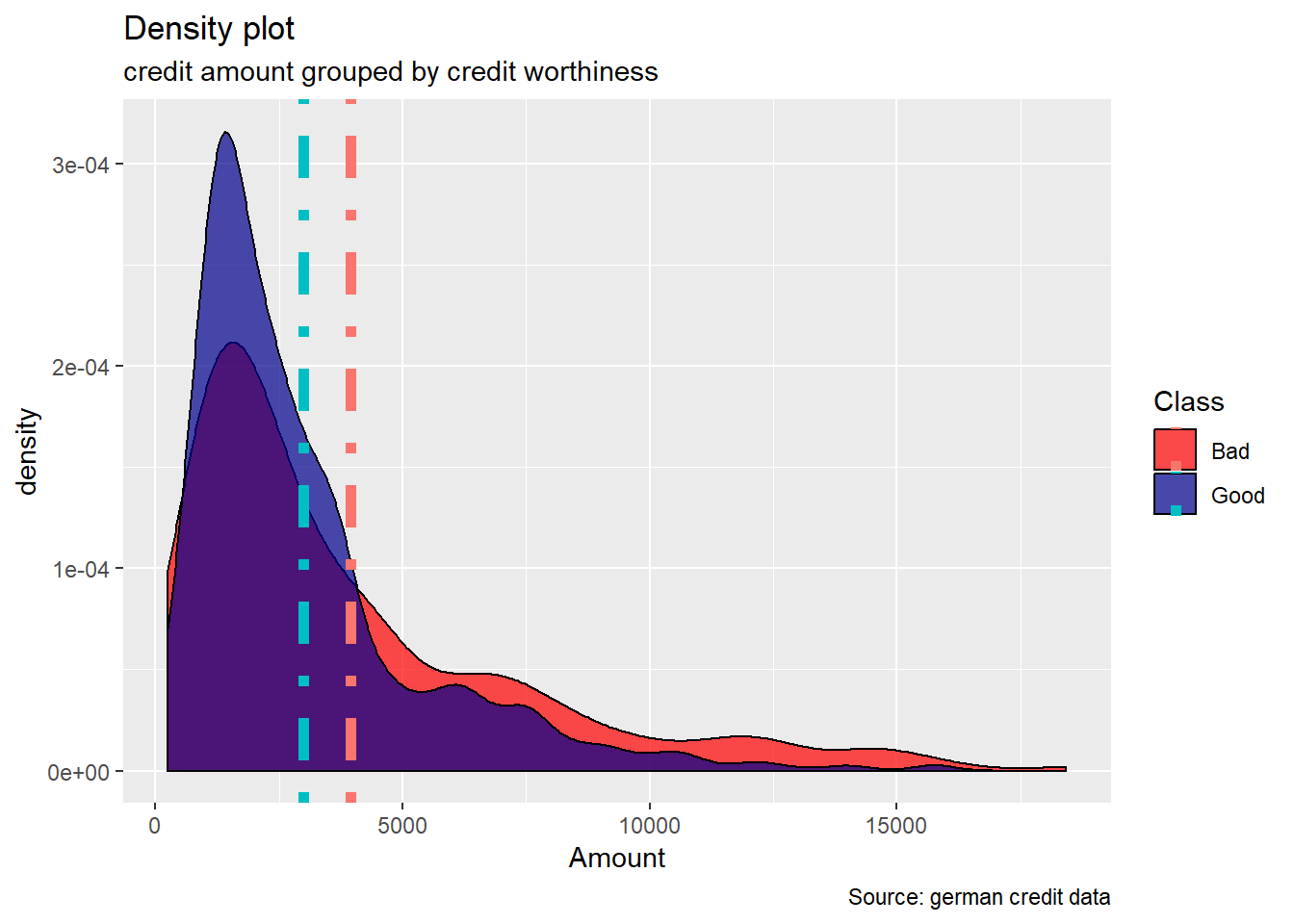
ggplot(reshape2::melt(german[,c(2,21)]), aes(x = variable, y = value, fill = Class)) +
geom_boxplot() +
xlab("Class") +
ylab("Amount") +
labs(title="Box plot", subtitle="credit amount grouped by credit worthiness", caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))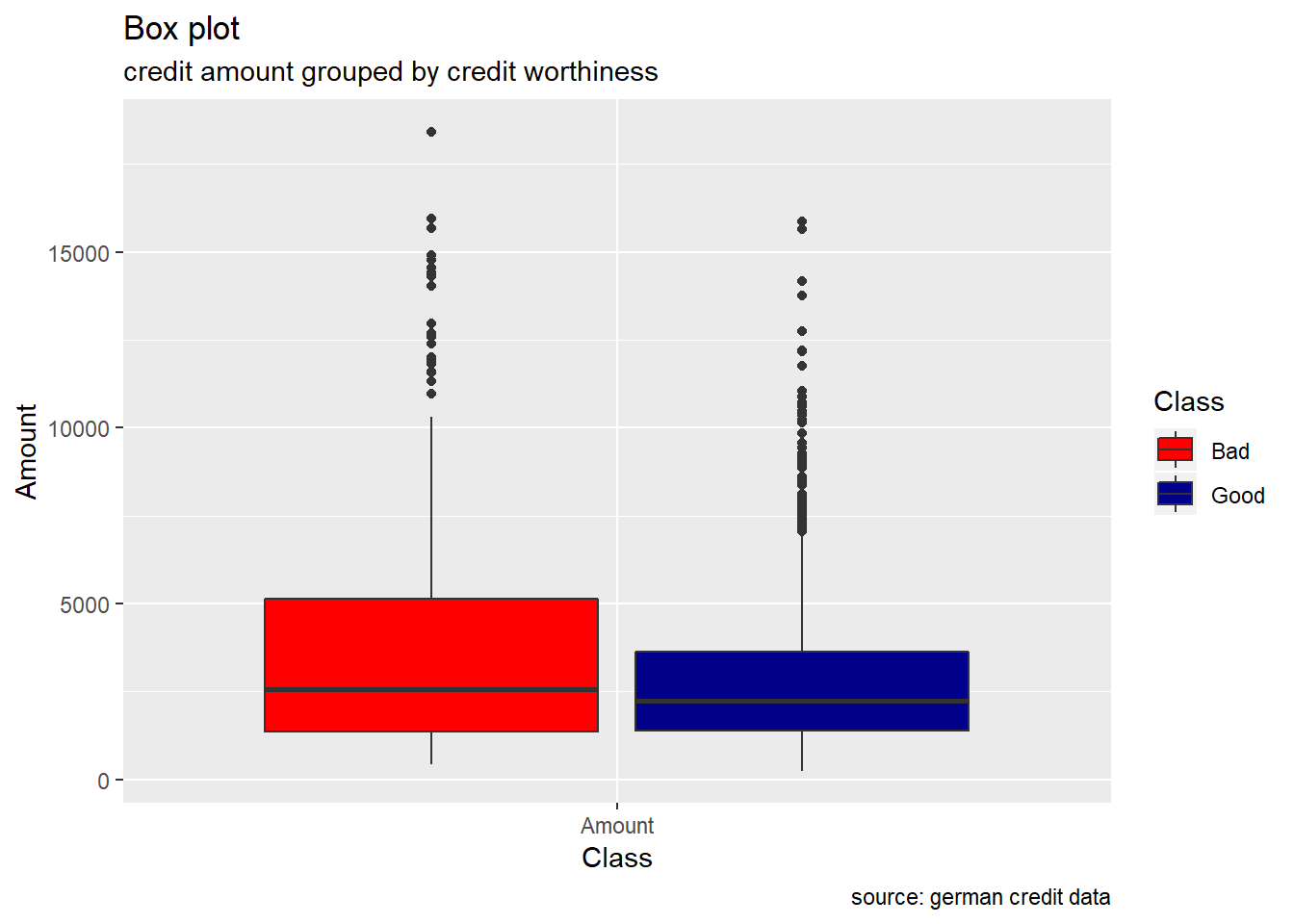
Installment rate
german %>%
ggplot(aes(InstallmentRatePercentage, ..count..)) +
geom_bar(aes(fill=Class), position ="dodge")+
labs(title="bar plot", subtitle="InstallmentRatePercentage grouped by credit worthiness", caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))
ggplot(reshape2::melt(german[,c(3,21)]), aes(x = variable, y = value, fill = Class)) +
geom_boxplot() +
xlab("Class") +
ylab("Install_rate_perc") +
labs(title="Box plot", subtitle="InstallmentRatePercentage grouped by credit worthiness", caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))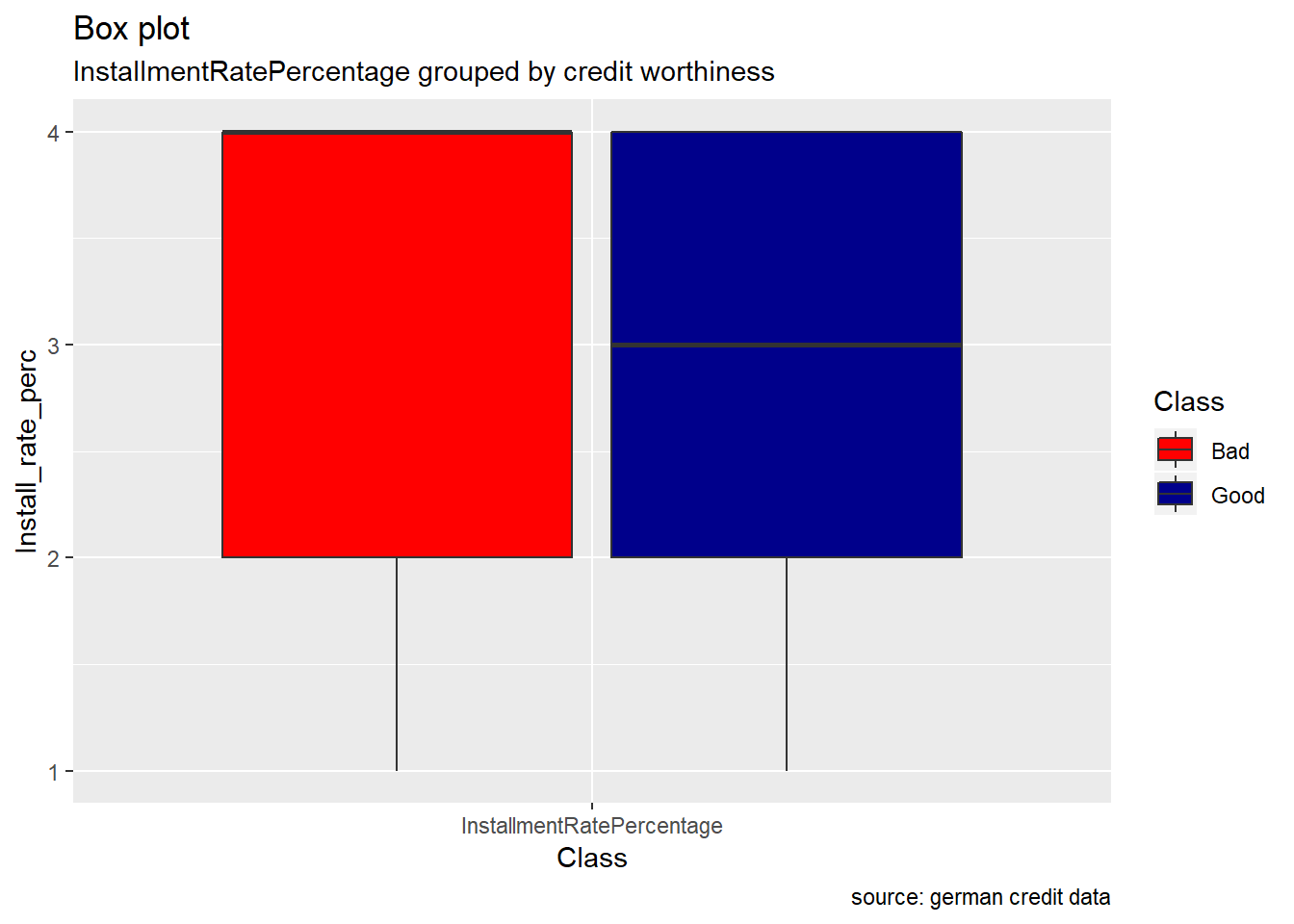
NumberExistingCredits
# we just report here barplot/boxplot for the attribute NumberExistingCredits,
# but we show descriptive statistics including also NumberPeopleMaintenance and #ResidenceDuration. To produce their barplot and boxplot , just repeat the code below and replace with their variable name.
german %>%
ggplot(aes(NumberExistingCredits, ..count..)) +
geom_bar(aes(fill=Class), position ="dodge")+
labs(title="bar plot", subtitle="Number of existing credits grouped by credit worthiness", caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))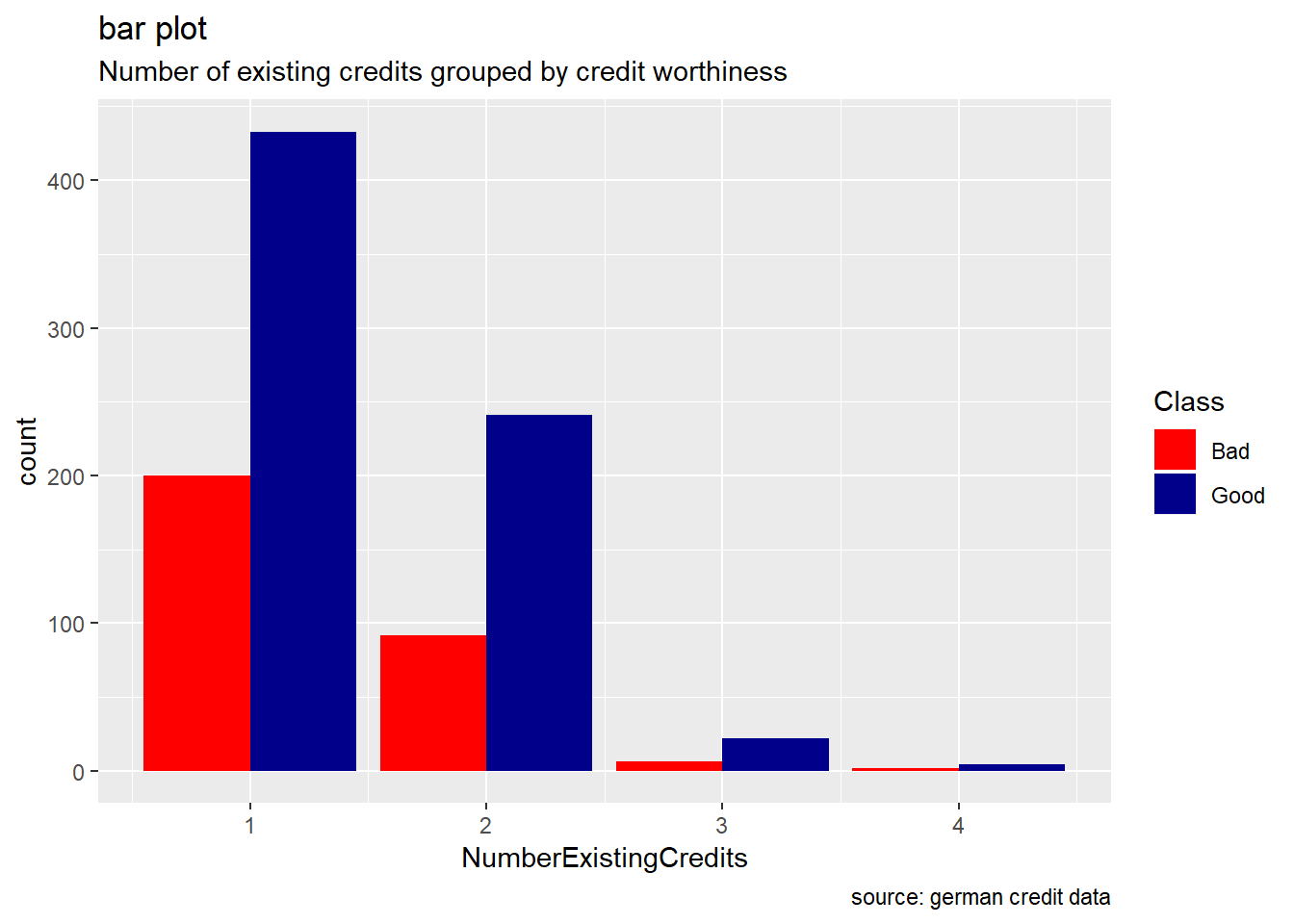
ggplot(reshape2::melt(german[,c(6,21)]), aes(x = variable, y = value, fill = Class)) +
geom_boxplot() +
xlab("Class") +
ylab("n_credits") +
labs(title="Box plot", subtitle="Number of existing credits grouped by credit worthiness", caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))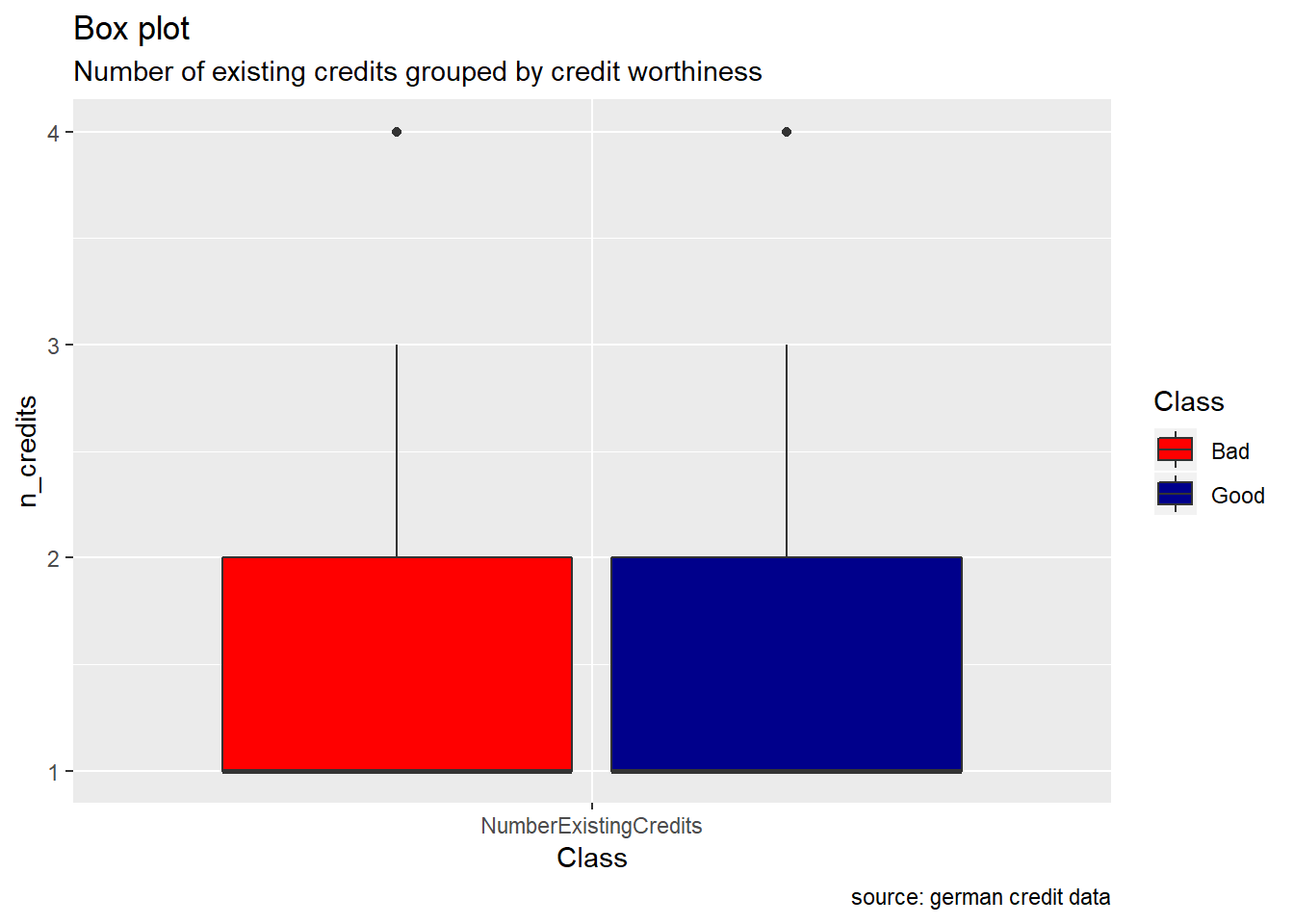
# Compare mean, median and sd of two Class for each of these attributes
german%>% group_by(Class) %>%
summarize(ncredits.mean=mean(NumberExistingCredits),
ncredits.median=median(NumberExistingCredits),
ncredits.sd = sd(NumberExistingCredits))# A tibble: 2 x 4
Class ncredits.mean ncredits.median ncredits.sd
<fct> <dbl> <dbl> <dbl>
1 Bad 1.37 1 0.560
2 Good 1.42 1 0.585german%>% group_by(Class) %>%
summarize(resid_dur.mean=mean(ResidenceDuration),
resid_dur.median=median(ResidenceDuration),
resid_dur.sd = sd(ResidenceDuration))# A tibble: 2 x 4
Class resid_dur.mean resid_dur.median resid_dur.sd
<fct> <dbl> <dbl> <dbl>
1 Bad 2.85 3 1.09
2 Good 2.84 3 1.11german%>% group_by(Class) %>%
summarize(people_maint.mean=mean(NumberPeopleMaintenance),
people_maint.median=median(NumberPeopleMaintenance),
people_maint.sd = sd(NumberPeopleMaintenance))# A tibble: 2 x 4
Class people_maint.mean people_maint.median people_maint.sd
<fct> <dbl> <dbl> <dbl>
1 Bad 1.15 1 0.361
2 Good 1.16 1 0.363
In the following DT table, we can interactively visualize all numerical attributes and our response variable, credit worthiness (Class) . We can search / filter any keywords or specific entries for each variable.
# i create a dataframe "get_num" which contains all numerical attributes plus the response variable. Then, with the function datatable of DT library , i create HTML widget to display get_num.
get_num <- select_if(german, is.numeric)
get_num <- get_num %>%
mutate(Class = german$Class)
DT::datatable(get_num,rownames = FALSE, filter ="top", options =list(pageLength=10,scrollx=T))
qualitative features.
Data exploration of categorical attributes disclosed the following insights:
CheckingAccountStatus : the current status of the checking account matters as the frequency of the response variables is seen to differ from one sub category to another. Accounts with less than 0 DM houses more number of bad credit risk records while accounts with more than 200 DM the least.we see how applicants with no checking account house the highest number of good records. ( NB: DM -> Deutsche Mark)
CreditHistory: Generally, credit history’s levels tend to show a higher number of good credit risk than bad credit risk. We observe that proportion of the response variable ,the credit worthiness, changes varies significantly. For categories “NoCredit.AllPaid” and “ThisBank.AllPaid”, we see how the number of bad credit records are greater.
Purpose: For the purpose variable, we observe that the proportion of good and bad credit risk varies significantly across the different credit’s purposes. While the majority of categories show number of good risk records always greater than the bad ones, the categories as DomesticAppliance ,Education , Repairs and others seem to include more risky records. ( the difference between the number of bad and good records is really minimal) (see histogram and ballon plot)
Generally, for the other categorical attributes, we observe a similar trend for which good creditworthiness records are greater than bad ones. Variables like SavingAccountBonds, EmploymentDuration, Personal, ForeignWorker, Housing, Property, or Telephone straightly follow that observation. However, the trend looks more significant for the attributes SavingAccountBonds, telephone,foreign workers, or also EmploymentDuration. Instead, the two features OtherInstallmentPlans and OtherDebtorsGuarantors show more risky records. (see on barplot levels Coapplicant or Guarantor for OtherDebtors , and Stores or Bank for OtherInstall)
CheckingAccountStatus
ggplot(german, aes(CheckingAccountStatus, ..count..)) +
geom_bar(aes(fill = Class), position = "dodge") +
labs(title="bar plot", subtitle="AccountStatus grouped by credit worthiness", caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))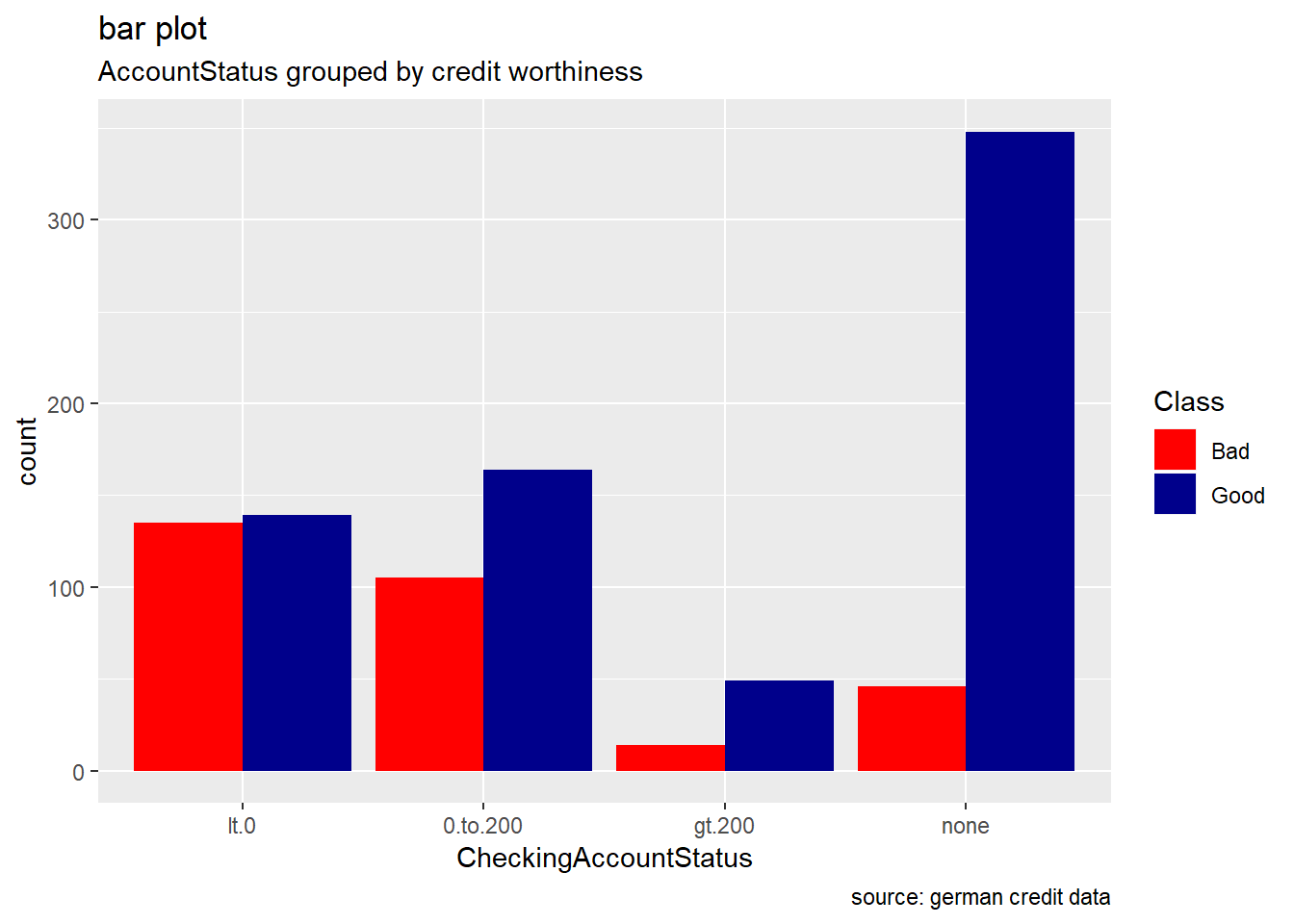
CreditHistory
german %>%
ggplot(aes(CreditHistory, ..count..)) +
geom_bar(aes(fill=Class), position ="dodge") +
labs(title="bar plot", subtitle="Credit history grouped by credit worthiness", caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))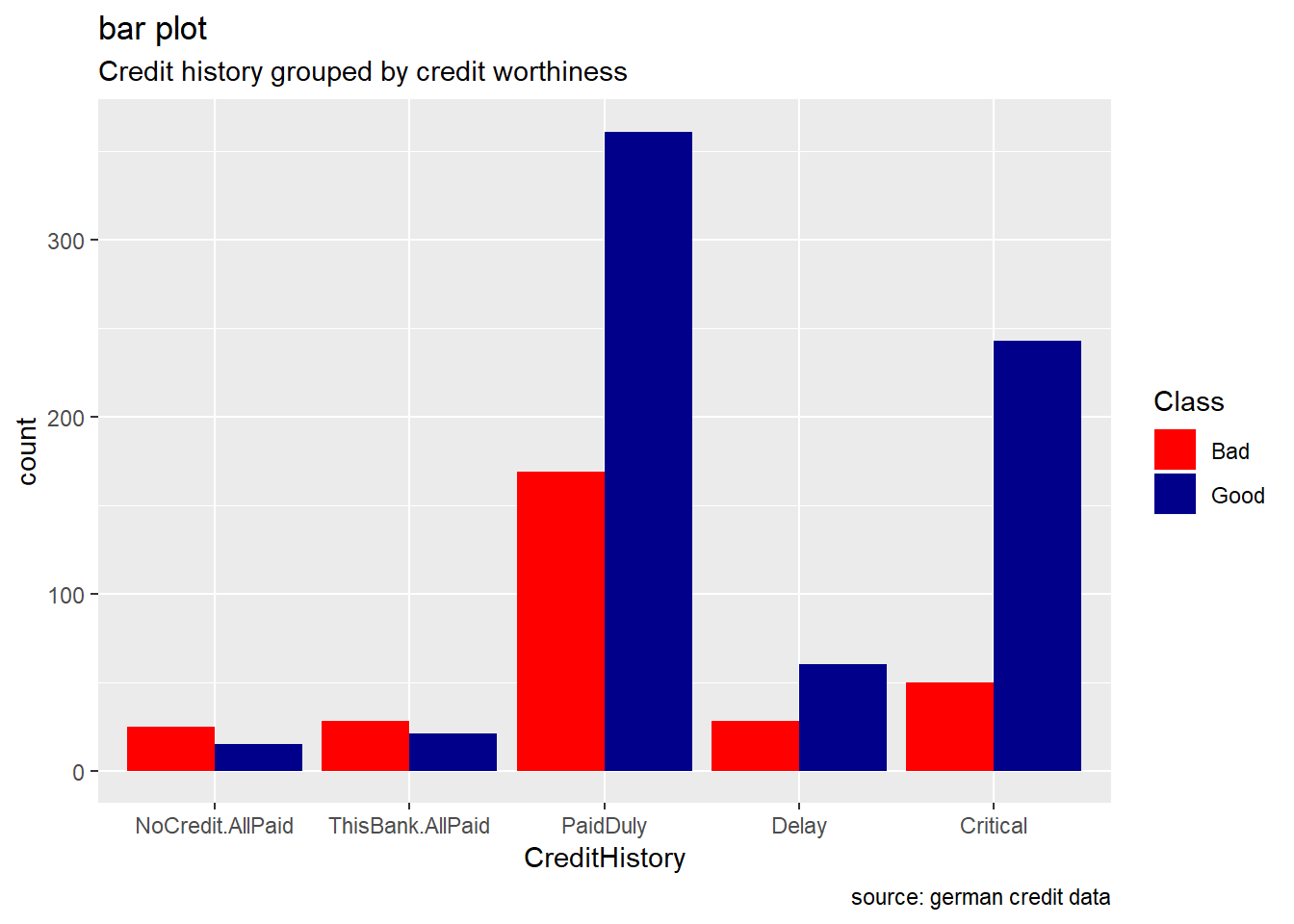
Purpose
german %>%
ggplot(aes(Purpose)) +
geom_bar(aes(fill=Class), width = 0.5) +
theme(axis.text.x = element_text(angle=65, vjust=0.6)) +
labs(title="Histogram",
subtitle="credit purpose across credit worthiness",
caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))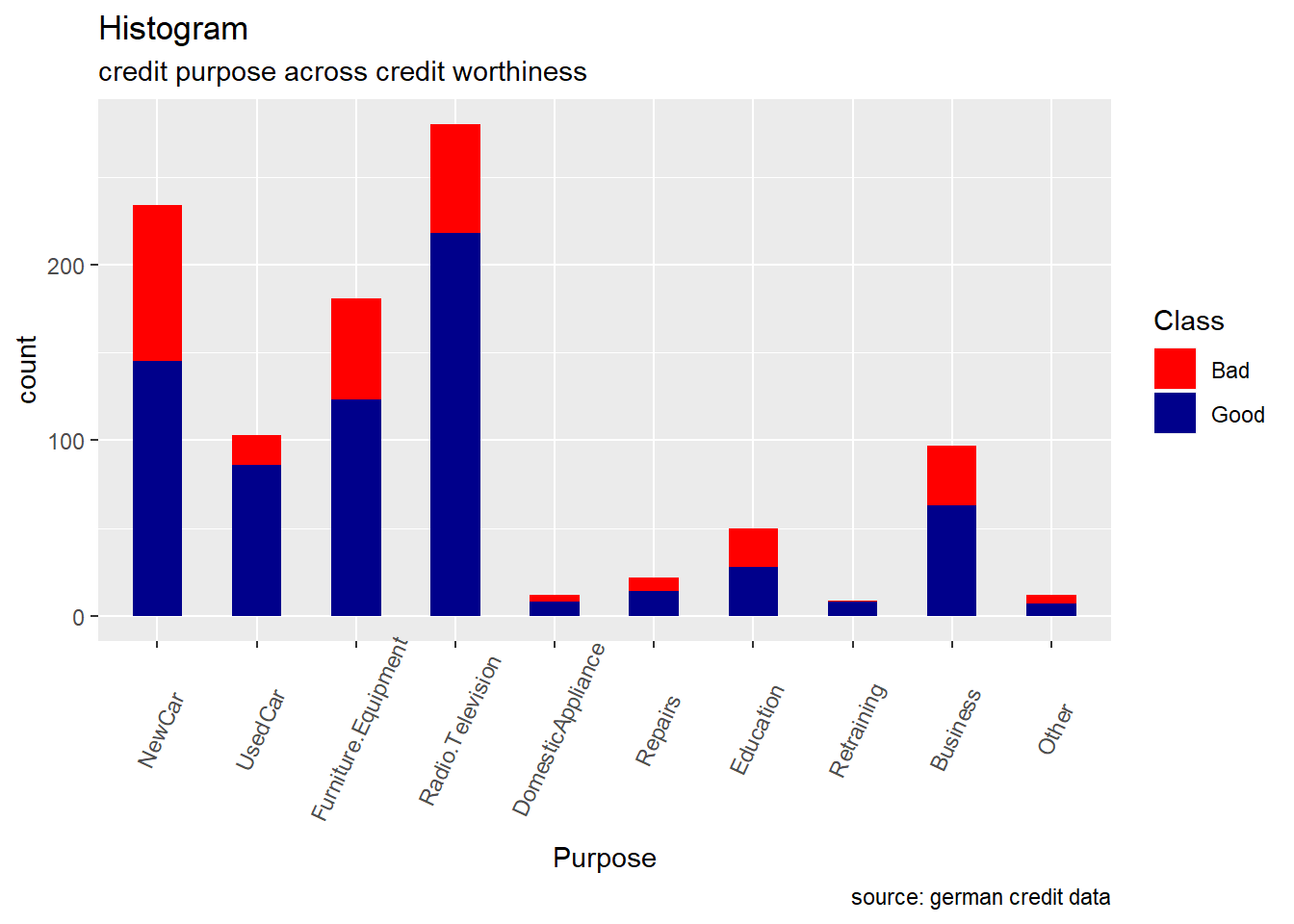
purp <- table(german$Purpose,german$Class)
ggballoonplot(as.data.frame(purp), fill = "value",title="Ballon plot",
subtitle="credit purpose across credit worthiness",
caption = "source: german credit data")+
scale_fill_viridis_c(option = "C") 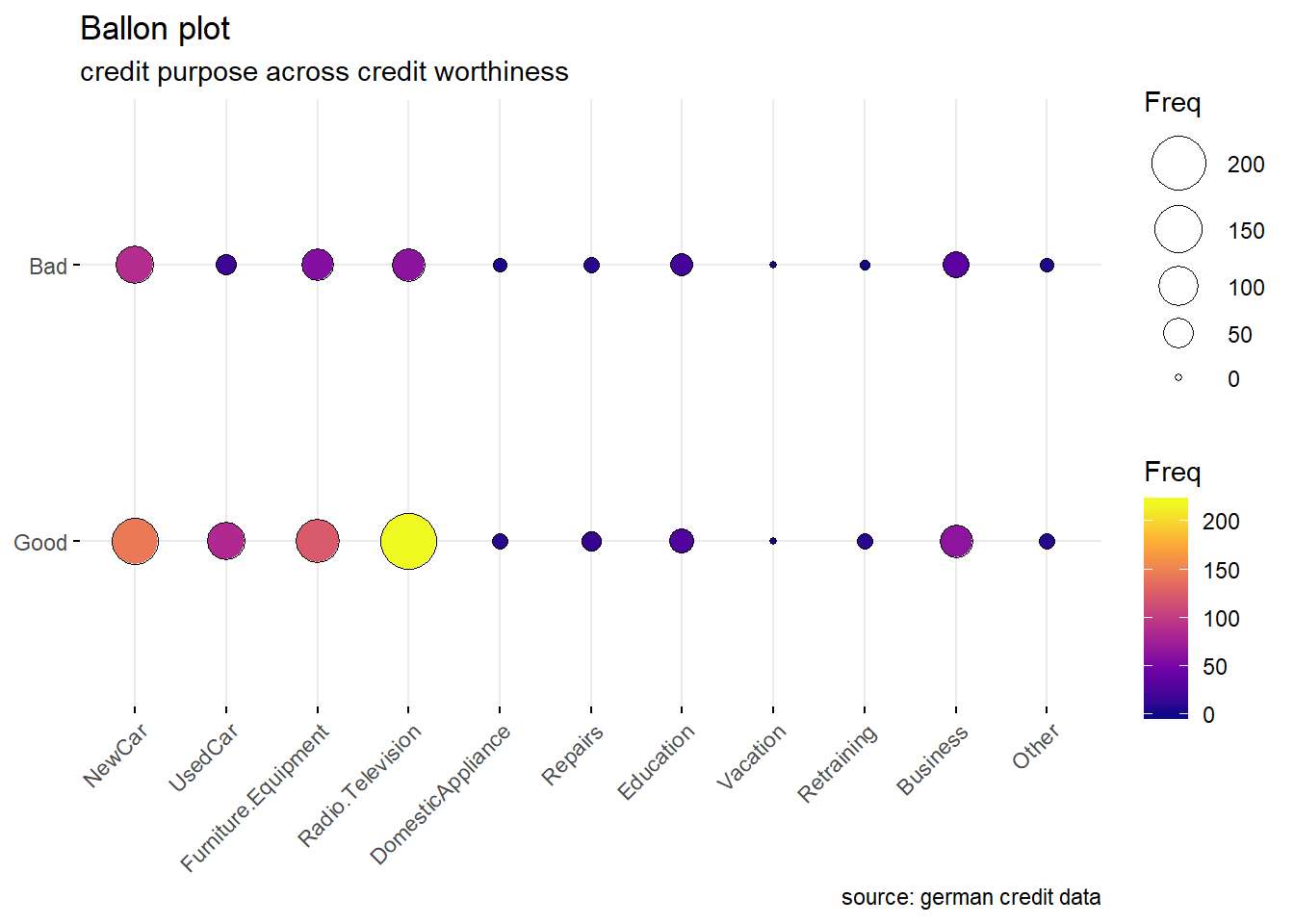
SavingsAccountBonds
german %>%
ggplot(aes(SavingsAccountBonds, ..count..)) +
geom_bar(aes(fill=Class), position ="dodge") +
labs(title="bar plot", subtitle="Saving accounts grouped by credit worthiness", caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))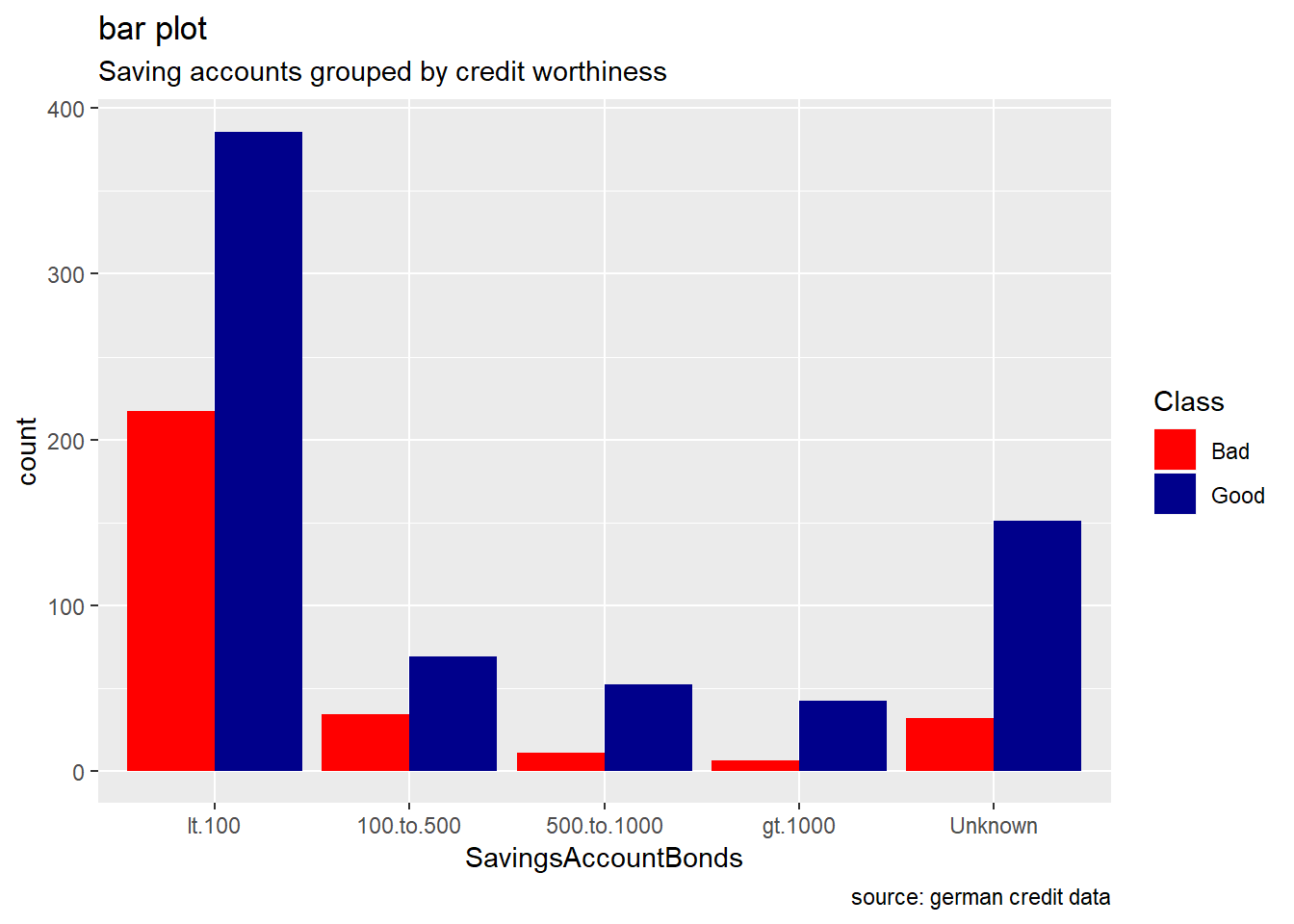
EmploymentDuration
german %>%
ggplot(aes(EmploymentDuration, ..count..)) +
geom_bar(aes(fill=Class), position ="dodge") +
labs(title="bar plot", subtitle="Employment Duration grouped by credit worthiness", caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))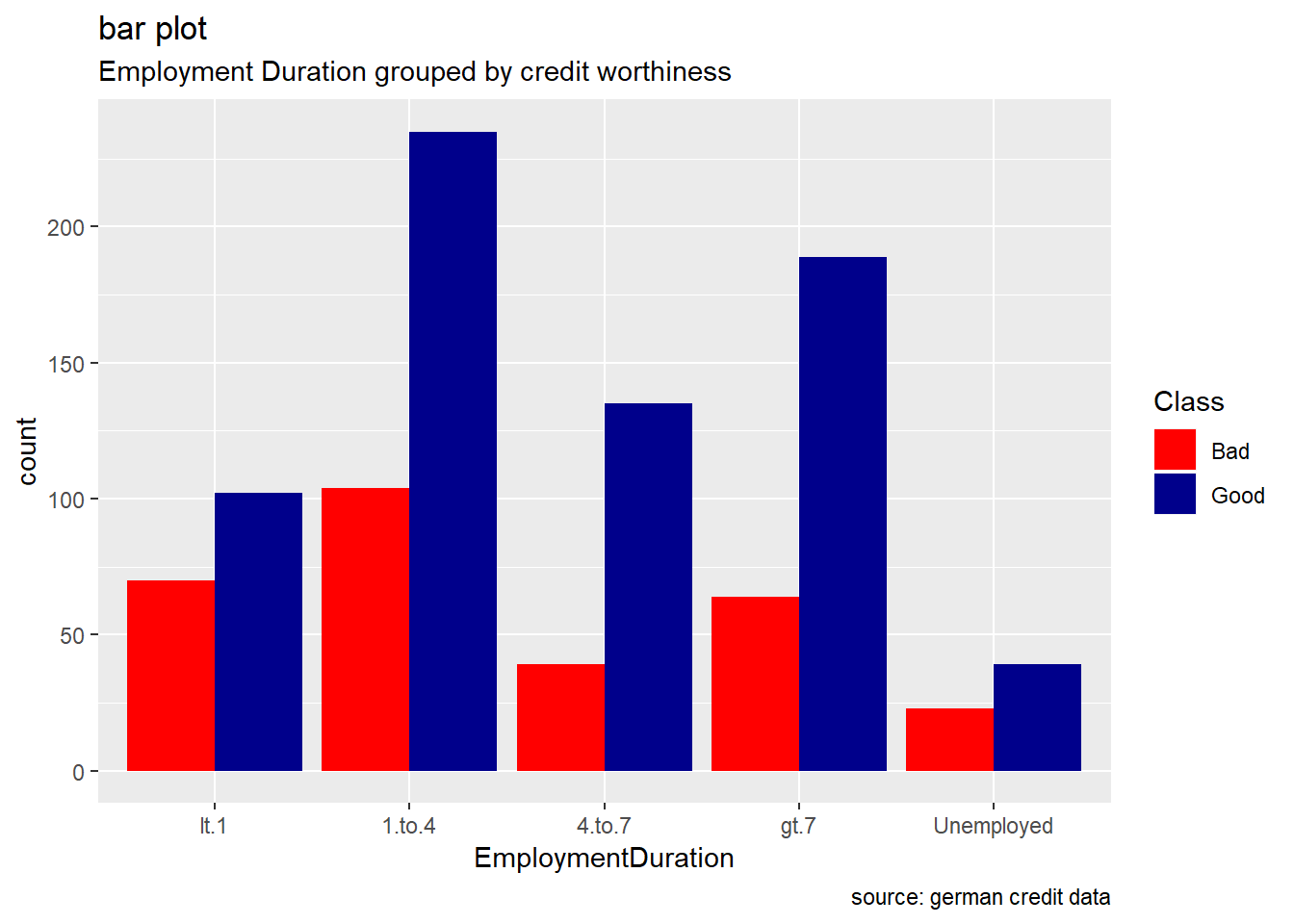
ForeignWorker
german %>%
ggplot(aes(ForeignWorker, ..count..)) +
geom_bar(aes(fill=Class), position ="dodge") +
labs(title="bar plot", subtitle="Foreignworker grouped by credit worthiness", caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))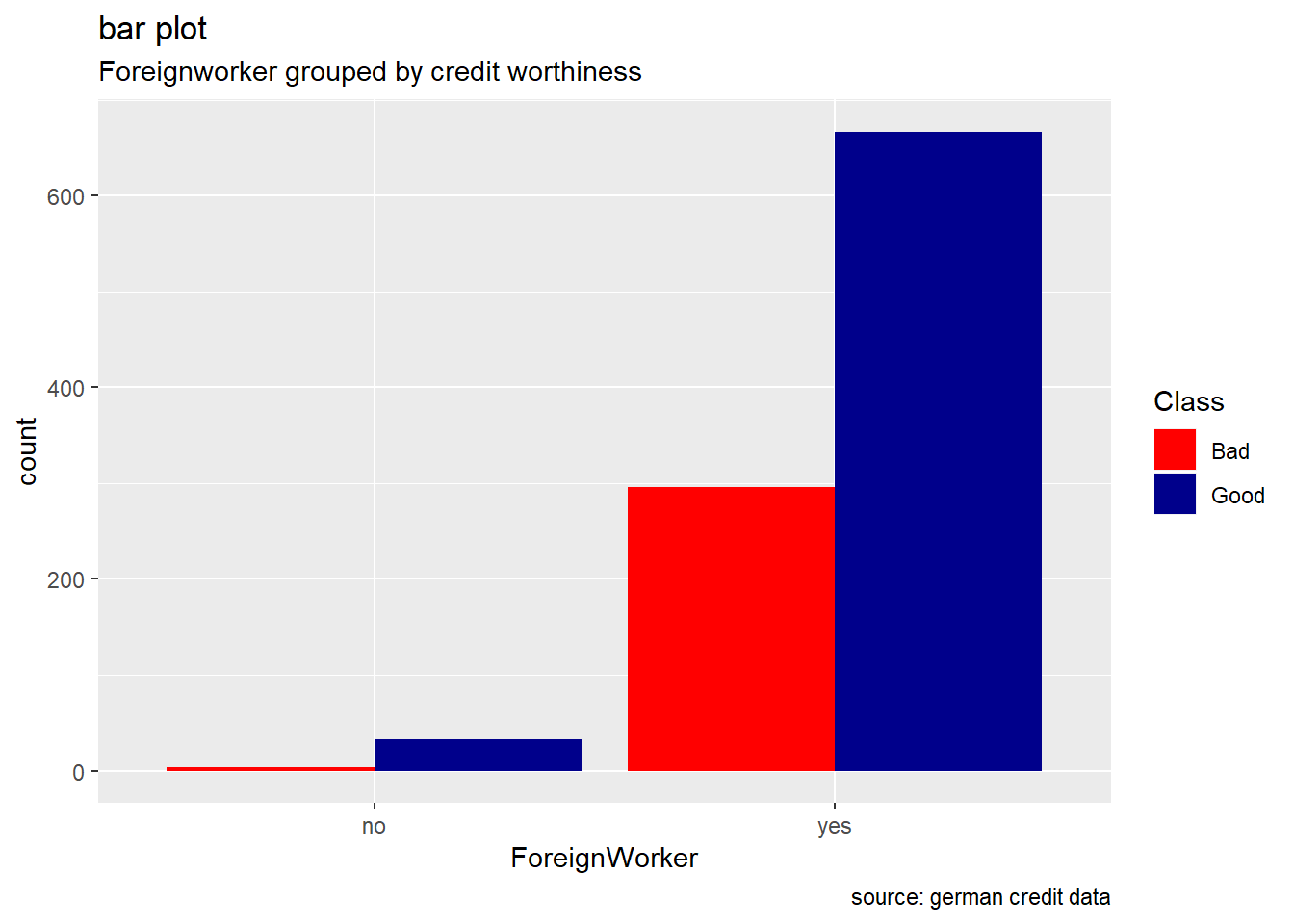
Telephone
german %>%
ggplot(aes(Telephone, ..count..)) +
geom_bar(aes(fill=Class), position ="dodge")+
labs(title="bar plot", subtitle="Telephone grouped by credit worthiness", caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))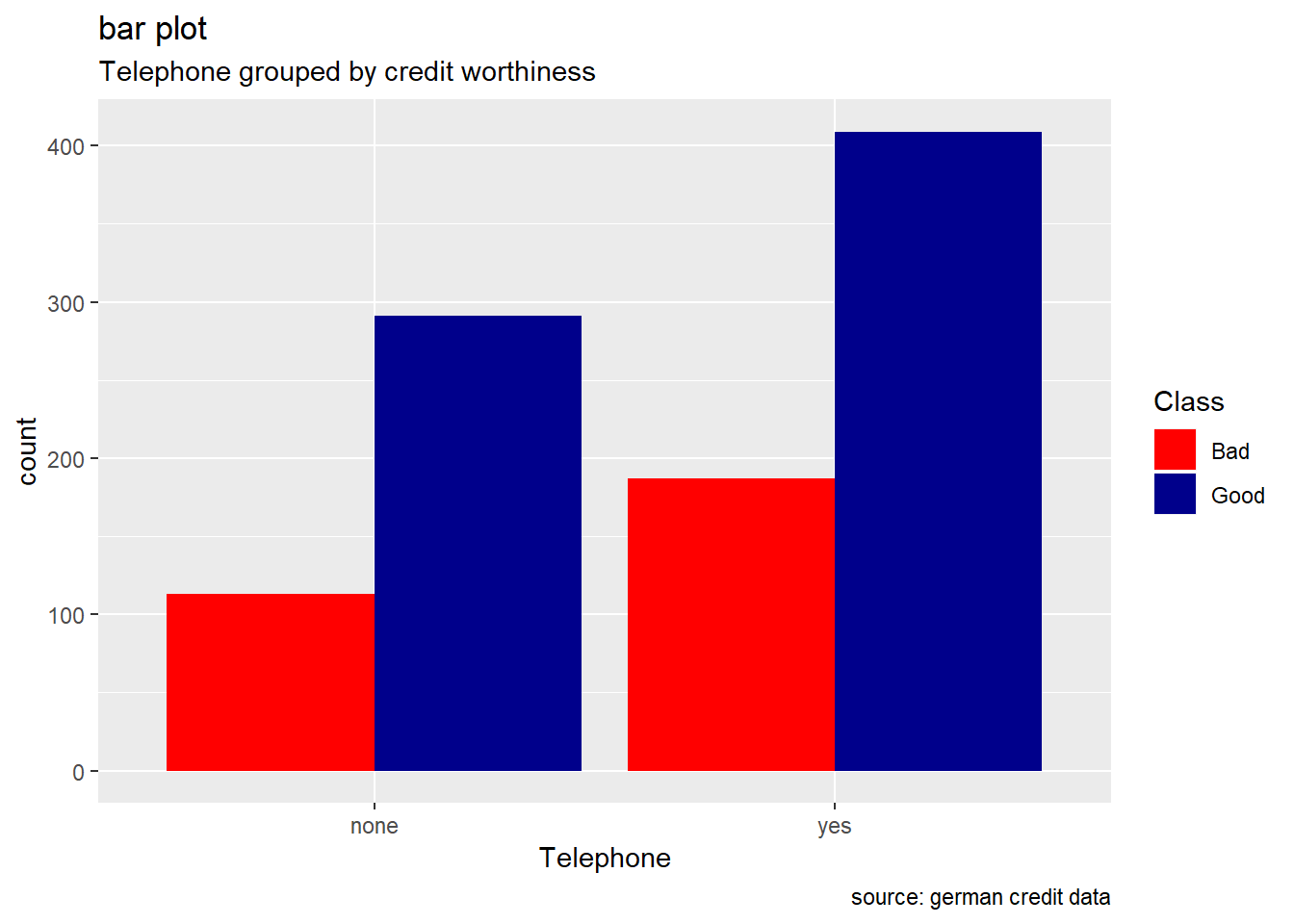
OtherInstallmentPlans
german %>%
ggplot(aes(OtherInstallmentPlans, ..count..)) +
geom_bar(aes(fill=Class), position ="dodge")+
labs(title="bar plot", subtitle="OtherInstallmentPlans grouped by credit worthiness", caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))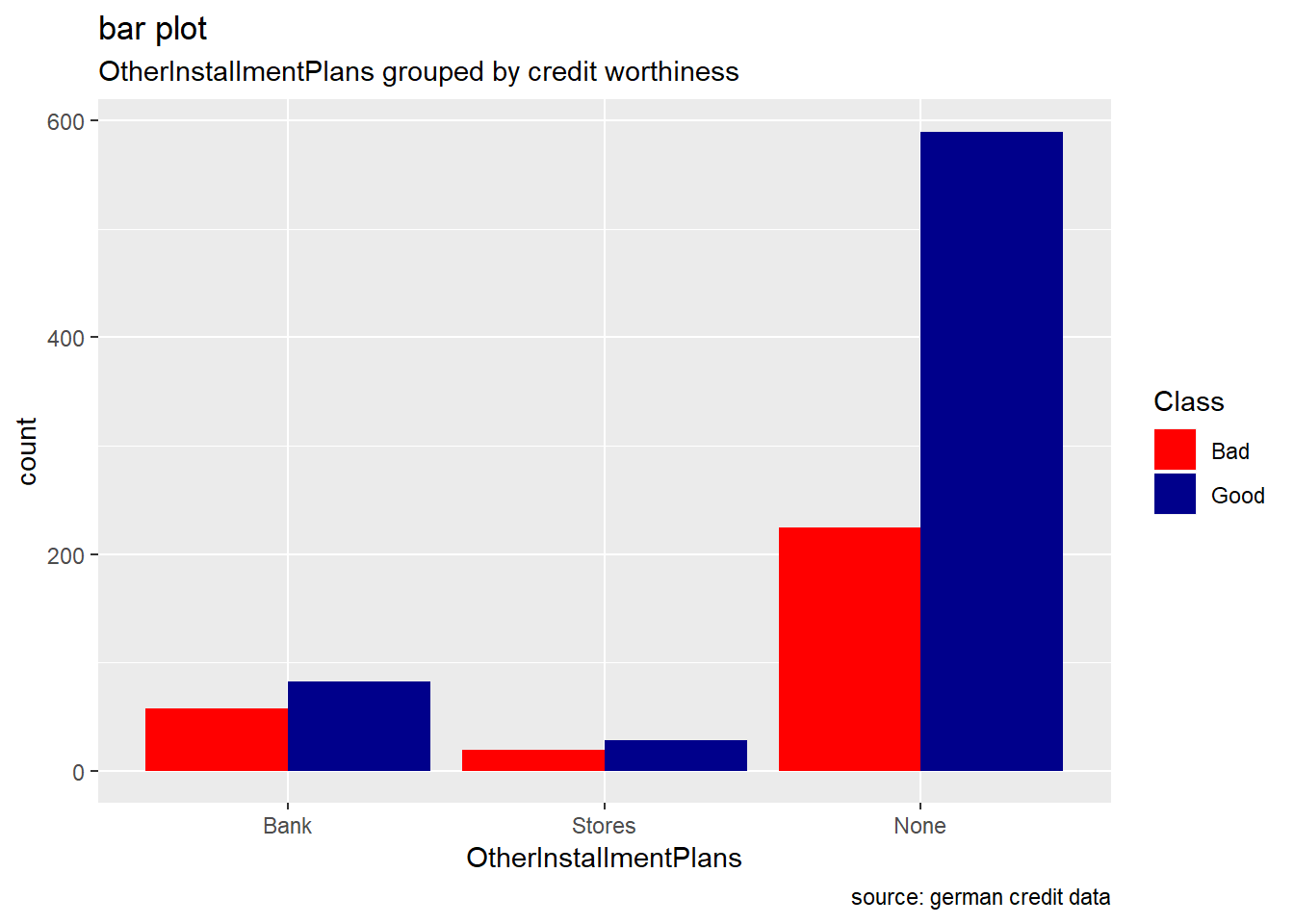
OtherDebtorsGuarantor
german %>%
ggplot(aes(OtherDebtorsGuarantors, ..count..)) +
geom_bar(aes(fill=Class), position ="dodge")+
labs(title="bar plot", subtitle="OtherDebtorsGuarantors grouped by credit worthiness", caption = "source: german credit data") +
scale_fill_manual(values = c("Good" = "darkblue", "Bad" = "red"))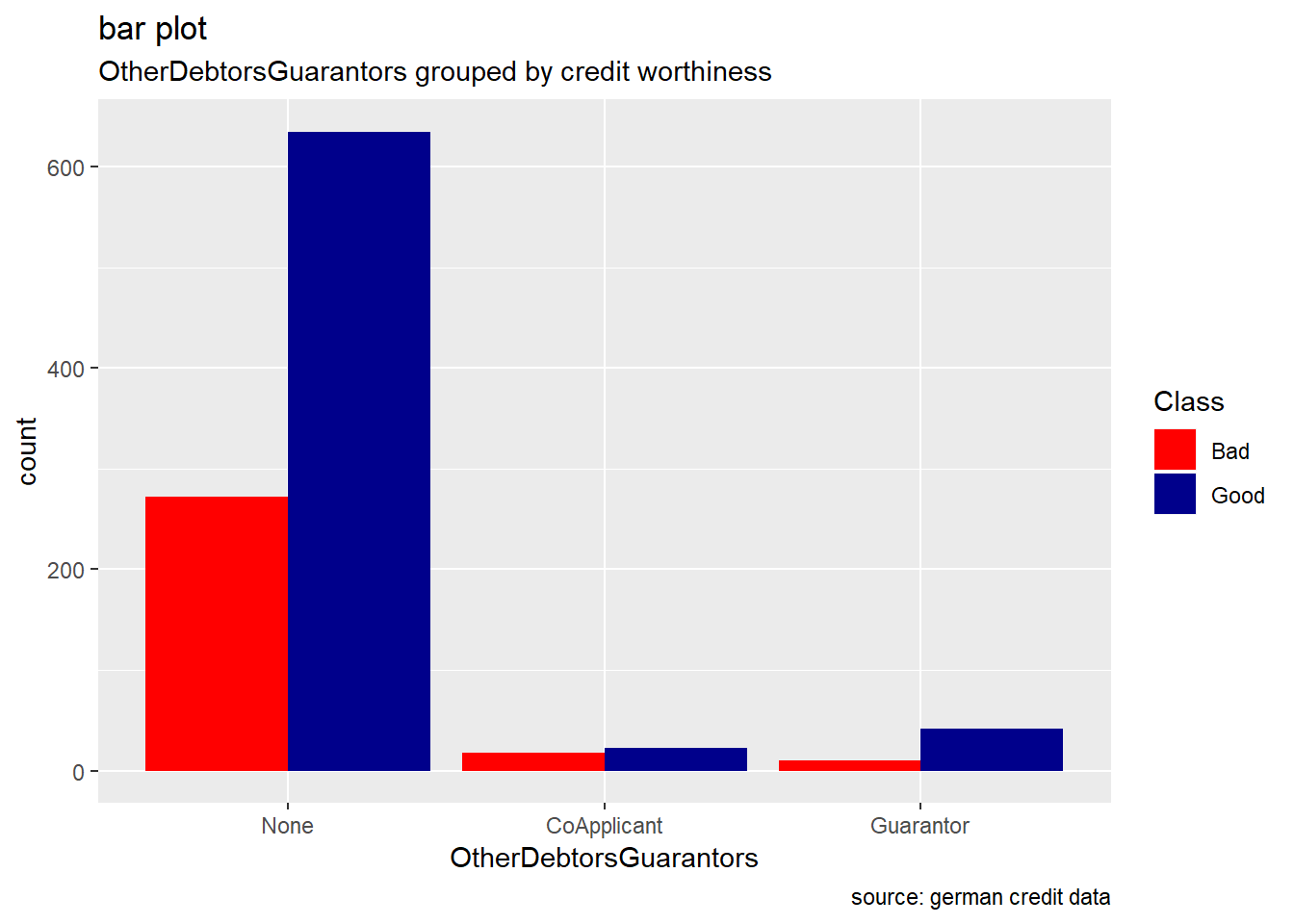
In the following DT table, we can interactively visualize all categorical features and our response variable, credit worthiness (Class) . We can search / filter any keywords or specific entries for each variable.
# i create a dataframe "get_cat" which contains all categorical attributes including the response variable. Then, with the function datatable of DT library , i create HTML widget to display get_num.
get_cat <- select_if(german, is.factor)
DT::datatable(get_cat,rownames = FALSE, filter ="top", options =list(pageLength=10,scrollx=T))
Multivariate analysis.
Relationship between quantitative and qualitative features, it’s performed to understand interactions between different fields in the dataset or finding interactions between variables more than 2 (- ex: pair plot and 3D scatter plot). We performed Multi-panel conditioning focusing on the relationship between Age , Amount credit with respect to Purpose and Personal status/sex (i1 , i2) , we also drew a histogram plot of Amount ~ Age conditioned on Personal status/sex variable (i3).
As in Sivakumar(2015), Multivariate data analysis of the latter revealed the following:
(i1), Age vs credit amount for various purpose : As we can see in the first plot ,most of the loans are sought to buy: new car , furniture/equipment, radio/television. It also reveals that surprisingly few people buying used cars have bad rating! And not surprisingly, lower the age of the lonee and higher loan amount correlates to bad credits.
(i2), Age vs credit Amount for Personal status and sex : Male: the second plot reveals that single males tend to borrow more, and as before, younger they are and higher the loan amount corresponds to a bad rating. Instead, married/widowed or divorced/separated Males have shown the least amount of borrowing. Because of this, its difficult to visually observe any trends in these categories. Female: the first obvious observation for females is the absence of data for single women. Its not sure if its lack of data or there were no single women applying for loans- though the second possibility seems unlikely in real life. The next most borrowing after single males category is Female not single :divorced/separated/married. The dominant trend in this category is smaller loan amount, higher the age, better the credit rating.
(i3), Distribution Amount ~ Age conditioned on Personal status/sex :The histogram reveals that there is a right skewed nearly normal trend seen across all Personal Status and Sex categories, with 30 being the age where people in the sample seem to be borrowing the most.
Age vs credit amount for various purpose
mycol <- c("red","blue")
xyplot(Amount ~ Age|Purpose, german,
grid = TRUE,
group= Class,
auto.key = list(points = TRUE, rectangles = FALSE, title="Class",cex=0.7, space = "right"),
main=list(
label="Age vs credit amount for various purposes\n grouped by credit worthiness",
cex=1),
sub= "source: german credit data",
par.settings = c(simpleTheme(col = mycol),list(par.sub.text = list(cex = 0.7, col = "black",x=0.75))))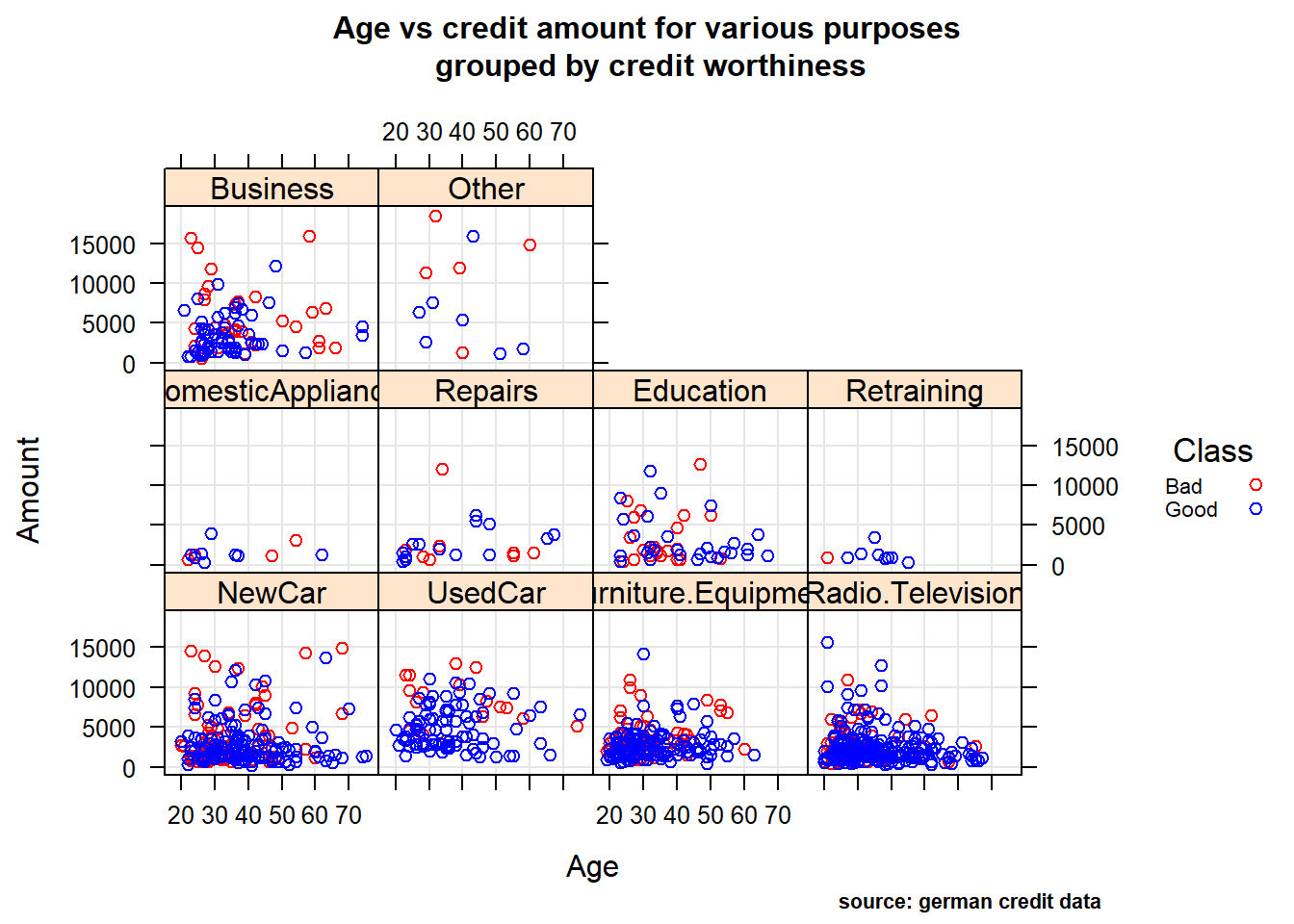
Age vs credit Amount for Personal status and sex
xyplot(Amount ~ Age |Personal , german,
group = Class,
grid = TRUE,
auto.key = list(points = TRUE, rectangles = FALSE, title="Class",cex=0.7, space = "right"),
main=list(
label="Age vs credit amount for Personal status and sex\n grouped by credit worthiness",
cex=1),
#sub= "source: german credit data"),
sub= "source: german credit data",
par.settings = c(simpleTheme(col = mycol),list(par.sub.text = list(cex = 0.7, col = "black",x=0.75))))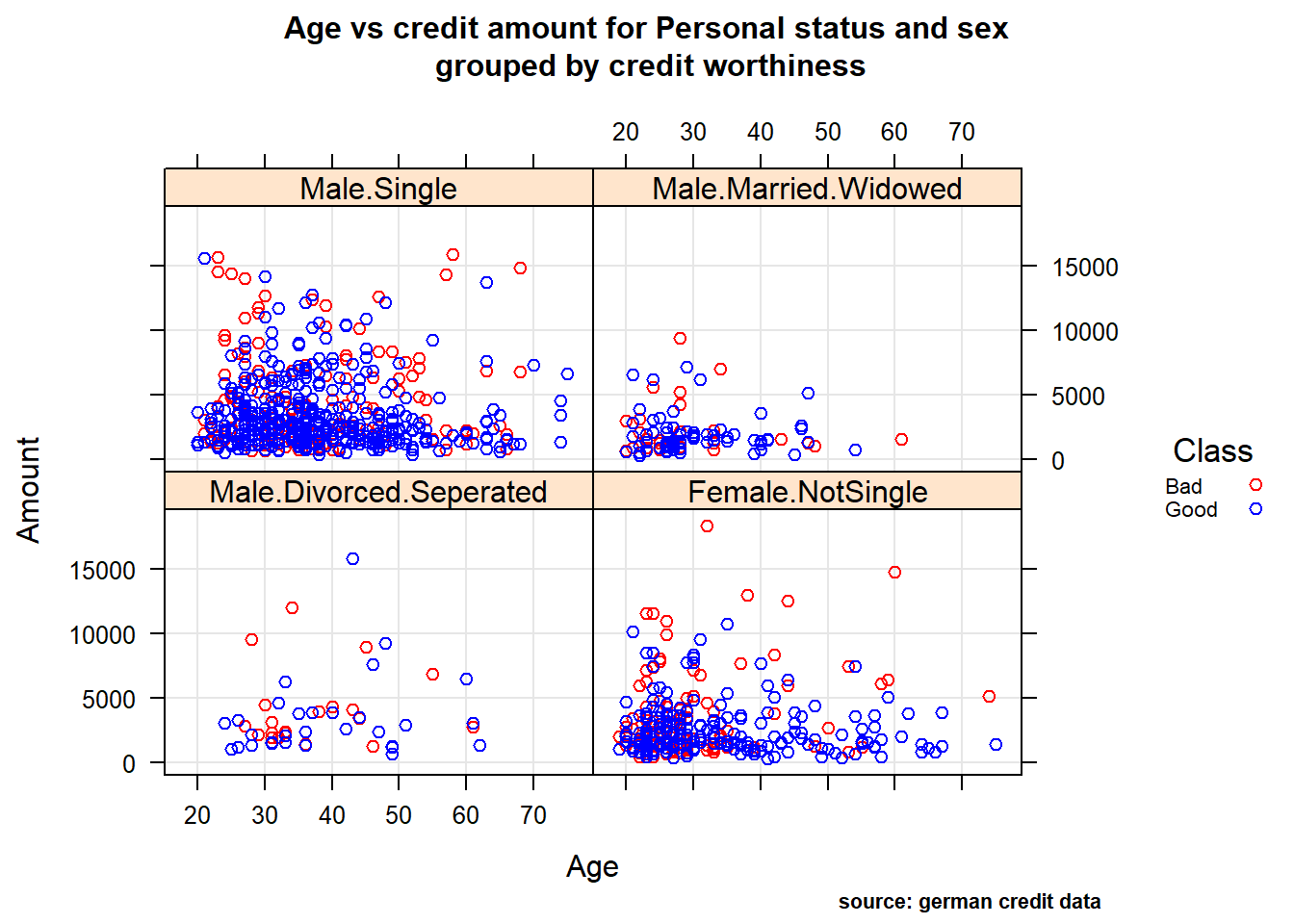
Distribution Amount ~ Age conditioned on Personal status/sex
histogram(Amount ~ Age | Personal,
data = german,
xlab = "Age",
ylab= "Amount",
main= list( label="Distribution of Age and Personal status & sex", cex=1),
col="purple",
sub= "source: german credit data",
par.settings=list(par.sub.text = list(cex = 0.7, col = "black", x=0.75)))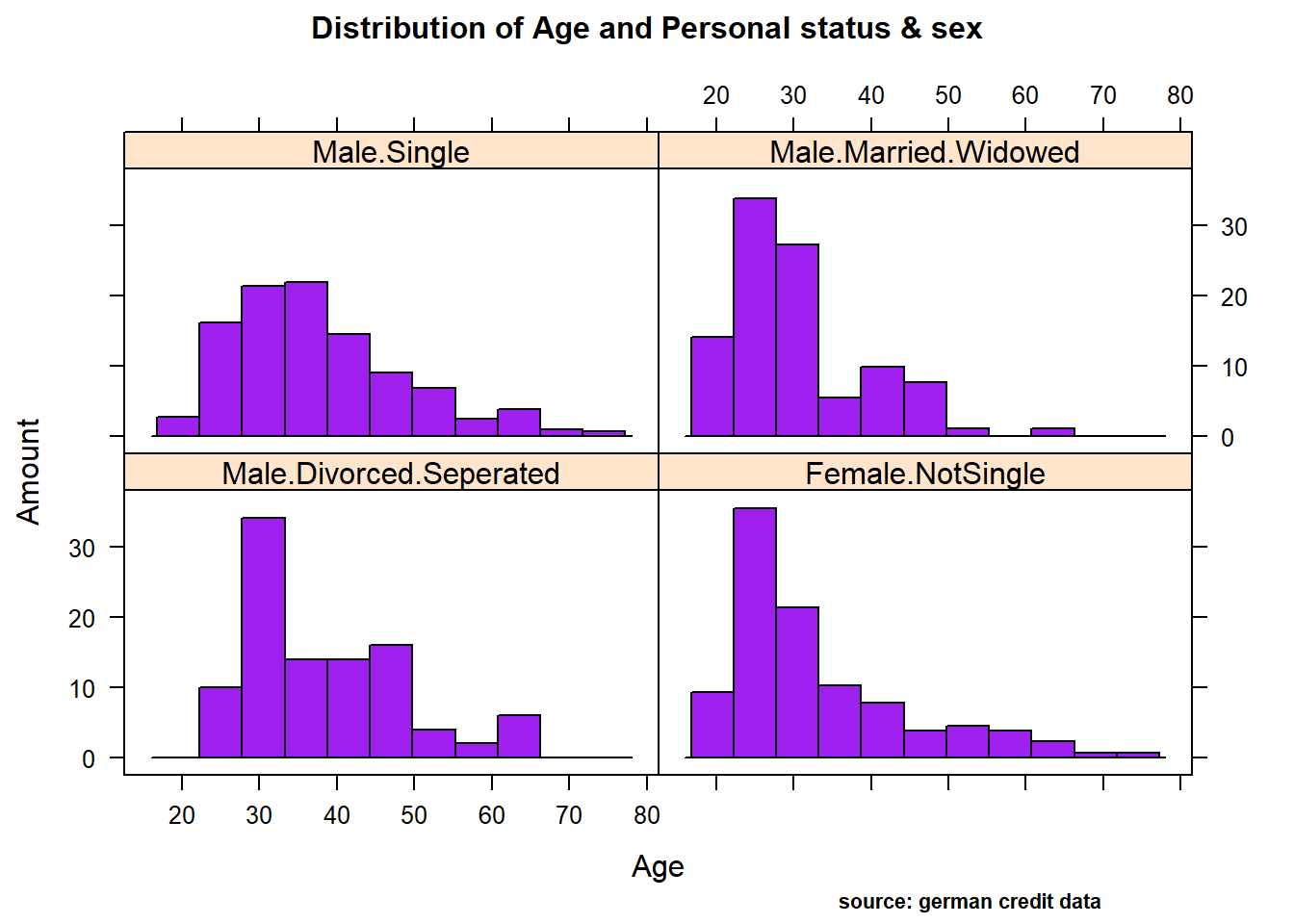
III. Data Preprocessing
Real-life data typically needs to be preprocessed (e.g. cleansed, filtered, transformed) in order to be used by the machine learning techniques in the analysis step.
Credit scoring portfolios are frequently voluminous and they are in the range of several thousand, well over 100000 applicants measured on more than 100 variables are quite common (Hand and Hen ley 1997). These portfolios are characterized by noise, missing values, complexity of distributions and by redundant or irrelevant features (Piramuthu 2006). Clearly, the applicants characteristics will vary from situation to situation: an applicant looking for a small loan will be asked for different information from another who is asking for a big loan. Also, according to Garcia et al(2012), in credit scoring applications the resampling approaches have produced important gains in performance when compared to the use of the imbalanced data sets
Then in this section, we’ll focus mainly on data preprocessing techniques that are of particular importance when performing a credit scoring task. These techniques include Data wrangling( cleansing, filtering, renaming variables, recodifing factors,etc ) , Features selection(filter,wrapper methods) and Data partitioning (stratified random sampling method to correct the imbalanced class).
3.1. Data Wrangling
To perform the different steps of data pre-processing part and successive analysis , we make a copy of the german credit dataset, in order to to keep unchanged our original german credit data .
german.copy <- german3.1.1.
Missing values
We used the VIM package to explore the data and the structure of the missing or imputed values. Fortunately, We observe that there are no missing values. It’s confirmed not only by the proportion of missings plot , but also by the variable sorted by number of missings output, where each variable have a null count.
If they were missing values, it would be presented with red cells like the case of german credit risk from kaggle downloaded at this link (see second plot)
#aggr function : Calculate or plot the amount of missing/imputed values in each variable and the amount of missing/imputed values in certain combinations of variables.
missing.values <- aggr(german.copy, sortVars = T, prop = T, sortCombs = T,
cex.lab = 1.5, cex.axis = .6, cex.numbers = 5,
combined = F, gap = -.2)
Variables sorted by number of missings:
Variable Count
Duration 0
Amount 0
InstallmentRatePercentage 0
ResidenceDuration 0
Age 0
NumberExistingCredits 0
NumberPeopleMaintenance 0
Telephone 0
ForeignWorker 0
CheckingAccountStatus 0
CreditHistory 0
Purpose 0
SavingsAccountBonds 0
EmploymentDuration 0
Personal 0
OtherDebtorsGuarantors 0
Property 0
OtherInstallmentPlans 0
Housing 0
Job 0
Class 0#german credit data from kaggle
GCD <- read.csv(file="german_credit_data.csv", header=TRUE, sep=",")
germanKaggle_NA <- aggr(GCD, sortVars = T, prop = T, sortCombs = T,
cex.lab = 1.5, cex.axis = .6, cex.numbers = 5,
combined = F, gap = -.2)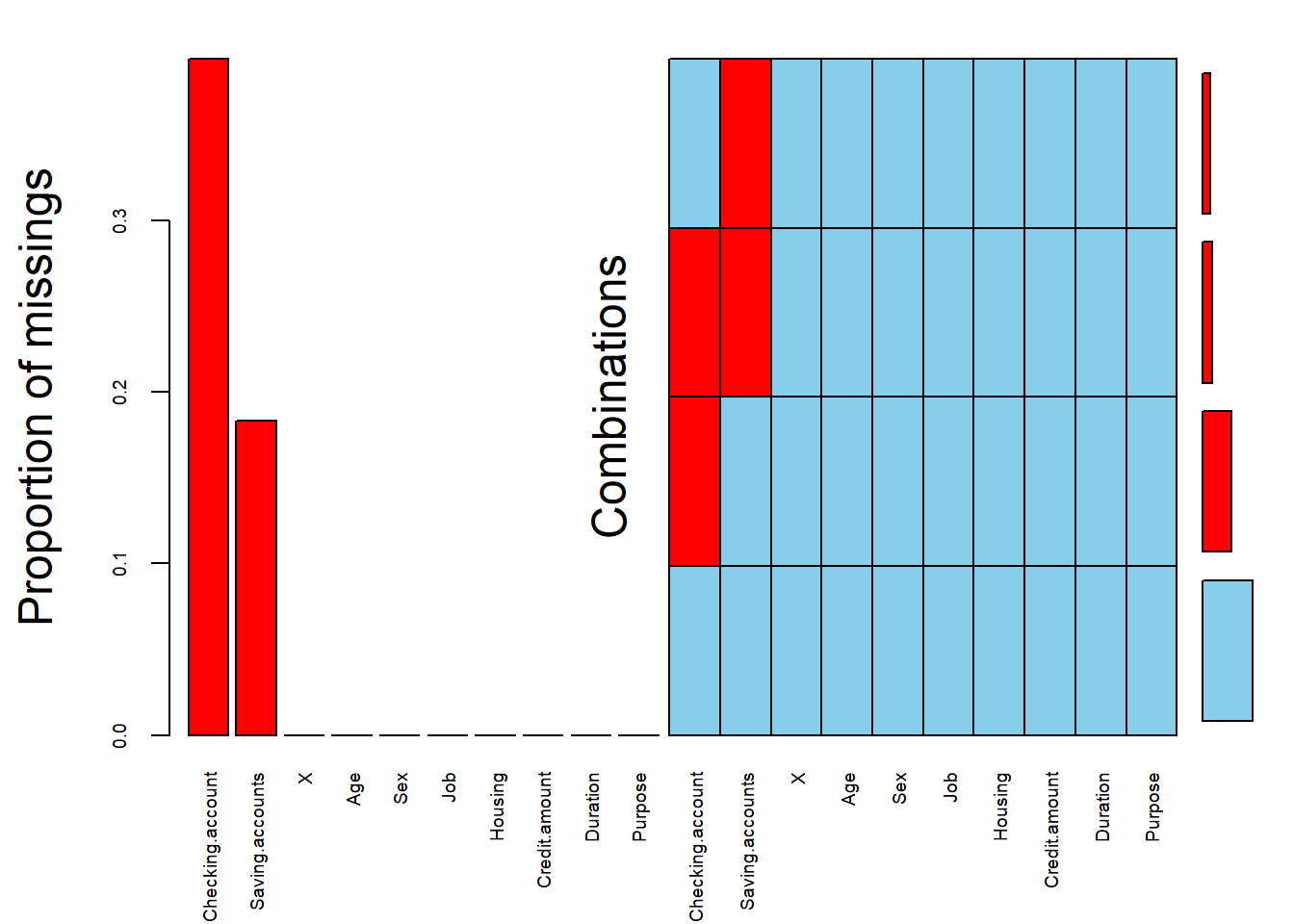
Variables sorted by number of missings:
Variable Count
Checking.account 0.394
Saving.accounts 0.183
X 0.000
Age 0.000
Sex 0.000
Job 0.000
Housing 0.000
Credit.amount 0.000
Duration 0.000
Purpose 0.0003.1.2.
Renaming variables
Renaming data columns is a common task in Data pre-processing that can make implementing ML algorithms/ writing code faster by using short, intuitive names. The dplyr function rename() makes this easy.
#rename(data, new_name = `old_name`)
german.copy = rename( german.copy,
Risk = `Class`,
installment_rate = `InstallmentRatePercentage`,
present_resid = `ResidenceDuration`,
n_credits = `NumberExistingCredits`,
n_people = `NumberPeopleMaintenance`,
check_acct = `CheckingAccountStatus`,
credit_hist = `CreditHistory`,
savings_acct = `SavingsAccountBonds`,
present_emp = `EmploymentDuration`,
status_sex = `Personal`,
other_debt = `OtherDebtorsGuarantors`,
other_install = `OtherInstallmentPlans`
)
#get glimpse of data
glimpse(german.copy)Observations: 1,000
Variables: 21
$ Duration <dbl> 6, 48, 12, 42, 24, 36, 24, 36, 12, 30, 12, 48...
$ Amount <dbl> 1169, 5951, 2096, 7882, 4870, 9055, 2835, 694...
$ installment_rate <dbl> 4, 2, 2, 2, 3, 2, 3, 2, 2, 4, 3, 3, 1, 4, 2, ...
$ present_resid <dbl> 4, 2, 3, 4, 4, 4, 4, 2, 4, 2, 1, 4, 1, 4, 4, ...
$ Age <dbl> 67, 22, 49, 45, 53, 35, 53, 35, 61, 28, 25, 2...
$ n_credits <dbl> 2, 1, 1, 1, 2, 1, 1, 1, 1, 2, 1, 1, 1, 2, 1, ...
$ n_people <dbl> 1, 1, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
$ Telephone <fct> none, yes, yes, yes, yes, none, yes, none, ye...
$ ForeignWorker <fct> yes, yes, yes, yes, yes, yes, yes, yes, yes, ...
$ check_acct <fct> lt.0, 0.to.200, none, lt.0, lt.0, none, none,...
$ credit_hist <fct> Critical, PaidDuly, Critical, PaidDuly, Delay...
$ Purpose <fct> Radio.Television, Radio.Television, Education...
$ savings_acct <fct> Unknown, lt.100, lt.100, lt.100, lt.100, Unkn...
$ present_emp <fct> gt.7, 1.to.4, 4.to.7, 4.to.7, 1.to.4, 1.to.4,...
$ status_sex <fct> Male.Single, Female.NotSingle, Male.Single, M...
$ other_debt <fct> None, None, None, Guarantor, None, None, None...
$ Property <fct> RealEstate, RealEstate, RealEstate, Insurance...
$ other_install <fct> None, None, None, None, None, None, None, Non...
$ Housing <fct> Own, Own, Own, ForFree, ForFree, ForFree, Own...
$ Job <fct> SkilledEmployee, SkilledEmployee, UnskilledRe...
$ Risk <fct> Good, Bad, Good, Good, Bad, Good, Good, Good,...3.1.3.
Skewness
Skewness is defined to be the third standardized central moment .You can easily tell if a distribution is skewed by simple visualization. There are different ways may help to remove skewness such as log, square root or inverse. However it is often difficult to determine from plots which transformation is most appropriate for correcting skewness. The Box-Cox procedure automatically identified a transformation from the family of power transformations that are indexed by a parameter \(λ\).
This family includes:
- log transformation \((λ=0)\)
- square transformation \((λ=2)\)
- square root \((λ=0.5)\)
- inverse \((λ=−1)\)
We used preProcess() function in caret to apply this transformation by changing the method argument to BoxCox.
mySkew <- preProcess(german.copy, method = c("BoxCox"))
mySkew## Created from 1000 samples and 20 variables
##
## Pre-processing:
## - Box-Cox transformation (6)
## - ignored (14)
##
## Lambda estimates for Box-Cox transformation:
## 0.1, -0.1, 1.5, 1.1, -0.7, -2mySkew$method## $BoxCox
## [1] "Duration" "Amount" "installment_rate"
## [4] "present_resid" "Age" "n_credits"
##
## $ignore
## [1] "Telephone" "ForeignWorker" "check_acct" "credit_hist"
## [5] "Purpose" "savings_acct" "present_emp" "status_sex"
## [9] "other_debt" "Property" "other_install" "Housing"
## [13] "Job" "Risk"mySkew$bc## $Duration
## Box-Cox Transformation
##
## 1000 data points used to estimate Lambda
##
## Input data summary:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 4.0 12.0 18.0 20.9 24.0 72.0
##
## Largest/Smallest: 18
## Sample Skewness: 1.09
##
## Estimated Lambda: 0.1
## With fudge factor, Lambda = 0 will be used for transformations
##
##
## $Amount
## Box-Cox Transformation
##
## 1000 data points used to estimate Lambda
##
## Input data summary:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 250 1366 2320 3271 3972 18424
##
## Largest/Smallest: 73.7
## Sample Skewness: 1.94
##
## Estimated Lambda: -0.1
## With fudge factor, Lambda = 0 will be used for transformations
##
##
## $installment_rate
## Box-Cox Transformation
##
## 1000 data points used to estimate Lambda
##
## Input data summary:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.000 2.000 3.000 2.973 4.000 4.000
##
## Largest/Smallest: 4
## Sample Skewness: -0.53
##
## Estimated Lambda: 1.5
##
##
## $present_resid
## Box-Cox Transformation
##
## 1000 data points used to estimate Lambda
##
## Input data summary:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.000 2.000 3.000 2.845 4.000 4.000
##
## Largest/Smallest: 4
## Sample Skewness: -0.272
##
## Estimated Lambda: 1.1
## With fudge factor, no transformation is applied
##
##
## $Age
## Box-Cox Transformation
##
## 1000 data points used to estimate Lambda
##
## Input data summary:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 19.00 27.00 33.00 35.55 42.00 75.00
##
## Largest/Smallest: 3.95
## Sample Skewness: 1.02
##
## Estimated Lambda: -0.7
##
##
## $n_credits
## Box-Cox Transformation
##
## 1000 data points used to estimate Lambda
##
## Input data summary:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.000 1.000 1.000 1.407 2.000 4.000
##
## Largest/Smallest: 4
## Sample Skewness: 1.27
##
## Estimated Lambda: -2We visually inspected the skewness by plotting histogram of the 6 numerical attributes inclined to a BoxCox transformation ( see mySkew$method)
p1<- german.copy %>%
ggplot(aes(x=Amount)) +
geom_histogram(aes(y=..density..), # Histogram with density
binwidth=1000,
colour="black", fill="white") +
geom_density(alpha=.5, fill="purple") + # Overlay with transparent density plot
labs(title= "Histogram of Amount", subtitle= "overlaid with kernel density curve", caption = "source:german credit data")
p2<- german.copy %>%
ggplot(aes(x=installment_rate)) +
geom_histogram(aes(y=..density..), # Histogram with density
binwidth=.5,
colour="black", fill="white") +
geom_density(alpha=.5, fill="purple") + # Overlay with transparent density plot
labs(title= "Histogram of installment rate percentage", subtitle= "overlaid with kernel density curve", caption = "source:german credit data")
p3 <- german.copy %>%
ggplot(aes(x=Duration)) +
geom_histogram(aes(y=..density..), # Histogram with density instead y-axis count
binwidth=5,
colour="black", fill="white") +
geom_density(alpha=.5, fill="purple") + # Overlay with transparent density plot
labs(title= "Histogram of Duration in months", subtitle= "overlaid with kernel density curve", caption = "source:german credit data")
p4 <- german.copy %>%
ggplot(aes(x=n_credits)) +
geom_histogram(aes(y=..density..),
binwidth=1,
colour="black", fill="white") +
geom_density(alpha=.5, fill="purple") + # Overlay with transparent density plot
labs(title= "Histogram of number of existing credits", subtitle= "overlaid with kernel density curve", caption = "source:german credit data")
p5 <- german.copy %>%
ggplot(aes(x=Age)) +
geom_histogram(aes(y=..density..), # Histogram with density instead of count on y-axis
binwidth=5,
colour="black", fill="white") +
geom_density(alpha=.5, fill="purple") + # Overlay with transparent density plot
labs(title= "Histogram of Age", subtitle= "overlaid with kernel density curve", caption = "source:german credit data")
p6 <- german.copy %>%
ggplot(aes(x=present_resid)) +
geom_histogram(aes(y=..density..),
binwidth=1,
colour="black", fill="white") +
geom_density(alpha=.5, fill="purple") + # Overlay with transparent density plot
labs(title= "Histogram of residence duration", subtitle= "overlaid with kernel density curve", caption = "source:german credit data")
#plot all
grid.arrange(p1, p3, p2, p4, p5, p6, ncol=3)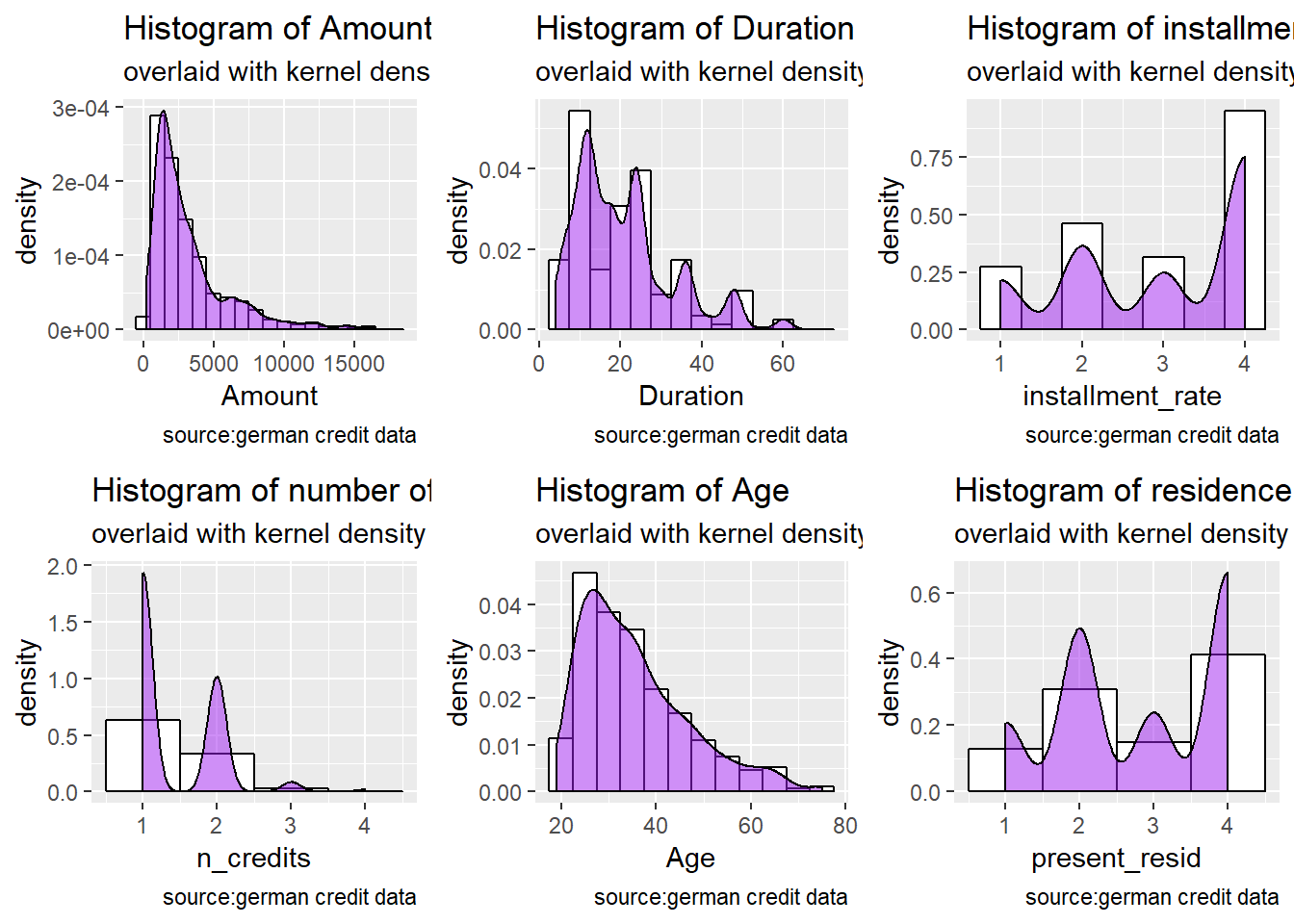
The previous plots confirm the skweness distributions of 6 numerical attributes inclined to a BoxCox transformation. More over, The output of mySkew, the applied BoxCoxTrans , shows the sample size (1000), number of variables (20) and the \(λ\) estimates for Box-Cox transformation candidate variables (6).
Do we have to apply a transformation/ is it useful to resolve skewness for the purpose of our work? : The output of mySkew$bc reveals that the Amount (1.94) , n_credits (1.27) and Duration (1.09) attributes have the higher values of skweness and precises that Lambda = 0 will be used for transformations for Amount and Duration attributes . Numerical features such as n_credits, present_resid, Age, Duration are seen more as discrete variables. The Amount attribute remains the only good candidate to apply a log transformation.
predict() method applies the results to a data frame myTransformed. In the latter,we can find the transformed Amount variable and other BoxCox transformatons applied to the other numerical attributes. We’ll take it account for our successive analysis only if necessary.
myTransformed <- predict(mySkew, german.copy)
glimpse(myTransformed)Observations: 1,000
Variables: 21
$ Duration <dbl> 1.791759, 3.871201, 2.484907, 3.737670, 3.178...
$ Amount <dbl> 7.063904, 8.691315, 7.647786, 8.972337, 8.490...
$ installment_rate <dbl> 4.666667, 1.218951, 1.218951, 1.218951, 2.797...
$ present_resid <dbl> 4, 2, 3, 4, 4, 4, 4, 2, 4, 2, 1, 4, 1, 4, 4, ...
$ Age <dbl> 1.353297, 1.264435, 1.334866, 1.329110, 1.339...
$ n_credits <dbl> 0.3750000, 0.0000000, 0.0000000, 0.0000000, 0...
$ n_people <dbl> 1, 1, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
$ Telephone <fct> none, yes, yes, yes, yes, none, yes, none, ye...
$ ForeignWorker <fct> yes, yes, yes, yes, yes, yes, yes, yes, yes, ...
$ check_acct <fct> lt.0, 0.to.200, none, lt.0, lt.0, none, none,...
$ credit_hist <fct> Critical, PaidDuly, Critical, PaidDuly, Delay...
$ Purpose <fct> Radio.Television, Radio.Television, Education...
$ savings_acct <fct> Unknown, lt.100, lt.100, lt.100, lt.100, Unkn...
$ present_emp <fct> gt.7, 1.to.4, 4.to.7, 4.to.7, 1.to.4, 1.to.4,...
$ status_sex <fct> Male.Single, Female.NotSingle, Male.Single, M...
$ other_debt <fct> None, None, None, Guarantor, None, None, None...
$ Property <fct> RealEstate, RealEstate, RealEstate, Insurance...
$ other_install <fct> None, None, None, None, None, None, None, Non...
$ Housing <fct> Own, Own, Own, ForFree, ForFree, ForFree, Own...
$ Job <fct> SkilledEmployee, SkilledEmployee, UnskilledRe...
$ Risk <fct> Good, Bad, Good, Good, Bad, Good, Good, Good,...p1_new <- myTransformed %>%
ggplot(aes(x=Amount)) +
geom_histogram(aes(y=..density..),
binwidth=.5,
colour="black", fill="white") +
geom_density(alpha=.5, fill="purple") + # Overlay with transparent density plot
labs(title= "Histogram of Amount", subtitle= "overlaid with kernel density curve",
caption = "source: my transformed german data with no Skewness")
p1_new 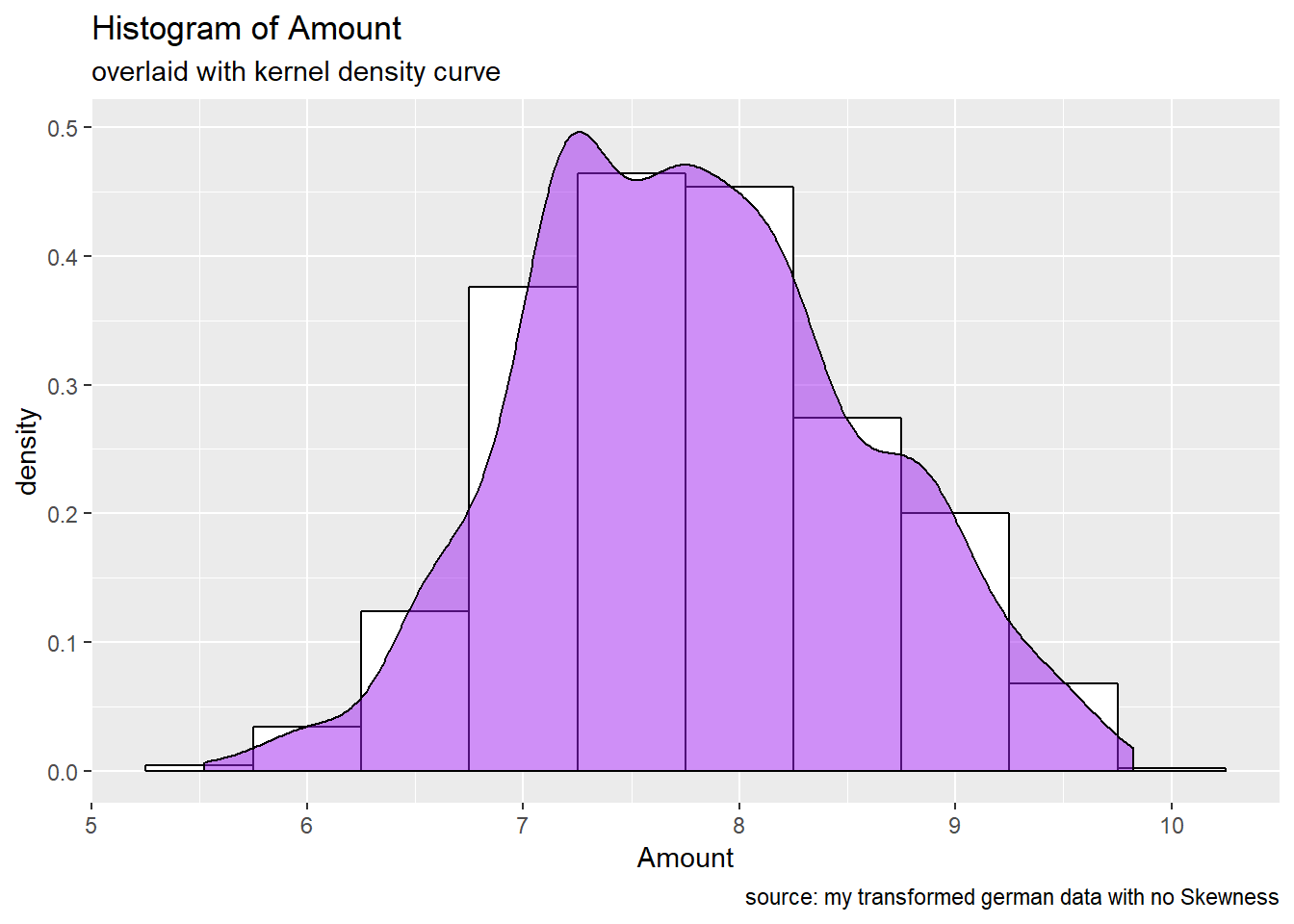
Before to continue with the Feature selection step, we are going to recode the response variable Risk, by creating a new variable (numerical) risk_bin where 0 corresponds to a Bad credit worthiness and 1 to a Good credit worthiness. We didn’t eliminate the original Risk outcome , they can be both useful for successive analysis depending of the Machine learning model we’ll test.
german.copy <- german.copy %>%
mutate(risk_bin = ifelse(Risk == "Bad",0,1))3.2. Features selection
According to HA & Nguyen (2016), there are two different categories of feature selection methods: filter and wrapper methods.
3.2.1.
filter methods
The filter approach considers the feature selection process as a precursor stage of learning algorithms. The filter model uses evaluation functions to evaluate the classification performances of subsets of features. There are many evaluation functions such as feature importance, Gini, information gain, filtering, etc. A disadvantage of this approach is that there is no direct relationship between the feature selection process and the performance of learning algorithms.
- sbf (selection by filtering, caret package):
The caret function sbf (for selection by filter) can be used to cross-validate such feature selection schemes. It’s a part of Univariate filters .They pre-screen the predictors using simple univariate statistical methods.As an example, it has been suggested for classification models, that predictors can be filtered by conducting some sort of k-sample test (where k is the number of classes) to see if the mean of the predictor is different between the classes. Wilcoxon tests, t-tests and ANOVA models are sometimes used. Predictors that have statistically significant differences between the classes are then used for modeling.For more details, read this
filterCtrl <- sbfControl(functions = rfSBF, method = "repeatedcv", repeats = 5)
set.seed(1)
rfWithFilter <- sbf( Risk ~ ., german.copy[,-22], sbfControl = filterCtrl)
rfWithFilter##
## Selection By Filter
##
## Outer resampling method: Cross-Validated (10 fold, repeated 5 times)
##
## Resampling performance:
##
## Accuracy Kappa AccuracySD KappaSD
## 0.743 0.3189 0.03666 0.09716
##
## Using the training set, 23 variables were selected:
## Duration, Amount, installment_rate, Age, ForeignWorkeryes...
##
## During resampling, the top 5 selected variables (out of a possible 30):
## Age (100%), Amount (100%), check_acct0.to.200 (100%), check_acctnone (100%), credit_histCritical (100%)
##
## On average, 21.8 variables were selected (min = 19, max = 25)The output of Model fitting after applying sbf univariate filters tell us that the top 5 selected variables are : Age (100%), Amount (100%), check_acct0.to.200 (100%), check_acctnone (100%), credit_histCritical (100%).Let’s try another method to assert or rebut the latter findings.
- WOE,IV (Information package) :
Weight of Evidence(WOE): WOE shows predictive power of an independent variable in relation to dependent variable. It evolved with credit scoring to magnify separation power between a good customer and a bad customer, hence it is one of the measures of separation between two classes(good/bad, yes/no, 0/1, A/B, response/no-response). It is defined as: \[WOE = ln(\frac{Distribution.of.nonEvents(Good)}{Distribution.of.Events(Bad)})\] .It is computed from the basic odds ratio: (Distribution of Good Credit Outcomes) / (Distribution of Bad Credit Outcomes)
Some benefits of WOE lie in the fact that it can treat outliers (Suppose you have a continuous variable such as annual salary and extreme values are more than 500 million dollars. These values would be grouped to a class of (let’s say 250-500 million dollars). Later, instead of using the raw values, we would be using WOE scores of each classes.) and handle missing values as missing values can be binned separately. Also, It handles both continuous and categorical variables so there is no need for dummy variables.
Information value(IV): Information value is one of the most useful technique to select important variables in a predictive model. It helps to rank variables on the basis of their importance. The IV is calculated using the following formula : \[IV =\sum(\%nonEvents - \%events)* WOE\]
According to Siddiqi (2006), by convention the values of the \(IV\) statistic in credit scoring can be interpreted as follows.
If the \(IV\) statistic is:
- Less than 0.02, then the predictor is not useful for modeling (separating the Goods from the Bads)
- 0.02 to 0.1, then the predictor has only a weak relationship to the Goods/Bads odds ratio
- 0.1 to 0.3, then the predictor has a medium strength relationship to the Goods/Bads odds ratio
- 0.3 to 0.5, then the predictor has a strong relationship to the Goods/Bads odds ratio.
- greater than 0.5, suspicious relationship (Check once)
IV <- create_infotables(data=german.copy[,-21], NULL, y="risk_bin", bins=10)
IV$Summary$IV <- round(IV$Summary$IV*100,2)
#get tables from the IV statistic
IV$Tables## $Duration
## Duration N Percent WOE IV
## 1 [4,8] 94 0.094 1.28093385 0.1110143
## 2 [9,11] 86 0.086 0.55359530 0.1342125
## 3 [12,14] 187 0.187 0.16066006 0.1388793
## 4 [15,16] 66 0.066 0.55804470 0.1569494
## 5 [18,22] 153 0.153 -0.18342106 0.1622773
## 6 [24,28] 201 0.201 -0.03995831 0.1626008
## 7 [30,33] 43 0.043 -0.11905936 0.1632244
## 8 [36,72] 170 0.170 -0.77668029 0.2778772
##
## $Amount
## Amount N Percent WOE IV
## 1 [250,931] 99 0.099 -0.06177736 0.0003824313
## 2 [932,1258] 99 0.099 -0.01438874 0.0004029866
## 3 [1262,1474] 99 0.099 0.23789141 0.0057272229
## 4 [1478,1901] 102 0.102 0.38665578 0.0197204795
## 5 [1905,2315] 100 0.100 0.04808619 0.0199494614
## 6 [2319,2835] 100 0.100 0.25131443 0.0259331383
## 7 [2848,3578] 100 0.100 0.36101335 0.0379669164
## 8 [3590,4712] 100 0.100 0.04808619 0.0381958983
## 9 [4716,7166] 100 0.100 -0.31508105 0.0486985998
## 10 [7174,18424] 101 0.101 -0.74820696 0.1117617577
##
## $installment_rate
## installment_rate N Percent WOE IV
## 1 [1,1] 136 0.136 0.25131443 0.008137801
## 2 [2,2] 231 0.231 0.15546647 0.013542111
## 3 [3,3] 157 0.157 0.06453852 0.014187496
## 4 [4,4] 476 0.476 -0.15730029 0.026322090
##
## $present_resid
## present_resid N Percent WOE IV
## 1 [1,1] 130 0.130 0.112477983 0.001606828
## 2 [2,2] 308 0.308 -0.070150705 0.003143463
## 3 [3,3] 149 0.149 0.054941118 0.003588224
## 4 [4,4] 413 0.413 -0.001152738 0.003588773
##
## $Age
## Age N Percent WOE IV
## 1 [19,22] 57 0.057 -0.38299225 0.008936486
## 2 [23,25] 133 0.133 -0.59025276 0.059810652
## 3 [26,27] 101 0.101 0.16093037 0.062339558
## 4 [28,29] 80 0.080 -0.33647224 0.071953050
## 5 [30,32] 112 0.112 0.11316409 0.073354130
## 6 [33,35] 105 0.105 0.06899287 0.073846936
## 7 [36,38] 92 0.092 0.56639547 0.099739300
## 8 [39,44] 119 0.119 0.06899287 0.100297814
## 9 [45,51] 96 0.096 0.48770321 0.120734901
## 10 [52,75] 105 0.105 0.06899287 0.121227707
##
## $n_credits
## n_credits N Percent WOE IV
## 1 [1,1] 633 0.633 -0.0748775 0.003601251
## 2 [2,4] 367 0.367 0.1347806 0.010083557
##
## $n_people
## n_people N Percent WOE IV
## 1 [1,1] 845 0.845 -0.00281611 6.705024e-06
## 2 [2,2] 155 0.155 0.01540863 4.339223e-05
##
## $Telephone
## Telephone N Percent WOE IV
## 1 none 404 0.404 0.09863759 0.003851563
## 2 yes 596 0.596 -0.06469132 0.006377605
##
## $ForeignWorker
## ForeignWorker N Percent WOE IV
## 1 no 37 0.037 1.26291534 0.04269857
## 2 yes 963 0.963 -0.03486727 0.04387741
##
## $check_acct
## check_acct N Percent WOE IV
## 1 0.to.200 269 0.269 -0.4013918 0.04644676
## 2 gt.200 63 0.063 0.4054651 0.05590762
## 3 lt.0 274 0.274 -0.8180987 0.26160100
## 4 none 394 0.394 1.1762632 0.66601150
##
## $credit_hist
## credit_hist N Percent WOE IV
## 1 Critical 293 0.293 0.73374058 0.1324227
## 2 Delay 88 0.088 -0.08515781 0.1330715
## 3 NoCredit.AllPaid 40 0.040 -1.35812348 0.2171458
## 4 PaidDuly 530 0.530 -0.08831862 0.2213515
## 5 ThisBank.AllPaid 49 0.049 -1.13497993 0.2932335
##
## $Purpose
## Purpose N Percent WOE IV
## 1 Business 97 0.097 -0.23052366 0.005378885
## 2 DomesticAppliance 12 0.012 -0.15415068 0.005672506
## 3 Education 50 0.050 -0.60613580 0.025877032
## 4 Furniture.Equipment 181 0.181 -0.09555652 0.027560647
## 5 NewCar 234 0.234 -0.35920049 0.059717643
## 6 Other 12 0.012 -0.51082562 0.063123147
## 7 Radio.Television 280 0.280 0.41006282 0.106082109
## 8 Repairs 22 0.022 -0.28768207 0.107999990
## 9 Retraining 9 0.009 1.23214368 0.117974486
## 10 UsedCar 103 0.103 0.77383609 0.169195066
##
## $savings_acct
## savings_acct N Percent WOE IV
## 1 100.to.500 103 0.103 -0.1395519 0.002060052
## 2 500.to.1000 63 0.063 0.7060506 0.028621002
## 3 Unknown 183 0.183 0.7042461 0.105417360
## 4 gt.1000 48 0.048 1.0986123 0.149361851
## 5 lt.100 603 0.603 -0.2713578 0.196009557
##
## $present_emp
## present_emp N Percent WOE IV
## 1 1.to.4 339 0.339 -0.03210325 0.000351607
## 2 4.to.7 174 0.174 0.39441527 0.025143424
## 3 Unemployed 62 0.062 -0.31923043 0.031832062
## 4 gt.7 253 0.253 0.23556607 0.045180806
## 5 lt.1 172 0.172 -0.47082029 0.086433631
##
## $status_sex
## status_sex N Percent WOE IV
## 1 Female.NotSingle 310 0.310 -0.2353408 0.01793073
## 2 Male.Divorced.Seperated 50 0.050 -0.4418328 0.02845056
## 3 Male.Married.Widowed 92 0.092 0.1385189 0.03016555
## 4 Male.Single 548 0.548 0.1655476 0.04467068
##
## $other_debt
## other_debt N Percent WOE IV
## 1 CoApplicant 41 0.041 -0.6021754024 0.01634476
## 2 Guarantor 52 0.052 0.5877866649 0.03201907
## 3 None 907 0.907 0.0005250722 0.03201932
##
## $Property
## Property N Percent WOE IV
## 1 CarOther 332 0.332 -0.03419136 0.0003907585
## 2 Insurance 232 0.232 -0.02857337 0.0005812476
## 3 RealEstate 282 0.282 0.46103496 0.0545882000
## 4 Unknown 154 0.154 -0.58608236 0.1126382624
##
## $other_install
## other_install N Percent WOE IV
## 1 Bank 139 0.139 -0.4836299 0.03523589
## 2 None 814 0.814 0.1211786 0.04689212
## 3 Stores 47 0.047 -0.4595323 0.05761454
##
## $Housing
## Housing N Percent WOE IV
## 1 ForFree 108 0.108 -0.4726044 0.02610577
## 2 Own 713 0.713 0.1941560 0.05190078
## 3 Rent 179 0.179 -0.4044452 0.08329343
##
## $Job
## Job N Percent WOE IV
## 1 Management.SelfEmp.HighlyQualified 148 0.148 -0.20441251 0.006424393
## 2 SkilledEmployee 630 0.630 0.02278003 0.006749822
## 3 UnemployedUnskilled 22 0.022 -0.08515781 0.006912028
## 4 UnskilledResident 200 0.200 0.09716375 0.008762766#get summary of the IV statistic
IV$Summary Variable IV
10 check_acct 66.60
11 credit_hist 29.32
1 Duration 27.79
13 savings_acct 19.60
12 Purpose 16.92
5 Age 12.12
17 Property 11.26
2 Amount 11.18
14 present_emp 8.64
19 Housing 8.33
18 other_install 5.76
15 status_sex 4.47
9 ForeignWorker 4.39
16 other_debt 3.20
3 installment_rate 2.63
6 n_credits 1.01
20 Job 0.88
8 Telephone 0.64
4 present_resid 0.36
7 n_people 0.00We observed that following variables do not have prediction power - very very weak predictor (IV< 2%), hence we shall exclude them from modeling:
kable(IV$Summary %>%
filter(IV < 2))| Variable | IV |
|---|---|
| n_credits | 1.01 |
| Job | 0.88 |
| Telephone | 0.64 |
| present_resid | 0.36 |
| n_people | 0.00 |
Second group of variables are very weak predictors (2%<=IV< 10%), hence we may or may not include them while modeling
kable(IV$Summary %>%
filter(IV >= 2 & IV < 10 ))| Variable | IV |
|---|---|
| present_emp | 8.64 |
| Housing | 8.33 |
| other_install | 5.76 |
| status_sex | 4.47 |
| ForeignWorker | 4.39 |
| other_debt | 3.20 |
| installment_rate | 2.63 |
Third group of variables have medium prediction power (10%<=IV< 30%), hence we will include them in modeling as we have less number of variables
kable(IV$Summary %>%
filter(IV >= 10 & IV < 30 ))| Variable | IV |
|---|---|
| credit_hist | 29.32 |
| Duration | 27.79 |
| savings_acct | 19.60 |
| Purpose | 16.92 |
| Age | 12.12 |
| Property | 11.26 |
| Amount | 11.18 |
There is no strong predictor with IV between 30% to 50%
kable(IV$Summary %>%
filter(IV >= 30 & IV < 50 ))| Variable | IV |
|---|---|
check_acct has a very high prediction power (IV > 50%), it could be suspicious and require further investigation.
kable(IV$Summary %>%
filter( IV > 50 ))| Variable | IV |
|---|---|
| check_acct | 66.6 |
3.2.2.
wrapper methods
Wrapper methods consider the selection of a set of features as a search problem, where different combinations are prepared, evaluated and compared to other combinations. A predictive model us used to evaluate a combination of features and assign a score based on model accuracy. The search process may be methodical such as a best-first search, it may stochastic such as a random hill-climbing algorithm, or it may use heuristics, like forward and backward passes to add and remove features. One disadvantage of the wrapper approach is highly computational cost.
An example of a wrapper method is the recursive feature elimination algorithm. Another example is the boruta algorithm.
- rfe (recursive feature elimination, caret package):
Recursive feature elimination via the caret package, is a wrapper method which is explained by the algorithm below. For further details follow Recursive Feature Elimination via caret
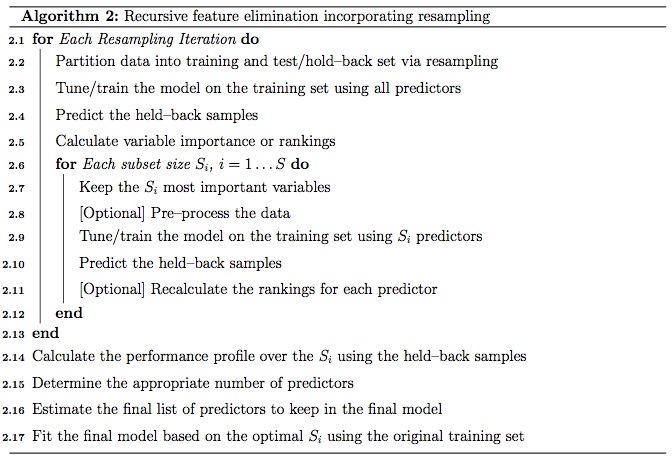
recursive feature elimitation algorithm
We created a function called “recur.feature.selection” which internally defined : x, the data frame of predictor variables ; y, the vector (numeric or factor) of outcome (y) ; sizes, an integer vector for the specific subset sizes that should be tested, and a list of options that can be used to specify the model and the methods for prediction(using rfecontrol). Then we applied the algorithm using the rfe function.
recur.feature.selection <- function(num.iters=20, features.var, outcome.var){
set.seed(10)
sizes.var <- 1:20
control <- rfeControl(functions = rfFuncs, #pre-defined sets of functions,randomForest(rffuncs)
method = "cv",
number = num.iters,
returnResamp = "all",
verbose = FALSE
)
results.rfe <- rfe(x = features.var,
y = outcome.var,
sizes = sizes.var,
rfeControl = control)
return(results.rfe)
}#before to apply the rfe algorithm, i clear unusued memory
invisible(gc())#To resolve the summary.connection(connection) : invalid connection, i install the doSnow-parallel-DeLuxe R script performed by Tobias Kind (2015); see more here : https://github.com/tobigithub/R-parallel/wiki/R-parallel-Errors
source("Install-doSNOW-parallel-DeLuxe.R") ## 2 cores detected.4 threads detected.[1] "Cluster stopped."#i remove in the features.var (both Risk (21) and risk_bin (22)) / i keep only Risk (factor) as outcome var.
rfe.results <- recur.feature.selection(features.var = german.copy[,c(-21,-22)],
outcome.var = german.copy[,21])
# view results
rfe.results##
## Recursive feature selection
##
## Outer resampling method: Cross-Validated (20 fold)
##
## Resampling performance over subset size:
##
## Variables Accuracy Kappa AccuracySD KappaSD Selected
## 1 0.687 0.01115 0.03197 0.03603
## 2 0.727 0.26590 0.04169 0.13144
## 3 0.737 0.28146 0.04269 0.11063
## 4 0.729 0.30158 0.05524 0.15665
## 5 0.746 0.34942 0.05236 0.14191
## 6 0.772 0.40465 0.05085 0.14150
## 7 0.770 0.39423 0.04026 0.12075
## 8 0.766 0.38039 0.05586 0.16309
## 9 0.770 0.39346 0.05712 0.16442
## 10 0.776 0.40547 0.05295 0.15160
## 11 0.778 0.40704 0.05386 0.15556 *
## 12 0.773 0.39260 0.04953 0.14876
## 13 0.772 0.38039 0.06031 0.17823
## 14 0.772 0.38123 0.05288 0.15897
## 15 0.760 0.34651 0.05351 0.15822
## 16 0.772 0.37718 0.05167 0.15584
## 17 0.769 0.37059 0.05004 0.15479
## 18 0.761 0.35214 0.04564 0.14335
## 19 0.773 0.37491 0.04366 0.13925
## 20 0.771 0.37221 0.04745 0.14784
##
## The top 5 variables (out of 11):
## check_acct, Duration, credit_hist, Amount, savings_acctThe recursive feature selection output (Outer resampling method: Cross-Validated (20 fold) ) shows that the top 5 variables are: check_acct, Duration, credit_hist, Amount and savings_acct. These findings are somehow in line with those of WOE and IV statistics. ( check_acct has the highest power prediction, and features such as Amount,Duration, savings_acct have medium prediction power)
- Boruta algorithm :
Boruta algorithm is a wrapper built around the random forest classification algorithm implemented in the R package randomForest (Liaw and Wiener, 2002). It tries to capture all the important, interesting features you might have in your dataset with respect to an outcome variable. As explained in Kursa & Rudnicki (2010), the steps of the boruta algorithm can be resume as follow:
- First, it duplicates the dataset, and shuffle the values in each column. These values are called shadow features. Then, it trains a classifier, such as a Random Forest Classifier, on the dataset. By doing this, you ensure that you can an idea of the importance -via the Mean Decrease Accuracy or Mean Decrease Impurity- for each of the features of your data set. The higher the score, the better or more important.
- Then, the algorithm checks for each of your real features if they have higher importance. That is, whether the feature has a higher Z-score than the maximum Z-score of its shadow features than the best of the shadow features. If they do, it records this in a vector. These are called a hits. Next,it will continue with another iteration. After a predefined set of iterations, you will end up with a table of these hits.
- At every iteration, the algorithm compares the Z-scores of the shuffled copies of the features and the original features to see if the latter performed better than the former. If it does, the algorithm will mark the feature as important. In essence, the algorithm is trying to validate the importance of the feature by comparing with random shuffled copies, which increases the robustness. This is done by simply comparing the number of times a feature did better with the shadow features using a binomial distribution.
- If a feature hasn’t been recorded as a hit in say 15 iterations, you reject it and also remove it from the original matrix. After a set number of iterations -or if all the features have been either confirmed or rejected- you stop.
set.seed(123)
Boruta.german <- Boruta(Risk ~ . , data = german.copy[,-22], doTrace = 0, ntree = 500)
Boruta.germanBoruta performed 99 iterations in 1.026238 mins.
11 attributes confirmed important: Age, Amount, check_acct,
credit_hist, Duration and 6 more;
4 attributes confirmed unimportant: ForeignWorker, n_people,
status_sex, Telephone;
5 tentative attributes left: Housing, installment_rate, Job,
n_credits, present_resid;#Functions which convert the Boruta selection into a formula which returns only Confirmed attributes.
getConfirmedFormula(Boruta.german)Risk ~ Duration + Amount + Age + check_acct + credit_hist + Purpose +
savings_acct + present_emp + other_debt + Property + other_install
<environment: 0x00000000234f9f30>Boruta function uses y the response vector as factor . Then in the formula, we should consider Risk and not risk_bin. We observed that Boruta performed 99 iterations in 2.055356 mins, and the confirmed important attributes are 11 : Duration , Amount , Age , check_acct , credit_hist , Purpose , savings_acct , present_emp , other_debt , Property and other_install (results that go in accordance with WOE and IV statistics, from weak to highest predictors) . See the plot below, where Blue boxplots correspond to minimal, average and maximum Z score of a shadow attribute. Red and green boxplots represent Z scores of respectively rejected and confirmed attributes. Yellow boxplots represent Z scores of 5 tentative attributes left.
#plot boruta object
plot(Boruta.german,las=2, main="Boruta result plot for german data")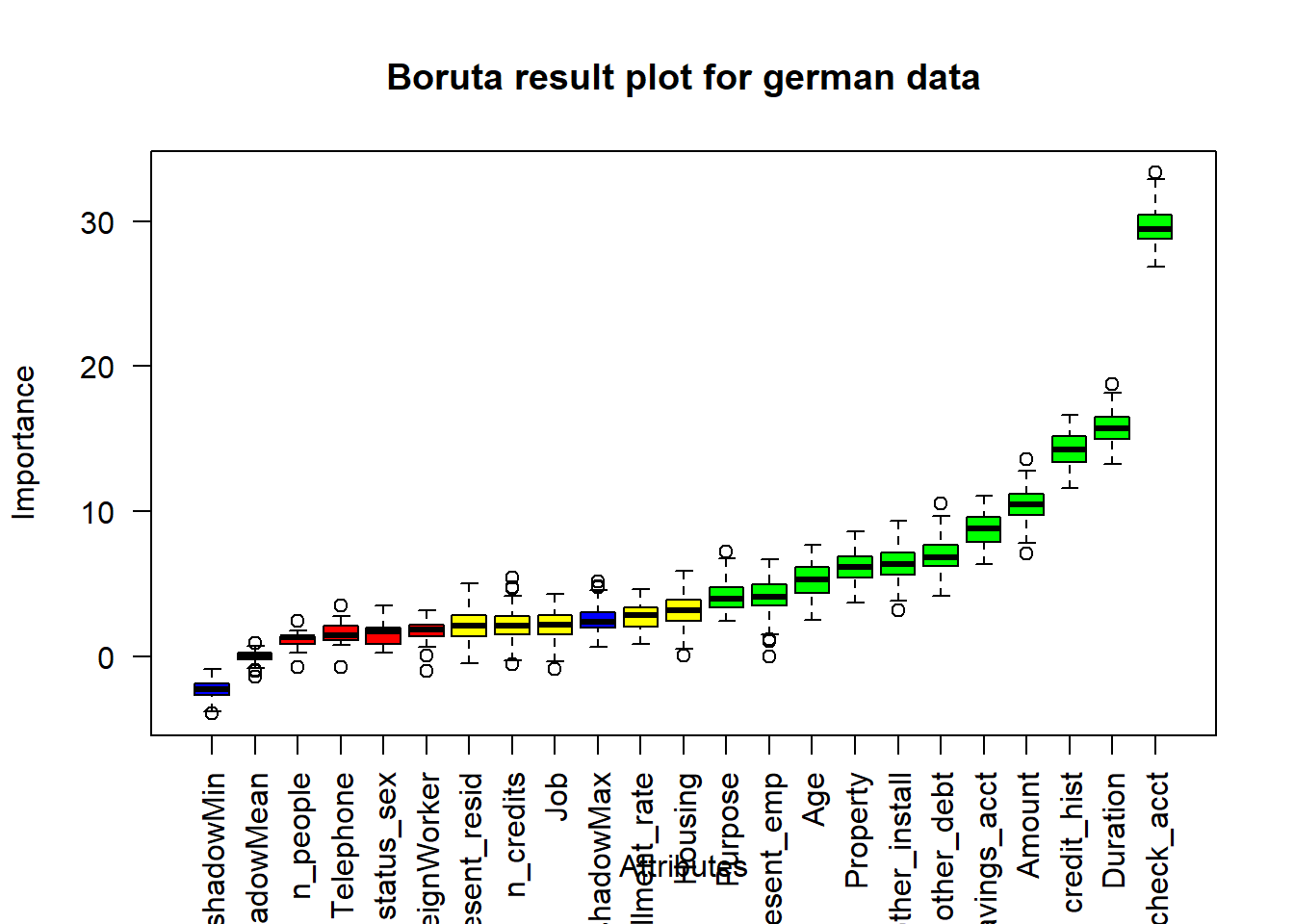
3.2.3.
Embedded methods
A third feature selection method, embedded methods , is detailed in Aggarwal (2014). This class of methods embedding feature selection with classifier construction, have the advantages of wrapper models — they include the interaction with the classification model and filter models—and they are far less computationally intensive than wrapper methods. There are of 3 types : The first are pruning techniques that first utilize all features to train a model and then attempt to eliminate some features by setting the corresponding coefficients to 0 , while maintaining model performance such as recursive feature elimination using a support vector machine . The second are models with a built-in mechanism for feature selection such as C4.5 algorithm. The third are regularization models with objective functions that minimize fitting errors and in the meantime force the coefficients to be small or to be exactly zero ( Elastic Net or Ridge Regression)
However in our study, we are not going to developp these models as features selectors . Here, we just give an overview of this third feature selection approach.
At the end, Based on the Weight of Evidence and Information Value statistics results, we will keep attributes which \(IV > 2\). More over, the wrapper methods , recursive feature elimination and Boruta algorithm confirm this choice since they helped to investigate better on the suspicious character of the highest power predictor, check_acct. The important attributes validated by these algorithms corroborate with our choice.
#attributes to keep (IV>2)
keep <- IV$Summary %>%
filter( IV > 2)
#german.copy data with attributes(IV>2) and response variable
german.copy2 <- german.copy[,c(keep$Variable,"Risk")]
#for convenience, we change the levels Good = 1, Bad = 0
german.copy2$Risk <- as.factor(ifelse(german.copy2$Risk == "Bad", '0', '1'))
#get a glimpse of german copies , see the differences./ german.copy2 is our subsetted data after pre-processing
glimpse(german.copy2)Observations: 1,000
Variables: 16
$ check_acct <fct> lt.0, 0.to.200, none, lt.0, lt.0, none, none,...
$ credit_hist <fct> Critical, PaidDuly, Critical, PaidDuly, Delay...
$ Duration <dbl> 6, 48, 12, 42, 24, 36, 24, 36, 12, 30, 12, 48...
$ savings_acct <fct> Unknown, lt.100, lt.100, lt.100, lt.100, Unkn...
$ Purpose <fct> Radio.Television, Radio.Television, Education...
$ Age <dbl> 67, 22, 49, 45, 53, 35, 53, 35, 61, 28, 25, 2...
$ Property <fct> RealEstate, RealEstate, RealEstate, Insurance...
$ Amount <dbl> 1169, 5951, 2096, 7882, 4870, 9055, 2835, 694...
$ present_emp <fct> gt.7, 1.to.4, 4.to.7, 4.to.7, 1.to.4, 1.to.4,...
$ Housing <fct> Own, Own, Own, ForFree, ForFree, ForFree, Own...
$ other_install <fct> None, None, None, None, None, None, None, Non...
$ status_sex <fct> Male.Single, Female.NotSingle, Male.Single, M...
$ ForeignWorker <fct> yes, yes, yes, yes, yes, yes, yes, yes, yes, ...
$ other_debt <fct> None, None, None, Guarantor, None, None, None...
$ installment_rate <dbl> 4, 2, 2, 2, 3, 2, 3, 2, 2, 4, 3, 3, 1, 4, 2, ...
$ Risk <fct> 1, 0, 1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, ...3.3. Data partitioning
Stratified random sampling is a method of sampling that involves the division of a population into smaller groups known as strata. This is useful for imbalanced datasets, and can be used to give more weight to a minority class. In stratified random sampling, the strata are formed based on members’ shared attributes or characteristics. See more here or read Garcia et al(2012) that is already mentioned at the introduction of Data pre-processing paragraph.
In our case we will use Good/Bad as strata and partition data into 70%-30% as train and test sets. The caret function createDataPartition() can be used to create balanced splits of the data
index <- createDataPartition(y = german.copy2$Risk, p = 0.7, list = F)
# i create a function to calculate percent distribution for factors
pct <- function(x){
tbl <- table(x)
tbl_pct <- cbind(tbl,round(prop.table(tbl)*100,2))
colnames(tbl_pct) <- c('Count','Percentage')
kable(tbl_pct)
}
#training set and test set
train <- german.copy2[index,]
pct(train$Risk)| Count | Percentage | |
|---|---|---|
| 0 | 210 | 30 |
| 1 | 490 | 70 |
test <- german.copy2[-index,]
pct(test$Risk)| Count | Percentage | |
|---|---|---|
| 0 | 90 | 30 |
| 1 | 210 | 70 |
The data preprocessing phase is usually not definitive because it requires a lot of attention and subsequent various explorations on the variables. It must be aimed at obtaining better predictive results and in this sense, the further phases of model evaluations can help us to understand which particular preprocessing approaches are actually indispensable or useful for a specific model purpose.
IV. Methods and Analysis
In machine learning, classification is considered an instance of the supervised learning methods,i.e., inferring a function from labeled training data. The training data consist of a set of training examples, where each example is a pair consisting of an input object (typically a vector of features) \(x =(x_1,x_2, ...,x_d)\) and a desired output value (typically a class label) \(y ∈ \{ C_1,C_2, ...,C_K \}\) . Given such a set of training data, the task of a classification algorithm is to analyze the training data and produce an inferred function, which can be used to classify new (so far unseen) examples by assigning a correct class label to each of them. An example would be assigning an applicant credit scoring into “good†or “bad†classes(then consider the outcome Y as a boolean variable, as in our study). A general process of data classification usually consists of two phases— the training phase and the prediction phase.
There are many classification methods in the literature. These methods can be categorized broadly into probabilistic classification algorithms or linear classifiers (Naive bayes classifiers, logistic regression, Hidden markov models, etc ), support vector machines, decision trees, and Neural networks. (Aggarwal, 2014).
In this section, we are going to explain the methodology over differents Machine Learning algorithms we used taking our principal references from Aggarwal(2014), and to present the metrics for the model performance evaluation.
4.1. Evaluated Algorithms
4.1.1.
Logistic regression
Logistic regression is an approach for predicting the outcome of a categorialdependent variable based on one or more observed features. The probabilities describing the possible outcomes are modeled as a function of the observed variables using a logistic function.
The goal of logistic regression is to directly estimate the distribution P(Y|X) from the training data. Formally, the logistic regression model is defined as \[p(Y = 1|X) = g(θ^TX) = \frac{1}{\ 1 + e^−θ^T X} \tag{1} ,\] where \(g(z) = \frac{1}{\ 1 + e−z}\) is called the logistic function or the sigmoid function, and \(θ^TX = θ_0 + \sum_{i=1}^{d} θiXi\). As the sum of the probabilities must equal 1, p(Y = 0|X) can be estimated using the following equation \[p(Y = 0|X) = 1−g(θ^TX) = \frac{e−θ^TX}{\ 1 + e−θ^TX}. \tag{2}\]
Because logistic regression predicts probabilities, rather than just classes, we can fit it using likelihood. For each training data point, we have a vector of features, \(X =(X_0,X_1,...,X_d) (X_0 = 1)\)*, and an observed class, \(Y = y_k\). The probability of that class was either \(g(θ^TX)\) if \(yk = 1\), or \(1−g(θ^TX)\) if \(y_k = 0\) . Note that we can combine both Equation (1) and Equation (2) as a more compact form \[ \begin{aligned} p(Y = y_k|X;θ) &= (p(Y = 1|X)) ^{y_k} (p(Y = 0|X))^{1−y_k} \\ &= g(θ^TX)^{y_k} (1−g(θTX))^{1−y_k} \end{aligned}\]
Assuming that the N training examples were generated independently, the likelihood of the parameters can be written as
\[ \begin{aligned} L(θ) &= p(\overline{Y} |X;θ) \\ &= \prod_{n = 1}^{N} p(Y^{(n)} = y_k|X^{(n)};θ) ) \\ &= \prod_{n = 1}^{N} \left( p(Y^{(n)} = 1|X^{(n)})\right)^{Y^{(n)}} \left( p(Y^{(n)} = 0|X^{(n)})\right)^{1-Y^{(n)}} \\ &= \prod_{n = 1}^{N} \left( g( θ^T X^{(n)} )\right)^{Y^{(n)}} \left( 1 - g( θ^T X^{(n)} )\right)^{1-Y^{(n)}} \end{aligned} \tag{3}\]
where θ is the vector of parameters to be estimated, \(Y(n)\) denotes the observed value of Y in the nth training example, and \(X(n)\) denotes the observed value of X in the nth training example. To classify any given X, we generally want to assign the value \(y_k\) to Y that maximizes the likelihood. Maximizing the likelihood is equivalent to maximizing the log likelihood.
In our study, using the glm() function of the stats package, we fit our logistic regression model on the training set. Then, in the testing phase, we evaluated our fitted model on the test set with the predict() function of the same package.
4.1.2.
Decision trees
Decision trees create a hierarchical partitioning of the data, which relates the different partitions at the leaf level to the different classes. The hierarchical partitioning at each level is created with the use of a split criterion. The split criterion may either use a condition (or predicate) on a single attribute, or it may contain a condition on multiple attributes. The former is referred to as a univariate split, whereas the latter is referred to as a multivariate split. The overall approach is to try to recursively split the training data so as to maximize the discrimination among the different classes over different nodes. The discrimination among the different classes is maximized, when the level of skew among the different classes in a given node is maximized. A measure such as the gini-index or entropy is used in order to quantify this skew. For example, if \(p_1 . . . p_k\) is the fraction of the records belonging to the \(k\) different classes in a node \(N\), then the gini-index \(G(N)\) of the node \(N\) is defined as follows: \[G(N) = 1− \sum_{i=1}^k =p^2_i \tag{4}\]
The value of \(G(N)\) lies between \(0\) and \(1−1/k\). The smaller the value of G(N), the greater the skew. In the cases where the classes are evenly balanced, the value is \(1−1/k\) . An alternative measure is the entropy \(E(N)\): \[E(N) = - \sum_{i=1}^k pi · log(pi) \tag{5}\]
The value of the entropy lies between \(0\) and \(log(k)\). The value is \(log(k)\), when the records are perfectly balanced among the different classes. This corresponds to the scenario with maximum entropy. The smaller the entropy, the greater the skew in the data. Thus, the gini-index and entropy provide an effective way to evaluate the quality of a node in terms of its level of discrimination between the different classes.
Note that with decision tree, we refer here to classification tree and not regression tree, since the outcome we want to predict is a categorical variable.
In our study, we built our classification tree model on the training set using the rpart function of the rpart package. By default, rpart() function uses the Gini impurity measure to split the node. The higher the Gini coefficient, the more different instances within the node. We predicted the fitted tree on the test set with the predict() function. Major explanations of Recursive Partitioning Using the rpart Routines are given in Therneau & Atkinson (2018).
4.1.3.
Random forests
Random Forest can be regarded as a variant of Bagging approach. It follows the major steps of Bagging and uses decision tree algorithm to build base classifiers. Besides Bootstrap sampling and majority voting used in Bagging, Random Forest further incorporates random feature space selection into training set construction to promote base classifiers’ diversity.
Random Forest algorithm builds multiple decision trees following the summarized algorithm below and takes majority voting of the prediction results of these trees. To incorporate diversity into the trees, Random Forest approach differs from the traditional decision tree algorithm in the following aspects when building each tree: First, it infers the tree from a Bootstrap sample of the original training set. Second, when selecting the best feature at each node, Random Forest only considers a subset of the feature space. These two modifications of decision tree introduce randomness into the tree learning process, and thus increase the diversity of base classifiers. In practice, the dimensionality of the selected feature subspace \(n'\) controls the randomness. If we set \(n' = n\) where \(n\) is the original dimensionality, then the constructed decision tree is the same as the traditional deterministic one. If we set \(n' = 1\), at each node, only one feature will be randomly selected to split the data, which leads to a completely random decision tree.
Specifically, the following describes the general procedure of Random Forest algorithm:

random forest algorithm
In our study, we used the randomForest() function of the randomForest package which implements Breiman’s random forest algorithm (based on Breiman and Cutler’s original Fortran code), to build our random forest models on training set . Then , we predicted the latter model on test set with the predict() function.
4.1.4.
Support Vector Machines
SVM methods use linear conditions in order to separate out the classes from one another. The idea is to use a linear condition that separates the two classes from each other as well as possible. SVMs were developed by Cortes & Vapnik (1995) for binary classification. Their approach may be roughly sketched with the following tasks : Class separation, Overlapping classes, Nonlinearity and Problem solution which is a quadratic optimization problem.
The principal task, Class separation, lies in looking for the optimal separating hyperplane between the two classes by maximizing the margin between the classes’ closest points (see Figure below)—the points lying on the boundaries are called support vectors, and the middle of the margin is our optimal separating hyperplane. For further details, follow Meyer and Wien(2015) or Karatzoglou et al (2005).
The package e1071 offers an interface to the award-winning C++- implementation by Chang & Lin(2001), libsvm
In our study, we used the svm() function of that package, which was designed to be as intuitive as possible (we also compared with results of ksvm() function of the kernlab package). Models are fitted on the training set and predicted on unseen data(test set) as usual.
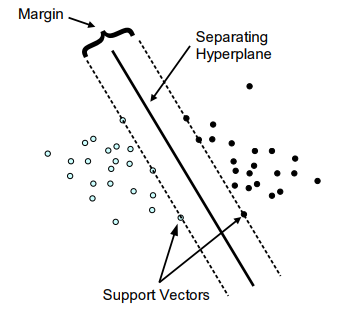
SVM Classification (linear separable case)
4.1.5.
Neural Networks
An artificial neural network (ANN) or neural net is a graph of connected units representing a mathematical model of biological neurons. Those units are sometimes referred to as processing units, nodes, or simply neurons. The units are connected through unidirectional or bidirectional arcs with weights representing the strength of the connections between units. This is inspired from the biological model in which the connection weights represent the strength of the synapses between the neurons, inhibiting or facilitating the passage of signals.
The artificial neuron, as illustrated in Figure x, is a computational engine that transforms a set of inputs \(x = (x_1, · · · ,x_d)\) into a single output \(o\) using a composition of two functions as follows:
A net value function \(ξ\), which utilizes the unit’s parameters or weights \(w\) to summarize input data into a net value, \(ν\), as \(ν = ξ(x,w)\) . The net value function mimics the behavior of a biological neuron as it aggregates signals from linked neurons into an internal representation. Typically, it takes the form of a weighted sum, a distance, or a kernel.
An activation function, or squashing function, \(φ\), that transforms net value into the unit’s output value \(o\) as \(o = φ(ν)\). The activation function simulates the behaviour of a biological neuron as it decides to fire or inhibit signals, depending on its internal logic. The output value is then dispatched to all receiving units as determined by the underlying topology. Various activations have been proposed.The most widely-used ones include the linear function, the step or threshold function, and the sigmoid and hyperbolic tangent function.
Mathematical model of an ANN unit
Generally we distinguish two types of neural networks : single and multilayer neural networks. The following figures are taken from Aggarwal(2014)
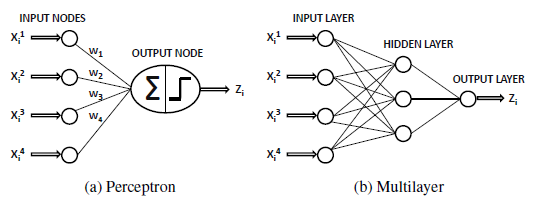
Single and multilayer neural networks.
In our study, we principally used the nnet package by Ripley et al(2016) . We also took into account the NeuralNetTools(Visualization and Analysis Tools for Neural Networks) and neuralnet packages. For a more in-depth view on the exact workings of the neuralnet package, see neuralnet: Training of Neural Networks by F. Günther and S. Fritsch. For the methods in NeuralNetTools, see here. As in Soni & Abdullahi(2015), we built our neural network model on training set; however using the nnet() function instead of neuralnet() function . We predicted the fitted model on test set with the predict() function.
4.1.6.
Lasso regression
Lasso, or Least Absolute Shrinkage and Selection Operator, is quite similar conceptually to ridge regression. It also adds a penalty for non-zero coefficients, but unlike ridge regression which penalizes sum of squared coefficients (the so-called L2 penalty), lasso penalizes the sum of their absolute values (L1 penalty). As a result, for high values of \(λ\), many coefficients are exactly zeroed under lasso, which is never the case in ridge regression.
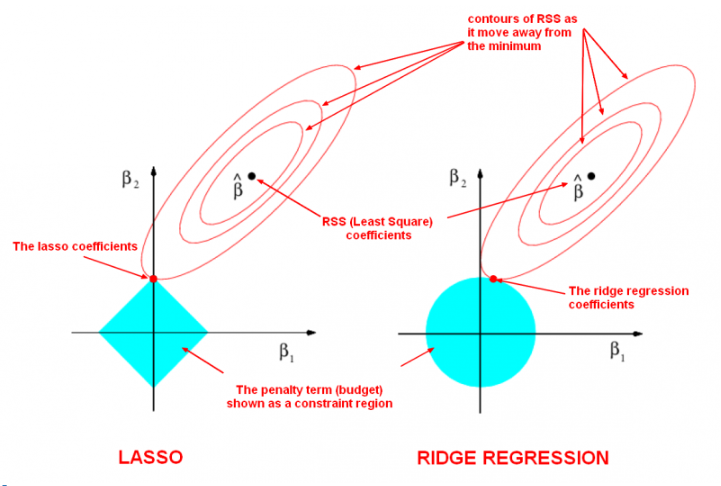
lasso vs ridge regression
Model specification: The only difference in ridge and lasso loss functions is in the penalty terms. Under lasso, the loss is defined as: \[L_{lasso}(\hat{\beta}) = \sum_{i=1}^n(y_{i} - x'_{i}\hat{\beta} ) + \lambda \sum_{i=1}^n |\hat{\beta} | \tag{6}\] Major details are given in the paper of Tibshirani(1996) , or read more here
In our study, we used the glmnet functions of the glmnet package to fit our lasso regression model. Then , we predicted our fitted model on test set. glmnet solves the following problem \[\min_{\beta_0,\beta} \frac{1}{N} \sum_{i=1}^{N} w_i l(y_i,\beta_0+\beta^T x_i) + \lambda\left[(1-\alpha)||\beta||_2^2/2 + \alpha ||\beta||_1\right]\] , over a grid of values of \(λ\) covering the entire range. Here \(l(y,η)\) is the negative log-likelihood contribution for observation i; e.g. for the Gaussian case it is \(\frac{1}{2}(y−η)^2\). The elastic-net penalty is controlled by \(α\), and bridges the gap between lasso (\(α=1\), the default) and ridge (\(α=0\)). The tuning parameter \(λ\) controls the overall strength of the penalty.
4.2. Model performance evaluation
A classification model gives a predicted class for every case in the test data set, the actual class of each of them is known. The confusion matrix provides a convenient way to compare the frequencies of actual versus predicted class for the test data set. Two-class problem is the most common situation in credit scoring. The credit customers are usually classified into two classes: ‘good’ and ‘bad’ (or ‘accepted’ and’rejected’, ‘default’ and ‘non-default’)(Liu,2002). The format of confusion matrix for two-class problem is shown in the following table from Wang et al (2011).
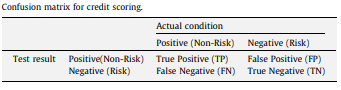
where \[ Accuracy = \frac{TP +TN}{\ TP + FP + FN + TN} \tag{7}\] \[TPR (sensitivy\ , or \ true \ positive \ rate ) = \frac{TP}{\ TP + FN} = 1 - FNR \tag{8} \] where FNR(false negative rate is Type I error ) , \(FNR = \frac{FN}{\ FN + TP}\) \[TNR (specificity\, or \ true \ negative \ rate ) = \frac{TN}{\ TN + FP} = 1 - FPR \tag{9}\] where FPR(false positive rate is Type II error) , \(FPR = \frac{FP}{\ FP + TN}\) \[Precision = \frac{TP}{\ TP + FP} \tag{10}\] \[Recall = \frac{TP}{\ TP + FN} \tag{11}\]
Moreover, always following Liu(2002), we defined another evaluation criteria: ROC curve. In statistics, a receiver operating characteristic (ROC), or ROC curve, is a graphical plot that illustrates the performance of a binary classifier system as its discrimination threshold is varied. The curve is created by plotting the true positive rate (TPR) against the false positive rate (FPR) at various threshold settings. A measure is given by the area under the ROC curve (denoted as AUC). The curve that has a larger AUC is better than the one that has a smaller AUC (Bock,2001). As in Hand & Till (2001) ,it can be show that the AUC is related to the Gini coefficient \(({\displaystyle G_{1}})\) by the formula \({\displaystyle G_{1}=2{\mbox{AUC}}-1} G_{1}=2{\mbox{AUC}}-1\) , where: \[{\displaystyle G_{1}=1-\sum _{k=1}^{n}(X_{k}-X_{k-1})(Y_{k}+Y_{k-1})} \tag{12}\] In our study, for each predicted model on test set,we used the confusionMatrix() function of the caret package to get values of Accuracy, sensitivity and specicifity and other metrics . We plotted ROC curves and Recall/precision curves using the ROCR package.
V. Results
5.1. Identifying the best model
5.1.1.
Logistic Regression Models
#fit glm model on training set
set.seed(1)
reg_model <- glm(formula= Risk ~ . , data=train, family="binomial")
#summary of the results of fitted logistic regression model
summary(reg_model)
Call:
glm(formula = Risk ~ ., family = "binomial", data = train)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.6584 -0.6519 0.3478 0.6902 2.2646
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.117e-01 1.091e+00 -0.194 0.846121
check_acct0.to.200 3.815e-01 2.708e-01 1.409 0.158861
check_acctgt.200 8.285e-01 4.153e-01 1.995 0.046079 *
check_acctnone 1.885e+00 2.880e-01 6.543 6.03e-11 ***
credit_histThisBank.AllPaid -2.089e-01 6.264e-01 -0.334 0.738718
credit_histPaidDuly 8.487e-01 4.681e-01 1.813 0.069833 .
credit_histDelay 1.861e+00 5.900e-01 3.154 0.001609 **
credit_histCritical 1.465e+00 4.971e-01 2.946 0.003220 **
Duration -2.286e-02 1.096e-02 -2.085 0.037098 *
savings_acct100.to.500 -1.165e-01 3.600e-01 -0.324 0.746155
savings_acct500.to.1000 5.297e-01 5.111e-01 1.036 0.299982
savings_acctgt.1000 1.307e+00 6.388e-01 2.047 0.040677 *
savings_acctUnknown 6.274e-01 3.116e-01 2.014 0.044045 *
PurposeUsedCar 2.087e+00 4.611e-01 4.527 5.99e-06 ***
PurposeFurniture.Equipment 1.124e+00 3.234e-01 3.476 0.000508 ***
PurposeRadio.Television 8.793e-01 3.025e-01 2.907 0.003653 **
PurposeDomesticAppliance 6.807e-01 9.890e-01 0.688 0.491295
PurposeRepairs -4.738e-01 6.437e-01 -0.736 0.461716
PurposeEducation 1.398e-01 4.636e-01 0.302 0.763003
PurposeRetraining 2.168e+00 1.229e+00 1.764 0.077771 .
PurposeBusiness 1.162e+00 4.244e-01 2.738 0.006186 **
PurposeOther 1.441e+00 8.382e-01 1.720 0.085511 .
Age 1.764e-02 1.107e-02 1.594 0.110991
PropertyInsurance -3.013e-01 3.070e-01 -0.982 0.326234
PropertyCarOther 1.288e-02 2.795e-01 0.046 0.963260
PropertyUnknown -5.114e-01 5.442e-01 -0.940 0.347397
Amount -1.540e-04 5.046e-05 -3.052 0.002271 **
present_emp1.to.4 1.087e-01 2.969e-01 0.366 0.714383
present_emp4.to.7 1.177e+00 3.887e-01 3.029 0.002453 **
present_empgt.7 3.926e-01 3.588e-01 1.094 0.273852
present_empUnemployed 1.227e-01 4.705e-01 0.261 0.794345
HousingOwn 4.664e-01 2.728e-01 1.710 0.087323 .
HousingForFree 5.462e-01 5.989e-01 0.912 0.361745
other_installStores 2.697e-01 4.940e-01 0.546 0.585065
other_installNone 6.898e-01 2.931e-01 2.354 0.018589 *
status_sexFemale.NotSingle 4.855e-01 4.502e-01 1.078 0.280838
status_sexMale.Single 8.701e-01 4.394e-01 1.980 0.047690 *
status_sexMale.Married.Widowed 4.273e-01 5.258e-01 0.813 0.416434
ForeignWorkeryes -2.082e+00 7.551e-01 -2.758 0.005821 **
other_debtCoApplicant -7.713e-01 5.125e-01 -1.505 0.132291
other_debtGuarantor 1.213e+00 5.359e-01 2.263 0.023606 *
installment_rate -3.064e-01 1.067e-01 -2.872 0.004085 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 855.21 on 699 degrees of freedom
Residual deviance: 609.24 on 658 degrees of freedom
AIC: 693.24
Number of Fisher Scoring iterations: 5The summary output of fitted reg_model shows that attributes such as check_acct, credit_hist, Purpose , Amount, ForeignWorkers, present_emp or installment_rate are strongly statistically significant with a p-value not only less than 0.05, but also 0.01. The Akaike information criterion (AIC), that is negative log likelihood penalized for a number of parameters, indicates a value equals to 693.24. Lower value of AIC suggests “better” model, but it is a relative measure of model fit. It is used for model selection, i.e. it lets you to compare different models estimated on the same dataset. AIC is useful for comparing models, but it does not tell you anything about the goodness of fit of a single, isolated model. Read more here
#Calculation of variable importance for glm model with repeated 10 folds cross-validation ,
control <- trainControl(method="repeatedcv", number=10, repeats=2)
model_reg <- train(Risk ~ ., data=train, method="glm",
trControl=control)
importance <- varImp(model_reg, scale=FALSE)
plot(importance)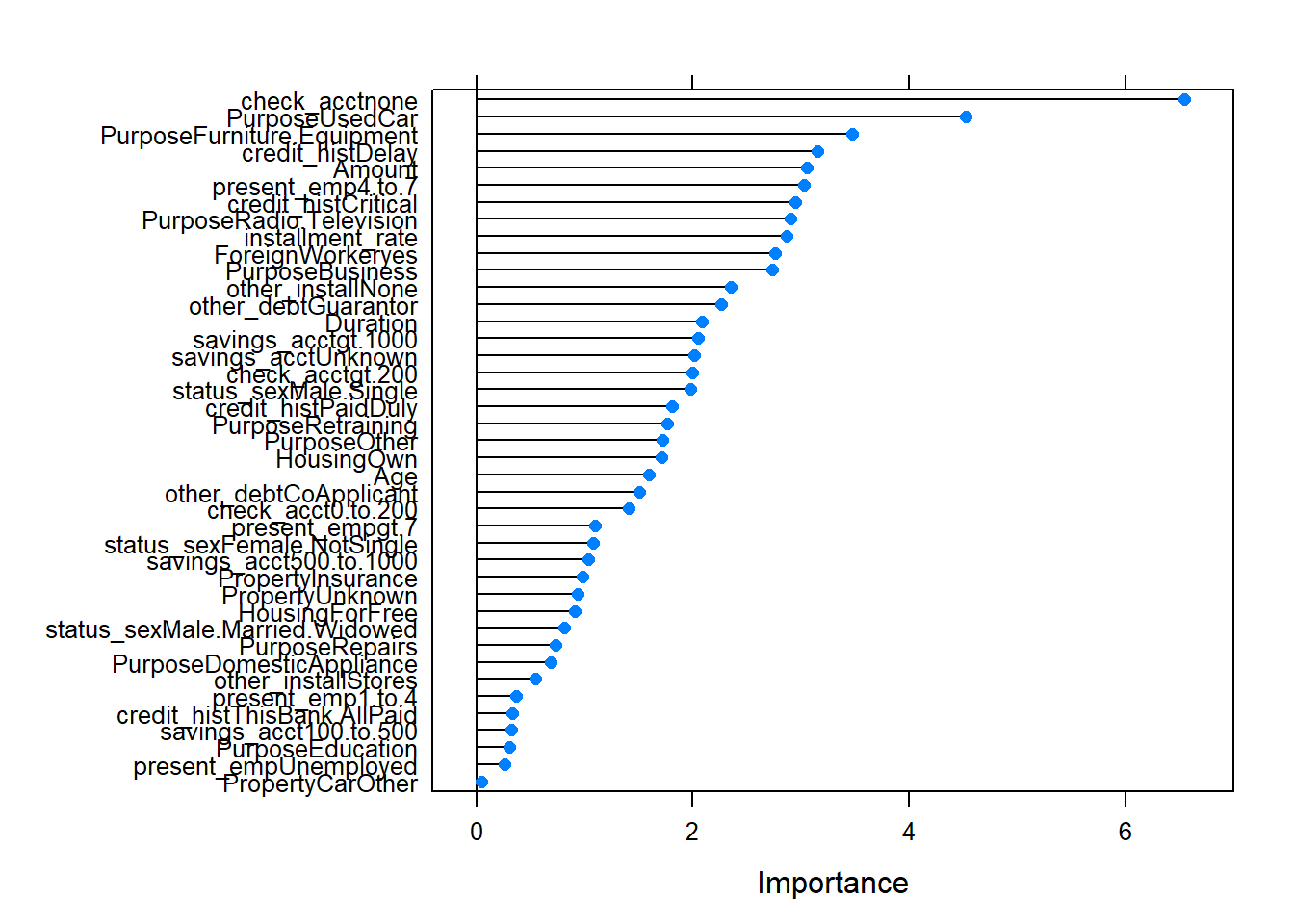
The top 5 important predictors according to the glm model are: check_acct ,Purpose , credit_hist , Amount and present_emp. We also noticed how these predictors are part of the list of statistically significant attributes ( see summary(reg_model)) . We used them to fit a new logistic regression model based on the same training set.
#fit new glm model on training set
set.seed(1)
reg_model.new <- glm(formula= Risk ~ check_acct + Purpose + credit_hist + Amount + present_emp, data=train, family="binomial")
summary(reg_model.new)
Call:
glm(formula = Risk ~ check_acct + Purpose + credit_hist + Amount +
present_emp, family = "binomial", data = train)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.5463 -0.8206 0.4263 0.7722 2.1471
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.400e+00 5.356e-01 -2.615 0.008930 **
check_acct0.to.200 4.876e-01 2.385e-01 2.045 0.040898 *
check_acctgt.200 1.091e+00 3.862e-01 2.825 0.004733 **
check_acctnone 1.919e+00 2.615e-01 7.341 2.13e-13 ***
PurposeUsedCar 1.841e+00 4.321e-01 4.260 2.04e-05 ***
PurposeFurniture.Equipment 7.747e-01 2.907e-01 2.664 0.007712 **
PurposeRadio.Television 5.425e-01 2.683e-01 2.022 0.043173 *
PurposeDomesticAppliance 5.961e-01 9.202e-01 0.648 0.517100
PurposeRepairs -4.907e-01 5.981e-01 -0.820 0.411946
PurposeEducation -3.794e-01 4.239e-01 -0.895 0.370829
PurposeRetraining 1.784e+00 1.155e+00 1.545 0.122401
PurposeBusiness 5.662e-01 3.797e-01 1.491 0.135962
PurposeOther 8.496e-01 7.965e-01 1.067 0.286097
credit_histThisBank.AllPaid -2.097e-01 5.697e-01 -0.368 0.712751
credit_histPaidDuly 9.276e-01 4.444e-01 2.087 0.036856 *
credit_histDelay 1.746e+00 5.597e-01 3.119 0.001813 **
credit_histCritical 1.632e+00 4.752e-01 3.434 0.000594 ***
Amount -1.692e-04 3.803e-05 -4.449 8.61e-06 ***
present_emp1.to.4 4.144e-01 2.633e-01 1.574 0.115578
present_emp4.to.7 1.250e+00 3.524e-01 3.547 0.000389 ***
present_empgt.7 6.436e-01 2.971e-01 2.167 0.030271 *
present_empUnemployed 2.192e-01 4.314e-01 0.508 0.611309
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 855.21 on 699 degrees of freedom
Residual deviance: 675.98 on 678 degrees of freedom
AIC: 719.98
Number of Fisher Scoring iterations: 5reg_model seems to be a better model than reg_model.new , since this latter shows a AIC value equals to 719.98 . Now, we are going to predict our fitted models on test set , and calculate the confusion matrix for each of them.
#reg_model: predict on test set
reg_predictions <- predict(reg_model, test, type="response")
reg_predictions <- round(reg_predictions) %>% factor()
cm_logreg.m1<-confusionMatrix(data= reg_predictions, reference=test$Risk, positive='0')
cm_logreg.m1Confusion Matrix and Statistics
Reference
Prediction 0 1
0 44 27
1 46 183
Accuracy : 0.7567
95% CI : (0.704, 0.8041)
No Information Rate : 0.7
P-Value [Acc > NIR] : 0.01741
Kappa : 0.3834
Mcnemar's Test P-Value : 0.03514
Sensitivity : 0.4889
Specificity : 0.8714
Pos Pred Value : 0.6197
Neg Pred Value : 0.7991
Prevalence : 0.3000
Detection Rate : 0.1467
Detection Prevalence : 0.2367
Balanced Accuracy : 0.6802
'Positive' Class : 0
#reg_model.new: predict on test set
reg_predictions.new <- predict(reg_model.new, test, type="response")
reg_predictions.new <- round(reg_predictions.new) %>% factor()
cm_logreg.m1_1 <- confusionMatrix(data=reg_predictions.new, reference=test$Risk, positive='0')
cm_logreg.m1_1Confusion Matrix and Statistics
Reference
Prediction 0 1
0 30 25
1 60 185
Accuracy : 0.7167
95% CI : (0.662, 0.767)
No Information Rate : 0.7
P-Value [Acc > NIR] : 0.2873596
Kappa : 0.2411
Mcnemar's Test P-Value : 0.0002262
Sensitivity : 0.3333
Specificity : 0.8810
Pos Pred Value : 0.5455
Neg Pred Value : 0.7551
Prevalence : 0.3000
Detection Rate : 0.1000
Detection Prevalence : 0.1833
Balanced Accuracy : 0.6071
'Positive' Class : 0
Based on the overall accuracy values, reg_model (0.7567) is a more precise model than reg_model.new (0.7167). Let’s define their performance to plot ROC curves , and calculate AUC values.
#Model performance plot
#define performance
reg_prediction.values <- predict(reg_model, test[,-16], type="response")
prediction_reg.model <- prediction(reg_prediction.values, test[,16])
reg_model.perf <- performance(prediction_reg.model,"tpr","fpr")
reg2_prediction.values <- predict(reg_model.new, test[,-16], type="response")
prediction_reg.modelnew <- prediction(reg2_prediction.values, test[,16])
reg2_model.perf <- performance(prediction_reg.modelnew,"tpr","fpr")#plot Roc curve
plot(reg_model.perf, lwd=2, colorize=TRUE, main="ROC curve, m1: Logistic Regression Performance")
lines(x=c(0, 1), y=c(0, 1), col="red", lwd=1, lty=3);
lines(x=c(1, 0), y=c(0, 1), col="green", lwd=1, lty=4)
plot(reg2_model.perf, lwd=2, colorize=TRUE, main="ROC curve, m1.1: Logistic Regression with selected variables")
lines(x=c(0, 1), y=c(0, 1), col="red", lwd=1, lty=3);
lines(x=c(1, 0), y=c(0, 1), col="green", lwd=1, lty=4)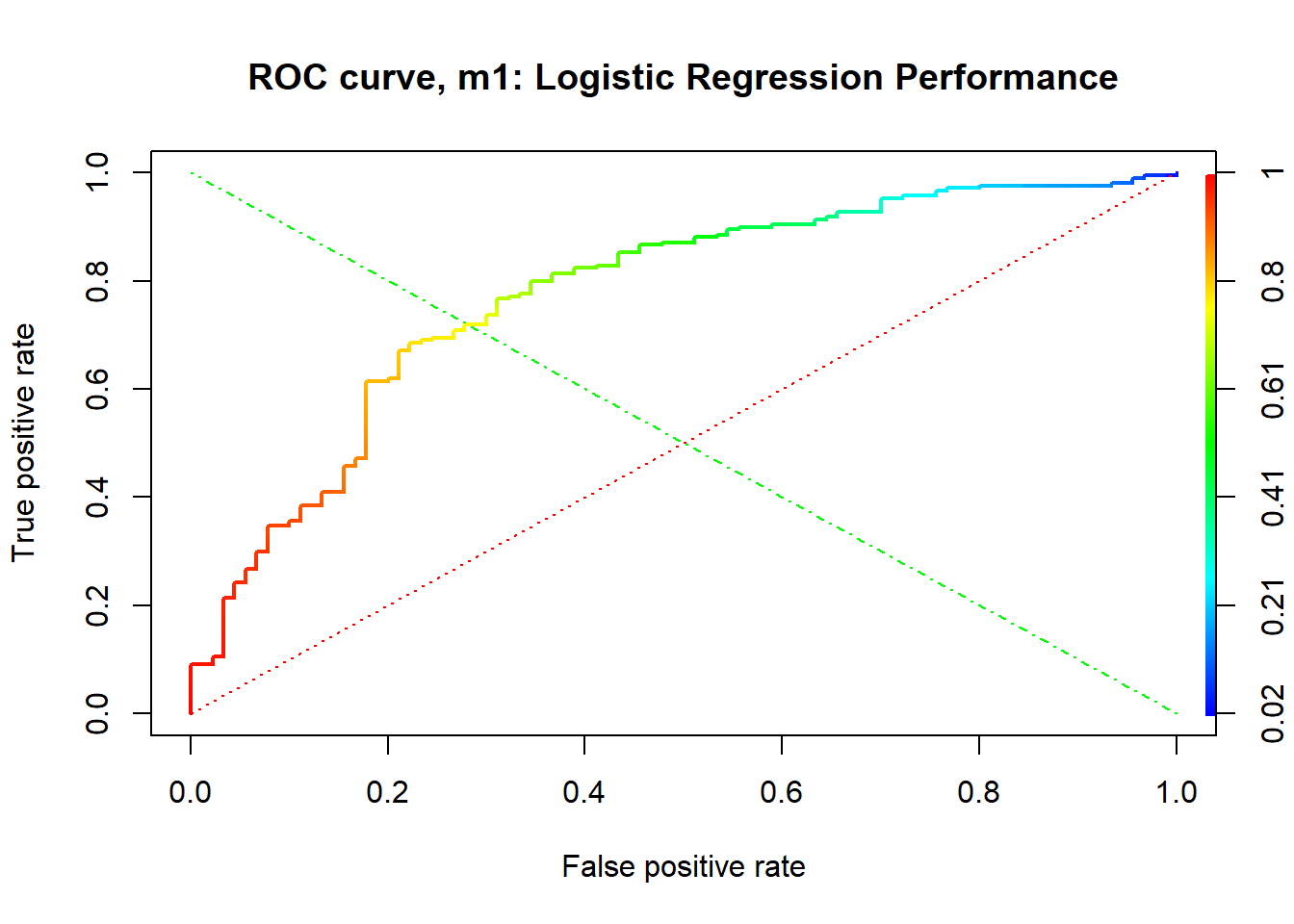
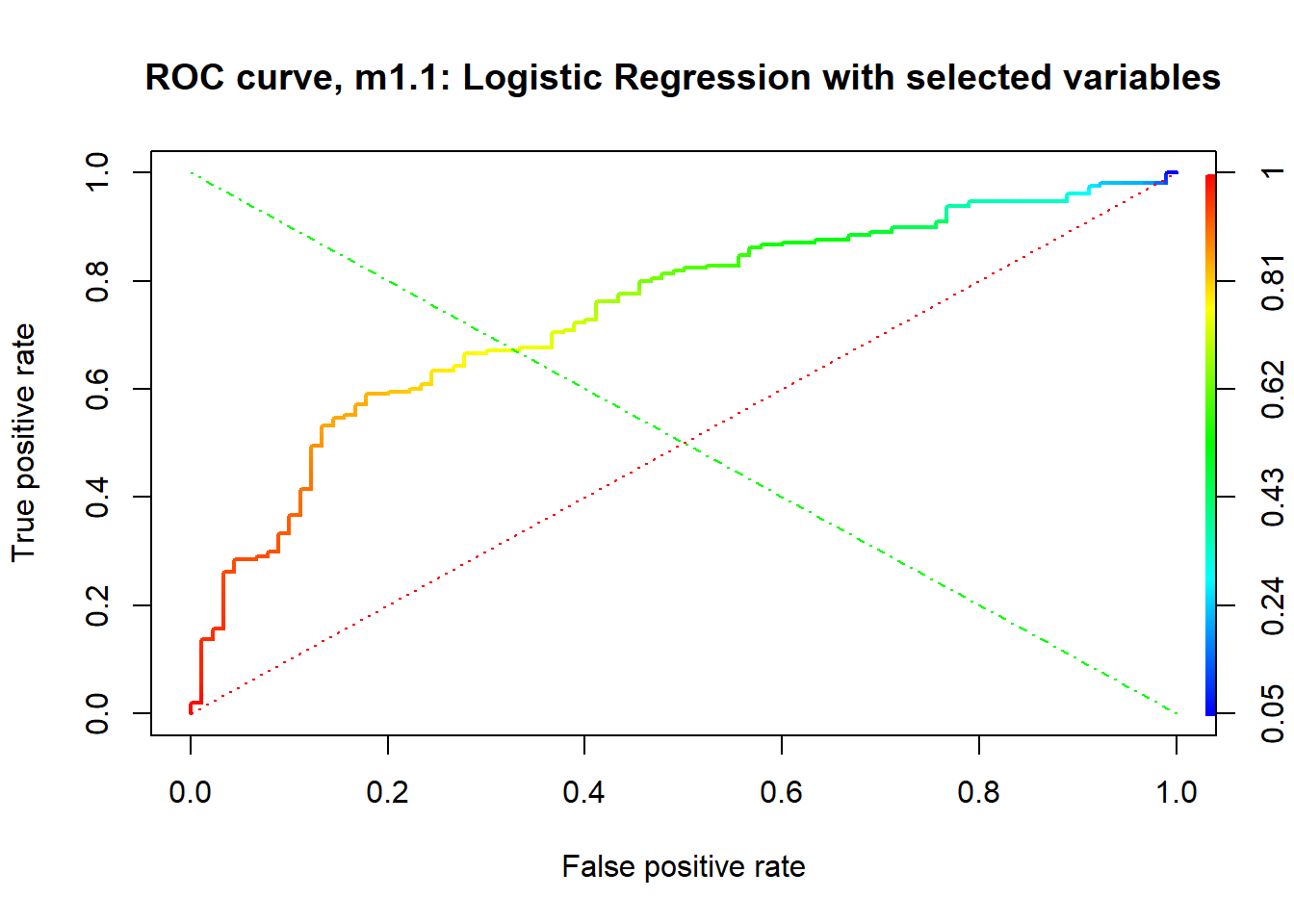
# Plot precision/recall curve
reg_model.precision <- performance(prediction_reg.model, measure = "prec", x.measure = "rec")
plot(reg_model.precision, main="m1 :Precision/recall curve")
reg2_model.precision <- performance(prediction_reg.modelnew , measure = "prec", x.measure = "rec")
plot(reg2_model.precision, main="m1.1 :Precision/recall curve")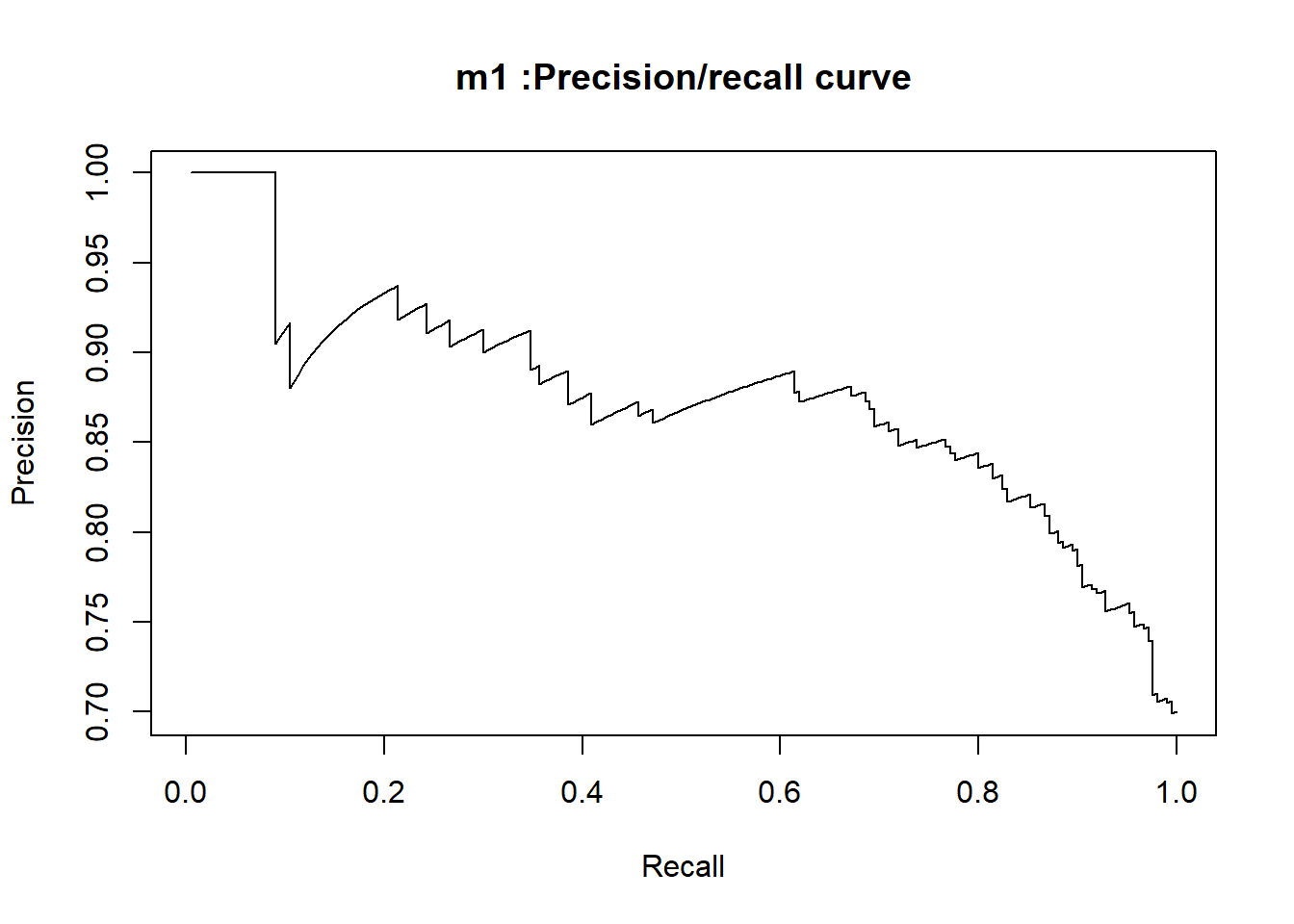
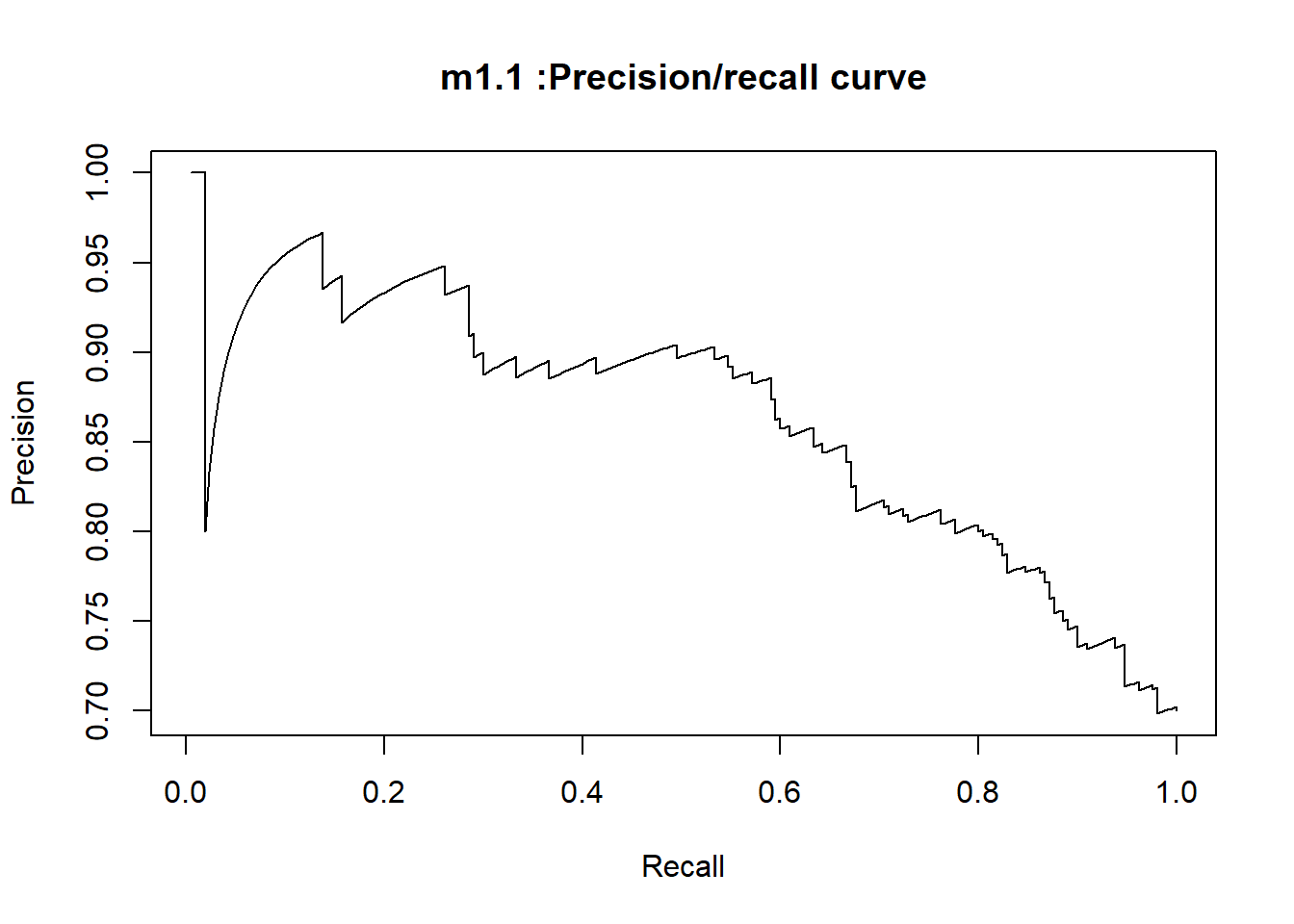
In addition, we see that “reg_model” points out an AUC value greater than the “reg_model.new” one.
#AUC : logistic regression model
reg_model.AUROC <- round(performance(prediction_reg.model, measure = "auc")@y.values[[1]], 4)
reg_model.AUROC 0.7741reg2_model.AUROC <- round(performance(prediction_reg.modelnew, measure = "auc")@y.values[[1]], 4)
reg2_model.AUROC 0.74085.1.2.
Decision trees
#fit decision tree model on training set using the rpart function
set.seed(1)
dt_model <- rpart(Risk~. , data=train, method ="class")
#we display CP table for Fitted Rpart Object
printcp(dt_model) Age Amount check_acct credit_hist Duration
[6] other_debt present_emp Purpose savings_acct
Root node error: 210/700 = 0.3
n= 700
CP nsplit rel error xerror xstd
1 0.050794 0 1.00000 1.00000 0.057735
2 0.014286 4 0.78095 0.93333 0.056569
3 0.012698 8 0.71905 0.94286 0.056744
4 0.010000 14 0.63333 0.93810 0.056656# Plot the rpart dt_model
prp(dt_model,type=2,extra=1, main="Tree:Recursive Partitioning")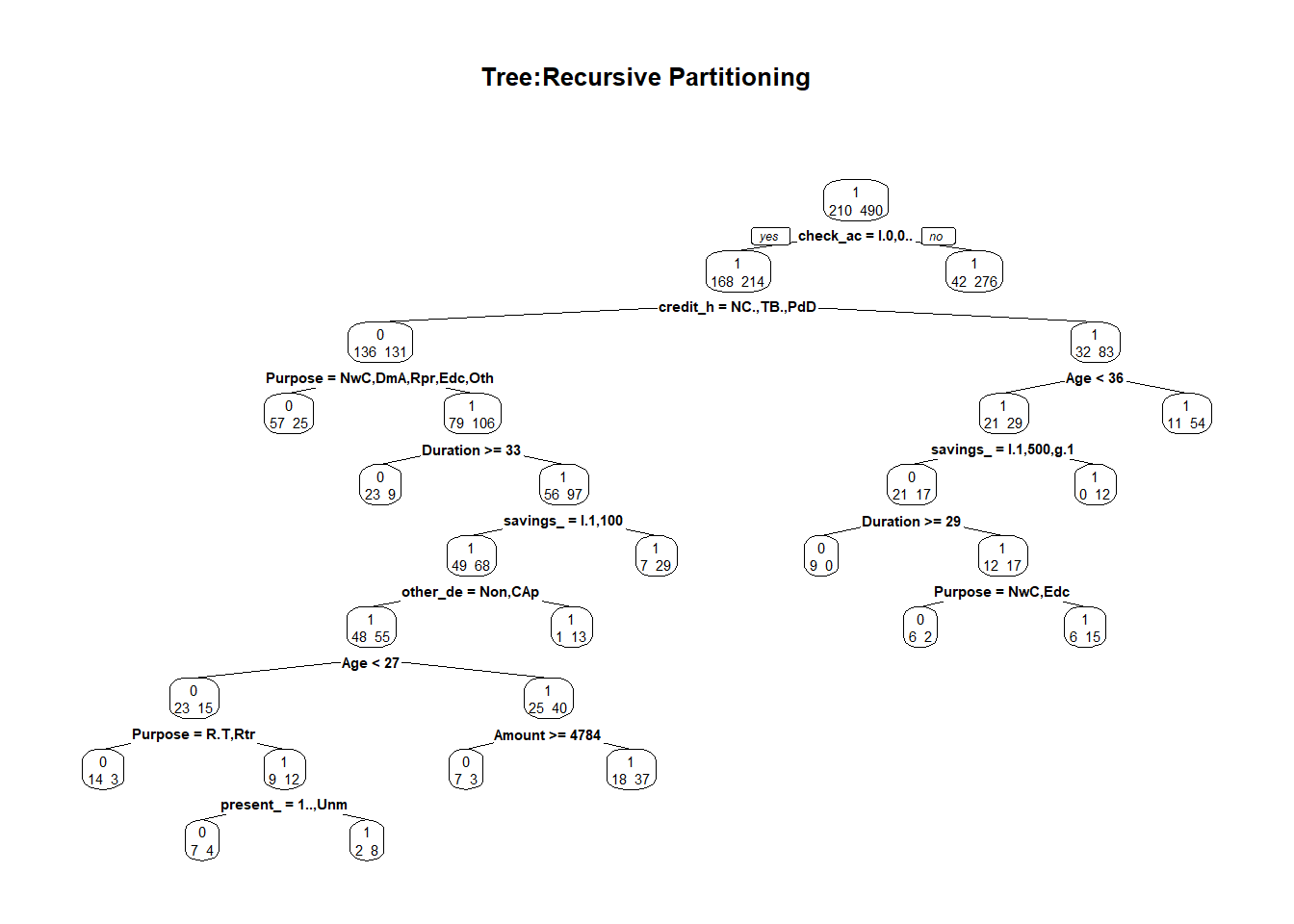
#A wrapper for plotting rpart trees using prp
fancyRpartPlot(dt_model)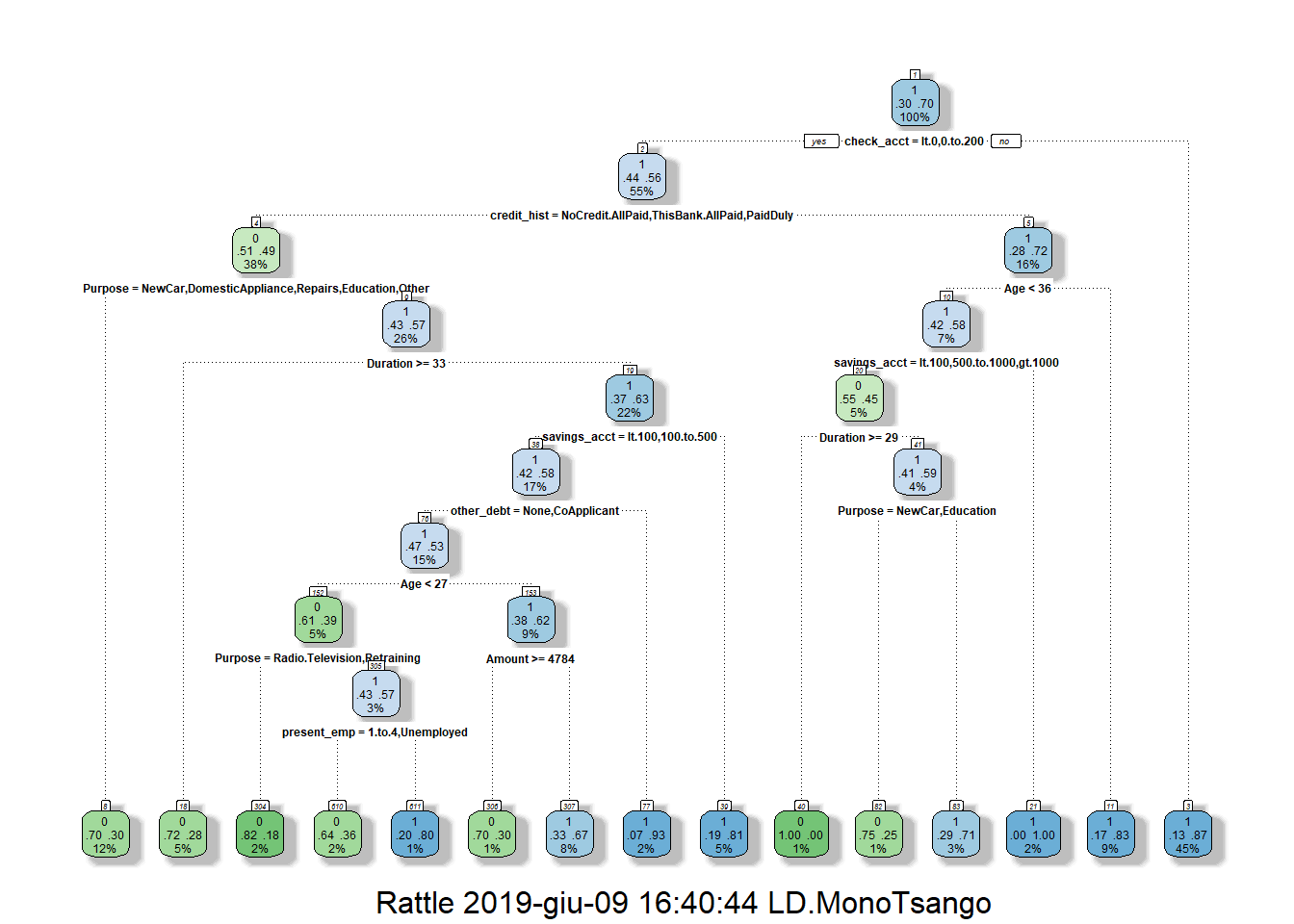
We observed that the tree fitted on the training set has has a root node, 13 splits and 14 leaves ( terminal nodes). We can also see values of CP: Internally, rpart keeps track of something called the complexity of a tree. The complexity measure is a combination of the size of a tree and the ability of the tree to separate the classes of the target variable. If the next best split in growing a tree does not reduce the tree’s overall complexity by a certain amount, rpart will terminate the growing process.
The rel error of each iteration of the tree is the fraction of mislabeled elements in the iteration relative to the fraction of mislabeled elements in the root. In this example, 30% of training cases have bad credit risk (see root node error). The cross validation error rates and standard deviations are displayed in the columns xerror and xstd respectively. According to our rpart plots, Our fitted model suggests that Check_acct is the best attribute to classify credit worthiness of applicants.
#predict on test set
set.seed(1)
dt_predictions <- predict(dt_model, test[,-16], type="class")
cm_dtree.m2 <- confusionMatrix(data=dt_predictions, reference=test[,16], positive="0")
cm_dtree.m2Confusion Matrix and Statistics
Reference
Prediction 0 1
0 43 36
1 47 174
Accuracy : 0.7233
95% CI : (0.669, 0.7732)
No Information Rate : 0.7
P-Value [Acc > NIR] : 0.2072
Kappa : 0.3174
Mcnemar's Test P-Value : 0.2724
Sensitivity : 0.4778
Specificity : 0.8286
Pos Pred Value : 0.5443
Neg Pred Value : 0.7873
Prevalence : 0.3000
Detection Rate : 0.1433
Detection Prevalence : 0.2633
Balanced Accuracy : 0.6532
'Positive' Class : 0
Prediction on unseen data performed enough well with an overall accuracy of about 0.72 . However, it’s usually a good idea to prune a decision tree. Fully grown trees don’t perform well against data not in the training set because they tend to be over-fitted so pruning is used to reduce their complexity by keeping only the most important splits.
set.seed(1)
# prune by lowest cp
pruned.tree <- prune(dt_model,
cp = dt_model$cptable[which.min(dt_model$cptable[,"xerror"]),"CP"])
length(pruned.tree$frame$var[pruned.tree$frame$var == "<leaf>"]) 5#Displays CP table for Fitted pruned tree
printcp(pruned.tree) check_acct credit_hist Duration Purpose
Root node error: 210/700 = 0.3
n= 700
CP nsplit rel error xerror xstd
1 0.050794 0 1.00000 1.00000 0.057735
2 0.014286 4 0.78095 0.93333 0.056569#count the number of splits
length(grep("^<leaf>$" , as.character(pruned.tree$frame$var))) - 1 4From the rpart documentation, “An overall measure of variable importance is the sum of the goodness of split measures for each split for which it was the primary variable†.When rpart grows a tree it performs 10-fold cross validation on the data. The output of printcp(dt_model) show us a list of cp values. We selected the one having the least cross-validated error and used it to prune the tree, since the value of cp should be least, so that the cross-validated error rate is minimum. This corresponds to dt_model\(cptable[which.min(dt_model\)cptable[,“xerror”]),“CP”] , equals to 0.01. As we can observe, the pruned tree only keeps the 4 most important splits.
# Plot the rpart pruned.tree
prp(pruned.tree, type = 1, extra = 3, split.font = 2, varlen = -10)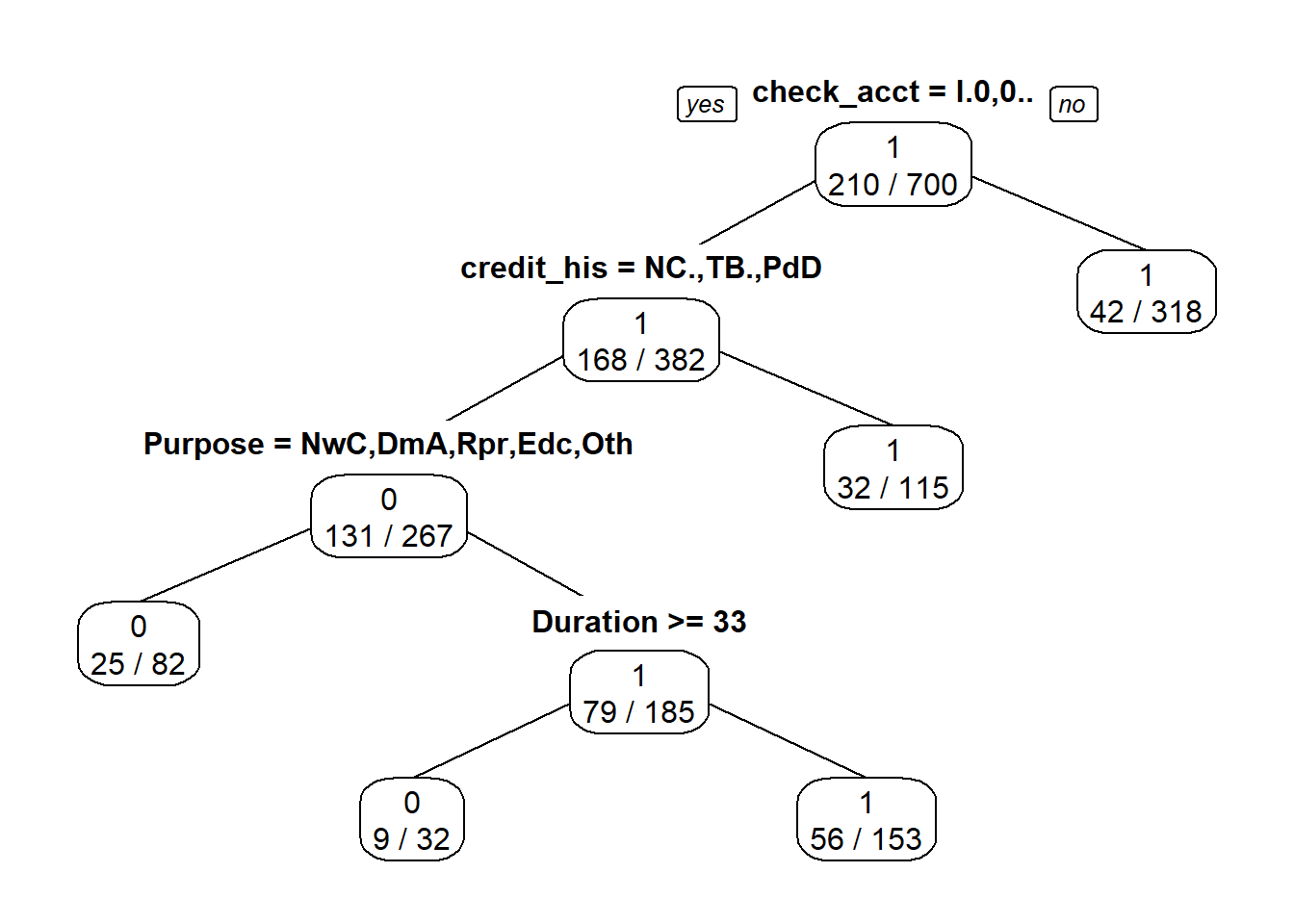
#A wrapper for plotting rpart trees using prp
fancyRpartPlot(pruned.tree)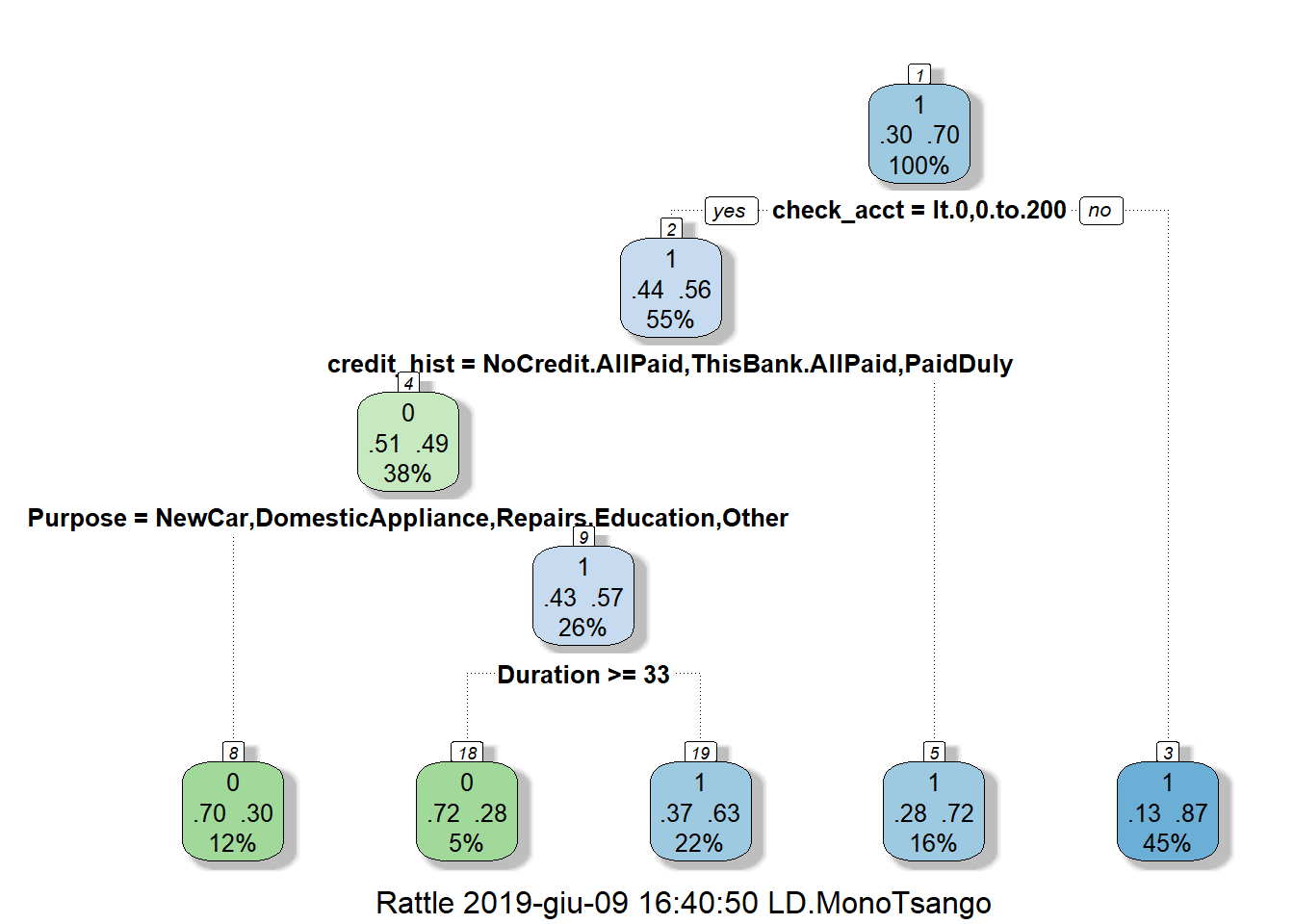
This is the situation after pruning : We observe how the tree keeps the important splits : a root node, 4 splits, and 5 terminal nodes. The first splitting criteria is “ check_acct = lt.0, 0.to.200â€, which separates the data into a set of 45 cases (which 39 have good credit worthiness and 6 , a bad one) and a set of 55 cases ( which 31 have a good credit risk and 24 a bad credit risk) . The latter have a further split based on criteria “Credit_hist : Notcredit.Allpaid, ThisBank.Allpaid, PaidDuly” " into two sets :a set of 16 cases (which 11 have a good credit risk, and 5 not ) , and a set of 38 cases (which 18 have a good credit risk, and almost 20 a bad one) . Again, this latter have a further split based on criteria “Purpose: NewCar, Domesticappliance,Repairs,Education,Other” where the 38 cases are separated into 26 (which 15 have a good credit profile and 11 a bad one ) cases and 12 cases( which 4 have a good credit risk and 8 a bad credit risk). The last splitting criteria based on “Duration > 33” separates these 26 cases (label9) into labels 18 and 19.
#prediction on test set
pruned_predictions <- predict(pruned.tree, test[,-16], type="class")
cm_dtree.m2_1 <- confusionMatrix(data=pruned_predictions, reference=test[,16], positive="0")
cm_dtree.m2_1Confusion Matrix and Statistics
Reference
Prediction 0 1
0 33 26
1 57 184
Accuracy : 0.7233
95% CI : (0.669, 0.7732)
No Information Rate : 0.7
P-Value [Acc > NIR] : 0.2072197
Kappa : 0.2694
Mcnemar's Test P-Value : 0.0009915
Sensitivity : 0.3667
Specificity : 0.8762
Pos Pred Value : 0.5593
Neg Pred Value : 0.7635
Prevalence : 0.3000
Detection Rate : 0.1100
Detection Prevalence : 0.1967
Balanced Accuracy : 0.6214
'Positive' Class : 0
#Model performance plot
#define performance
# score test data/model scoring for ROc curve - dt_model
dt_predictions.values <- predict(dt_model,test,type="prob")
dt_pred <- prediction(dt_predictions.values[,2],test$Risk)
dt_perf <- performance(dt_pred,"tpr","fpr")
# score test data/model scoring for ROc curve - pruned.tree
dt2_predictions.values <- predict(pruned.tree,test,type="prob")
dt2_pred <- prediction(dt2_predictions.values[,2],test$Risk)
dt2_perf <- performance(dt2_pred,"tpr","fpr")#plot Roc curve
plot(dt_perf, lwd=2, colorize=TRUE, main=" ROC curve : Decision tree performance")
lines(x=c(0, 1), y=c(0, 1), col="red", lwd=1, lty=3);
lines(x=c(1, 0), y=c(0, 1), col="green", lwd=1, lty=4)
plot(dt2_perf, lwd=2, colorize=TRUE, main="ROC curve : pruned tree performance")
lines(x=c(0, 1), y=c(0, 1), col="red", lwd=1, lty=3);
lines(x=c(1, 0), y=c(0, 1), col="green", lwd=1, lty=4)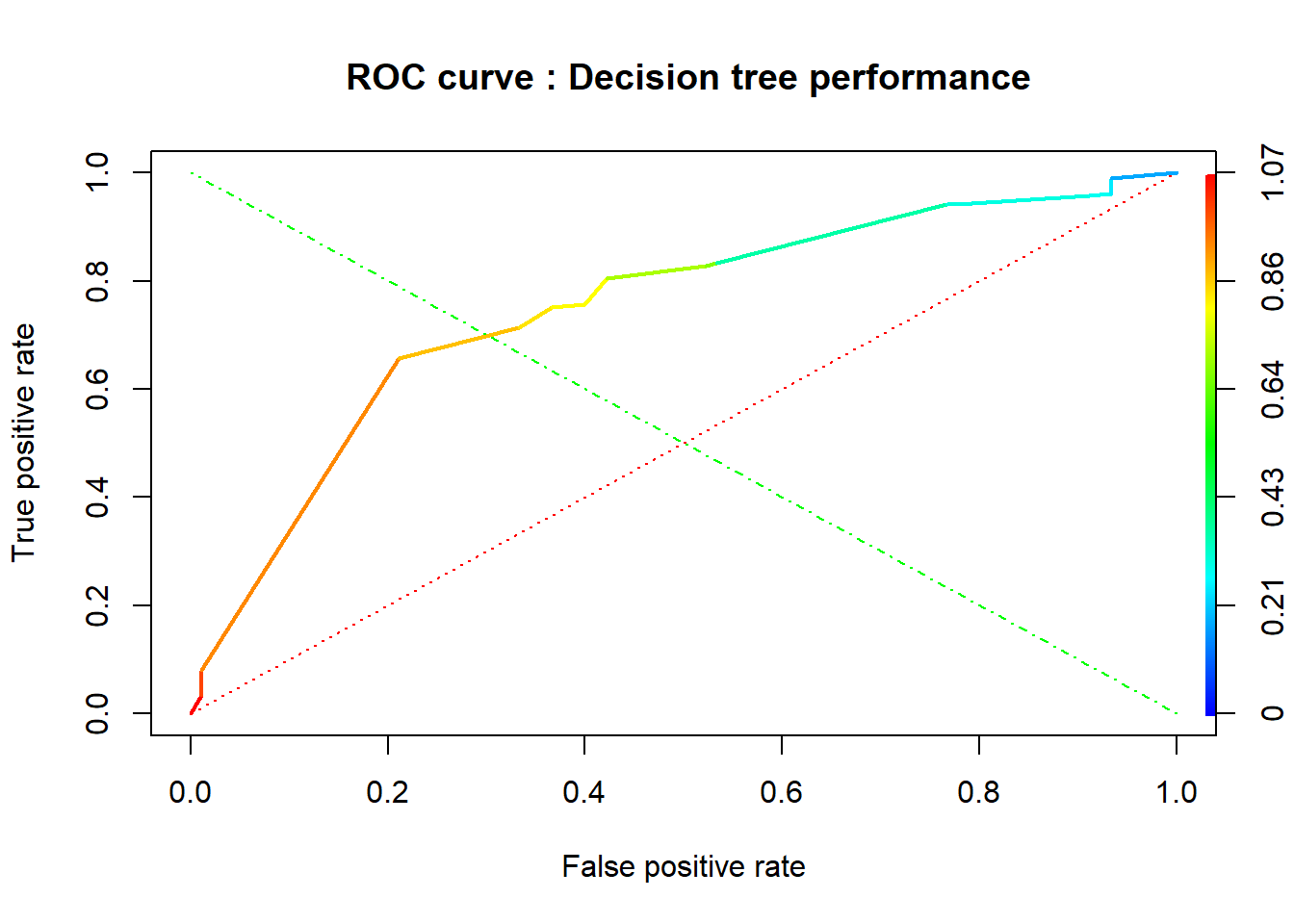
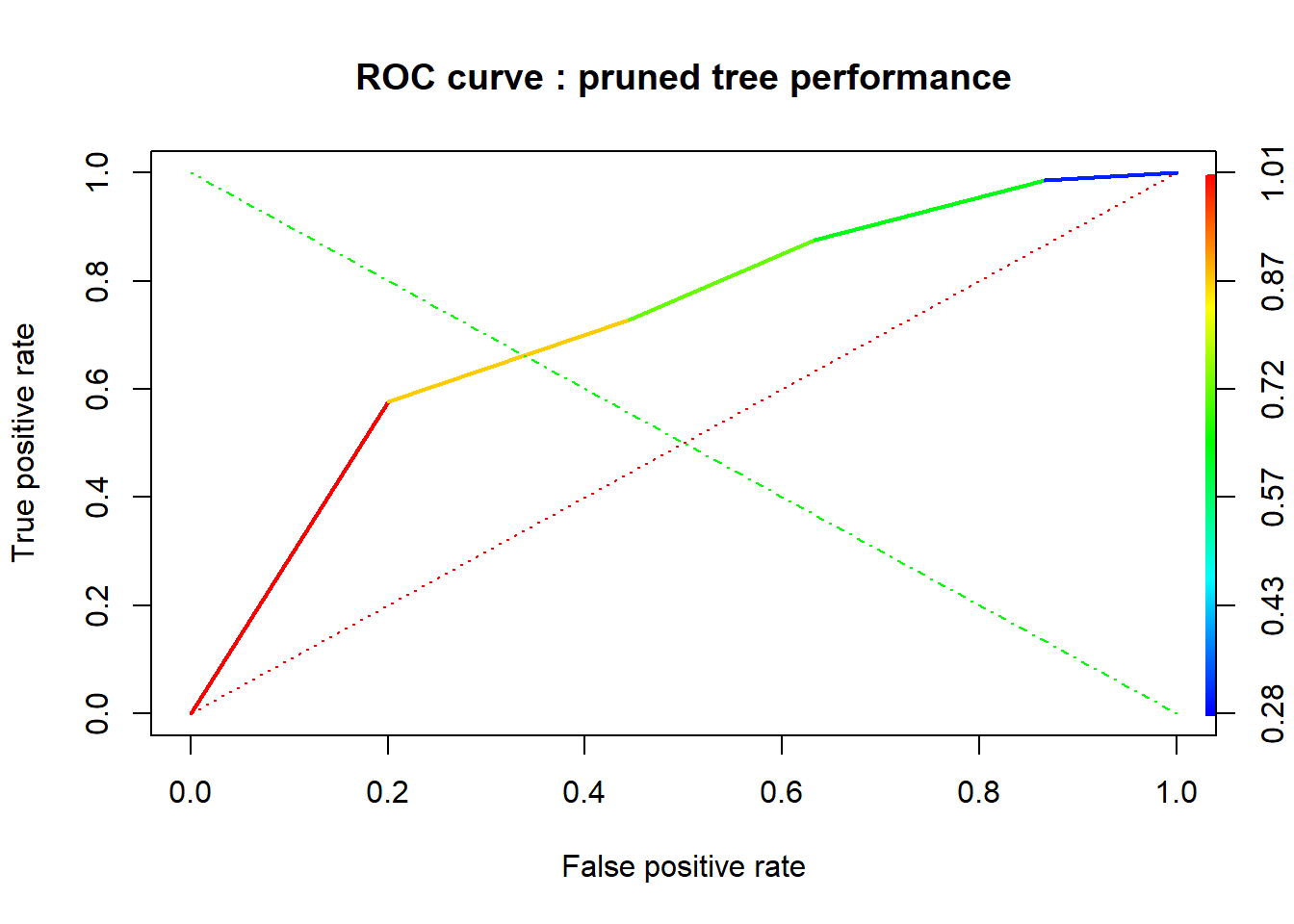
# Plot precision/recall curve
dt_perf_precision <- performance(dt_pred, measure = "prec", x.measure = "rec")
plot(dt_perf_precision, main="Decision tree :Precision/recall curve")
dt2_perf_precision <- performance(dt2_pred, measure = "prec", x.measure = "rec")
plot(dt2_perf_precision, main="pruned tree :Precision/recall curve")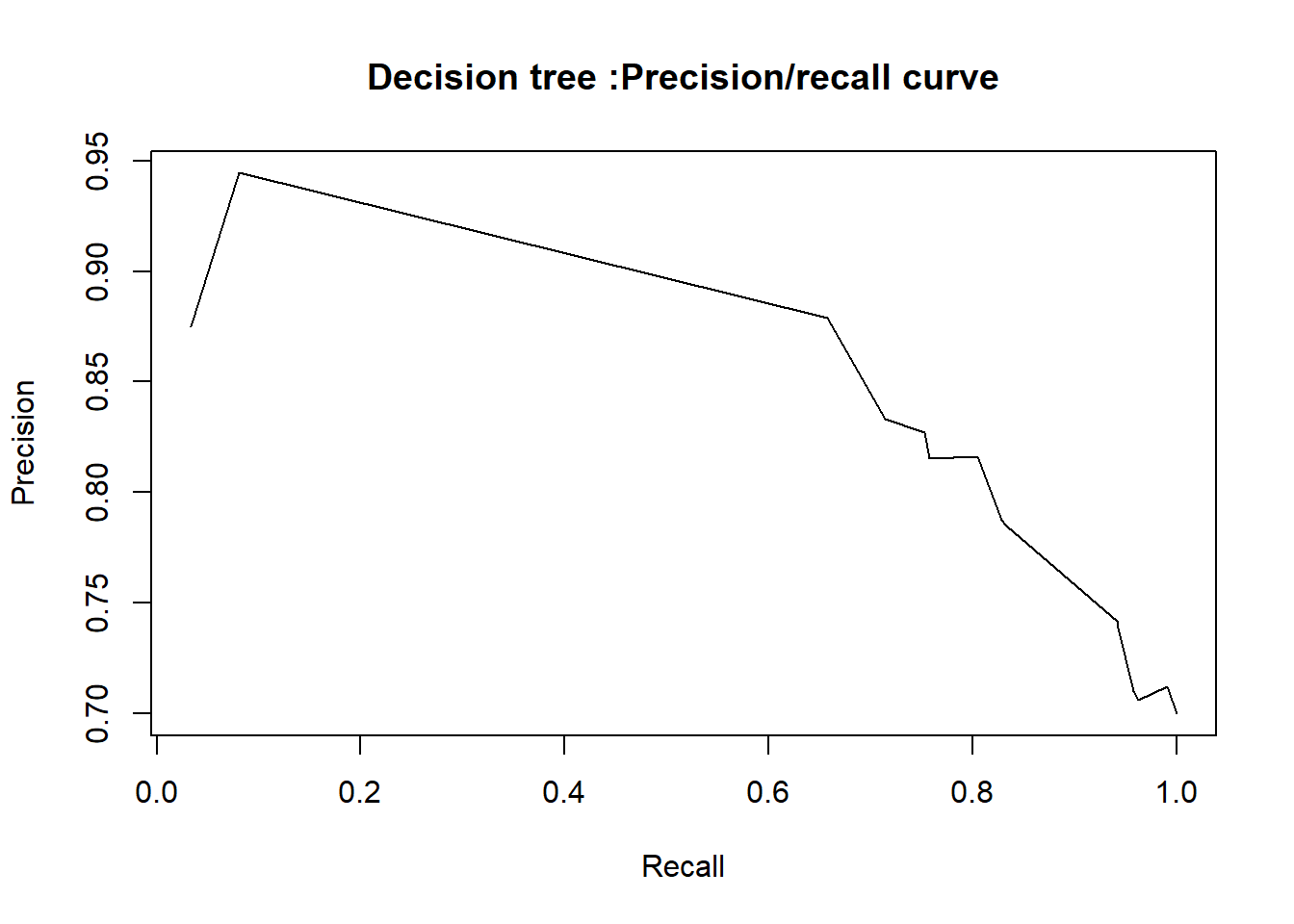

#AUC : Decision trees
dt_model.AUROC <- round(performance(dt_pred, measure = "auc")@y.values[[1]], 4)
dt_model.AUROC 0.7477dt2_model.AUROC <- round(performance(dt2_pred, measure = "auc")@y.values[[1]], 4)
dt2_model.AUROC 0.7183The two decision tree models seem to be equally accurate, since they have the same overall accuracy value. The discrimination through the balanced accuracy and AUC values help us to point out that “dt_model” is better than “pruned.tree” .
5.1.3.
random forests
#fit random forest model on training set using the randomForest function
set.seed(1)
rf_model <- randomForest(Risk ~ ., data = train,importance=TRUE)
# print random forest model
print(rf_model)
Call:
randomForest(formula = Risk ~ ., data = train, importance = TRUE)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 3
OOB estimate of error rate: 25.14%
Confusion matrix:
0 1 class.error
0 75 135 0.64285714
1 41 449 0.08367347Number of trees is 500 and number of variables tried at each split is 3 in this case. The nature of a random forest is it iteratively uses a different subset of the data (bootstrap aggregation) to make multiple decision trees. At each iteration, the tree created using the subset is tested with the data that is not used to create the tree. The average of errors of all these interactions is the Out of Bag Error or misclassification rate, in this case equals to 25.14% .
Let’s make prediction on test set.
#prediction on test set
rf_predictions <- predict(rf_model, test[,-16], type="class")
cm_rf.m3 <- confusionMatrix(data=rf_predictions, reference=test[,16], positive="0")
cm_rf.m3Confusion Matrix and Statistics
Reference
Prediction 0 1
0 37 13
1 53 197
Accuracy : 0.78
95% CI : (0.7288, 0.8256)
No Information Rate : 0.7
P-Value [Acc > NIR] : 0.001189
Kappa : 0.4
Mcnemar's Test P-Value : 1.582e-06
Sensitivity : 0.4111
Specificity : 0.9381
Pos Pred Value : 0.7400
Neg Pred Value : 0.7880
Prevalence : 0.3000
Detection Rate : 0.1233
Detection Prevalence : 0.1667
Balanced Accuracy : 0.6746
'Positive' Class : 0
We are going to try improving our random forest model with the important features through variable importance based on the MeanDecrease Gini.
#plot variable importance
varImpPlot(rf_model, main="Random Forest: Variable Importance")
# Get importance
importance <- randomForest::importance(rf_model)
varImportance <- data.frame(Variables = row.names(importance),
Importance = round(importance[ ,'MeanDecreaseGini'],2))
# Create a rank variable based on importance
rankImportance <- varImportance %>%
mutate(Rank = paste0('#',dense_rank(desc(Importance))))
# Use ggplot2 to visualize the relative importance of variables
ggplot(rankImportance, aes(x = reorder(Variables, Importance),
y = Importance, fill = Importance)) +
geom_bar(stat='identity') +
geom_text(aes(x = Variables, y = 0.5, label = Rank),
hjust=0, vjust=0.55, size = 4, colour = 'red') +
labs(x = 'Variables', title="random forest variable importance: MeanDecreaseGini") +
coord_flip() +
theme_few()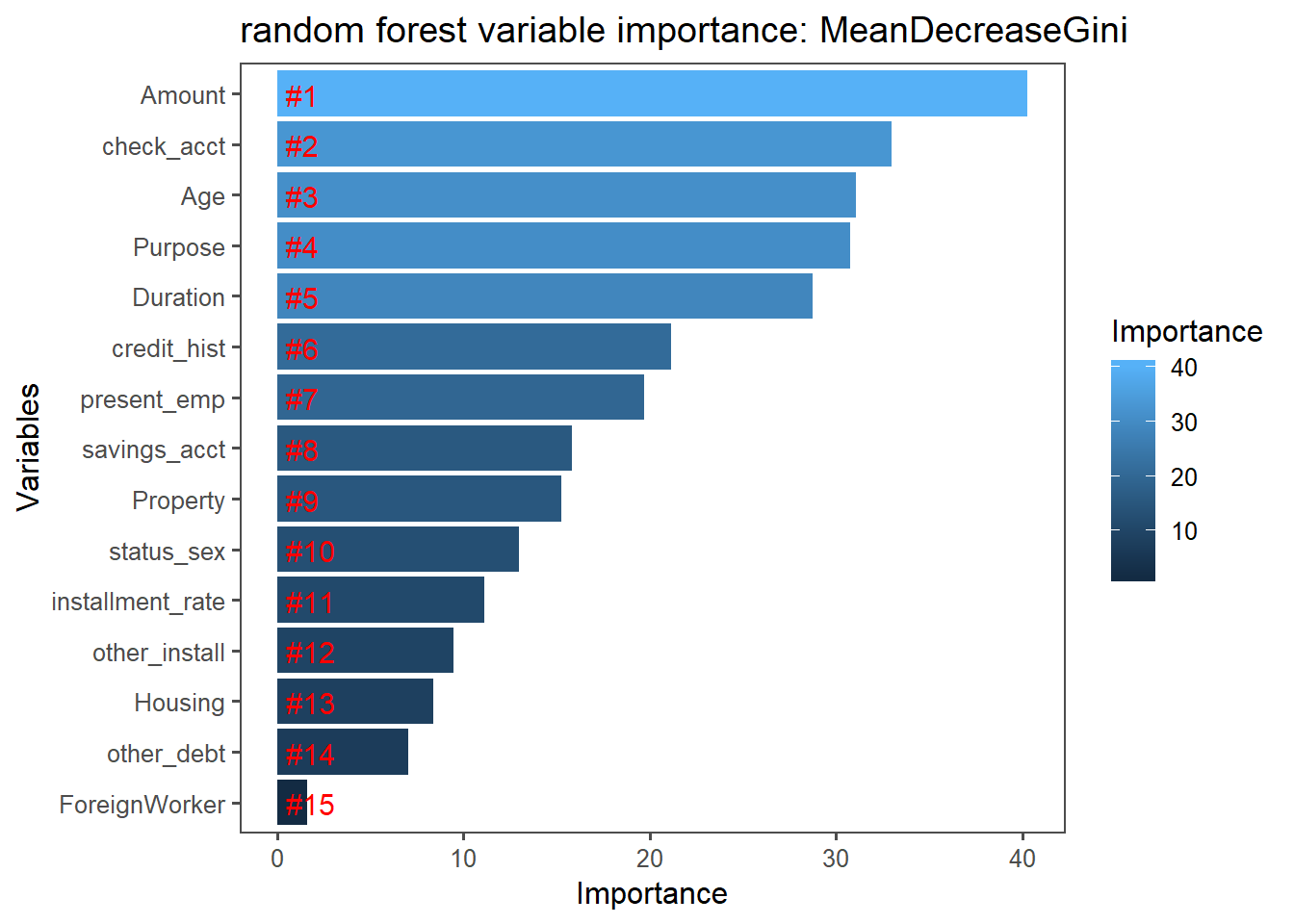
we built a new rf model (rf_model.new) with the 5 top variables based on MeanDecrease Gini
#fit new rf model
set.seed(1)
rf_model.new <- randomForest(Risk ~ Amount + check_acct + Age + Purpose + Duration ,
data = train,
importance=TRUE
)#prediction on test set
rf_predictions.new <- predict(rf_model.new, test[,-16], type="class")
cm_rf.m3_1 <- confusionMatrix(data=rf_predictions.new , reference=test[,16], positive="0")
cm_rf.m3_1Confusion Matrix and Statistics
Reference
Prediction 0 1
0 41 23
1 49 187
Accuracy : 0.76
95% CI : (0.7076, 0.8072)
No Information Rate : 0.7
P-Value [Acc > NIR] : 0.012488
Kappa : 0.3772
Mcnemar's Test P-Value : 0.003216
Sensitivity : 0.4556
Specificity : 0.8905
Pos Pred Value : 0.6406
Neg Pred Value : 0.7924
Prevalence : 0.3000
Detection Rate : 0.1367
Detection Prevalence : 0.2133
Balanced Accuracy : 0.6730
'Positive' Class : 0
Now we are going to tune/find the best parameters with 10-fold cross validation to build optimal random forest model
#tuning parameters with 10-fold cross validation - build optimal random forest model
set.seed(1)
nodesize.vals <- c(2, 3, 4, 5)
ntree.vals <- c(200, 500, 1000, 2000)
tuning.results <- tune.randomForest(Risk ~ ., data = train, mtry=3, nodesize=nodesize.vals, ntree=ntree.vals)
print(tuning.results)
Parameter tuning of 'randomForest':
- sampling method: 10-fold cross validation
- best parameters:
nodesize mtry ntree
4 3 500
- best performance: 0.2357143 #prediction on test set
rf_model.best <- tuning.results$best.model
rf_predictions.best <- predict(rf_model.best, test[,-16], type="class")
cm_rf.m3_2 <-confusionMatrix(data=rf_predictions.best, reference=test[,16], positive="0")
cm_rf.m3_2Confusion Matrix and Statistics
Reference
Prediction 0 1
0 38 13
1 52 197
Accuracy : 0.7833
95% CI : (0.7324, 0.8286)
No Information Rate : 0.7
P-Value [Acc > NIR] : 0.0007553
Kappa : 0.4112
Mcnemar's Test P-Value : 2.437e-06
Sensitivity : 0.4222
Specificity : 0.9381
Pos Pred Value : 0.7451
Neg Pred Value : 0.7912
Prevalence : 0.3000
Detection Rate : 0.1267
Detection Prevalence : 0.1700
Balanced Accuracy : 0.6802
'Positive' Class : 0
#Model performance plot
#define performance
# score test data/model scoring for ROc curve - rf_model
rf_predictions.values <- predict(rf_model,test,type="prob")
rf_pred <- prediction(rf_predictions.values[,2],test$Risk)
rf_perf <- performance(rf_pred,"tpr","fpr")
# score test data/model scoring for ROc curve - rf_model.new
model.new_predictions.values <- predict(rf_model.new,test,type="prob")
model.new_pred <- prediction(model.new_predictions.values[,2],test$Risk)
rf.new_perf <- performance(model.new_pred,"tpr","fpr")
# score test data/model scoring for ROc curve - rf_model.best
model.best_predictions.values <- predict(rf_model.best,test,type="prob")
model.best_pred <- prediction(model.best_predictions.values[,2],test$Risk)
rf.best_perf <- performance(model.best_pred,"tpr","fpr") Based on their overall accuracy values, we plot the ROC curves of potential best two models. (rf_model & rf_model.best)
#plot roc curves
#rf_model
plot(rf_perf, lwd=2, colorize=TRUE, main=" ROC curve : random forest performance ")
lines(x=c(0, 1), y=c(0, 1), col="red", lwd=1, lty=3);
lines(x=c(1, 0), y=c(0, 1), col="green", lwd=1, lty=4)
#rf_model.best
plot(rf.best_perf, lwd=2, colorize=TRUE, main="ROC curve: random forest - tuning parameters")
lines(x=c(0, 1), y=c(0, 1), col="red", lwd=1, lty=3);
lines(x=c(1, 0), y=c(0, 1), col="green", lwd=1, lty=4) 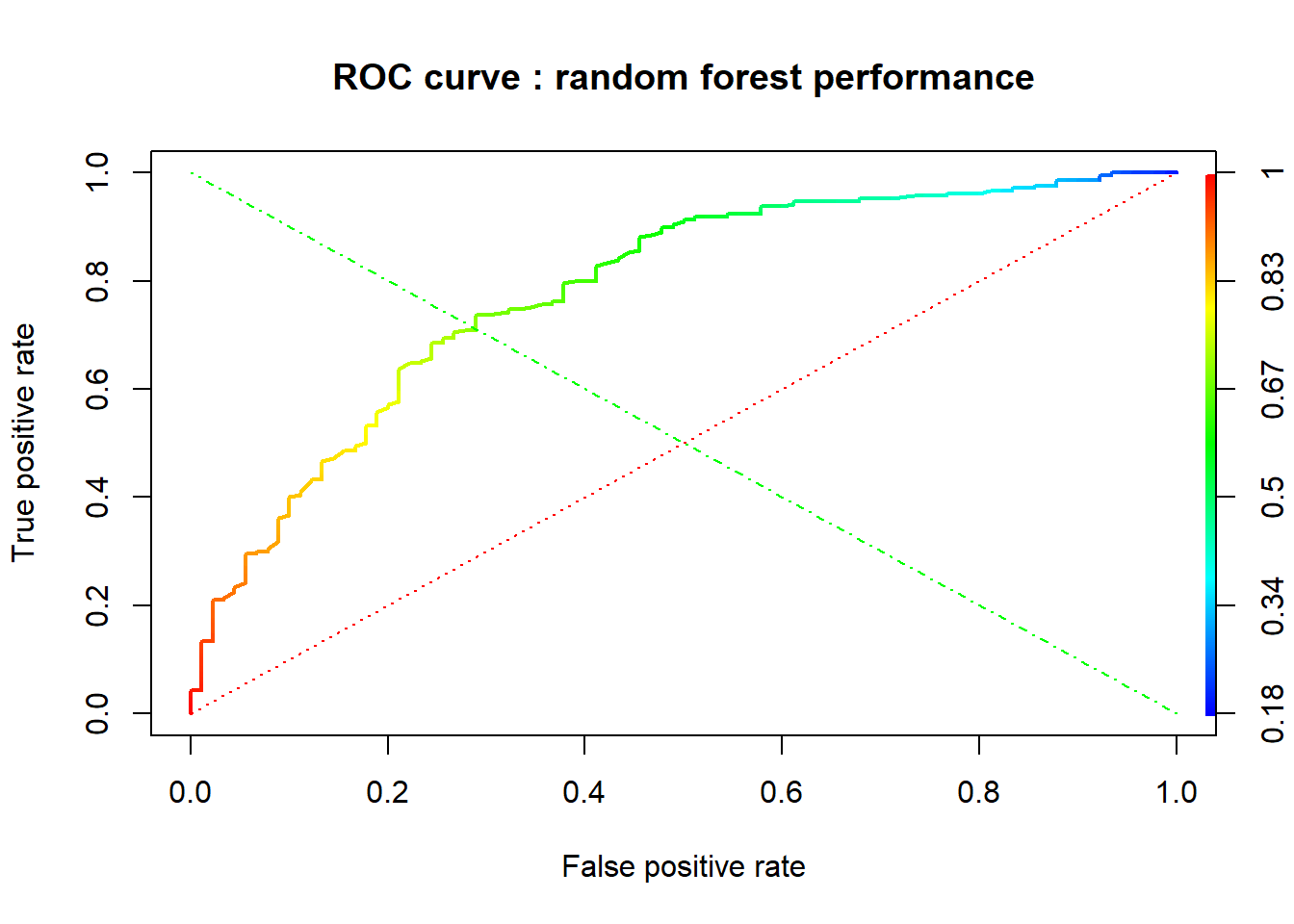
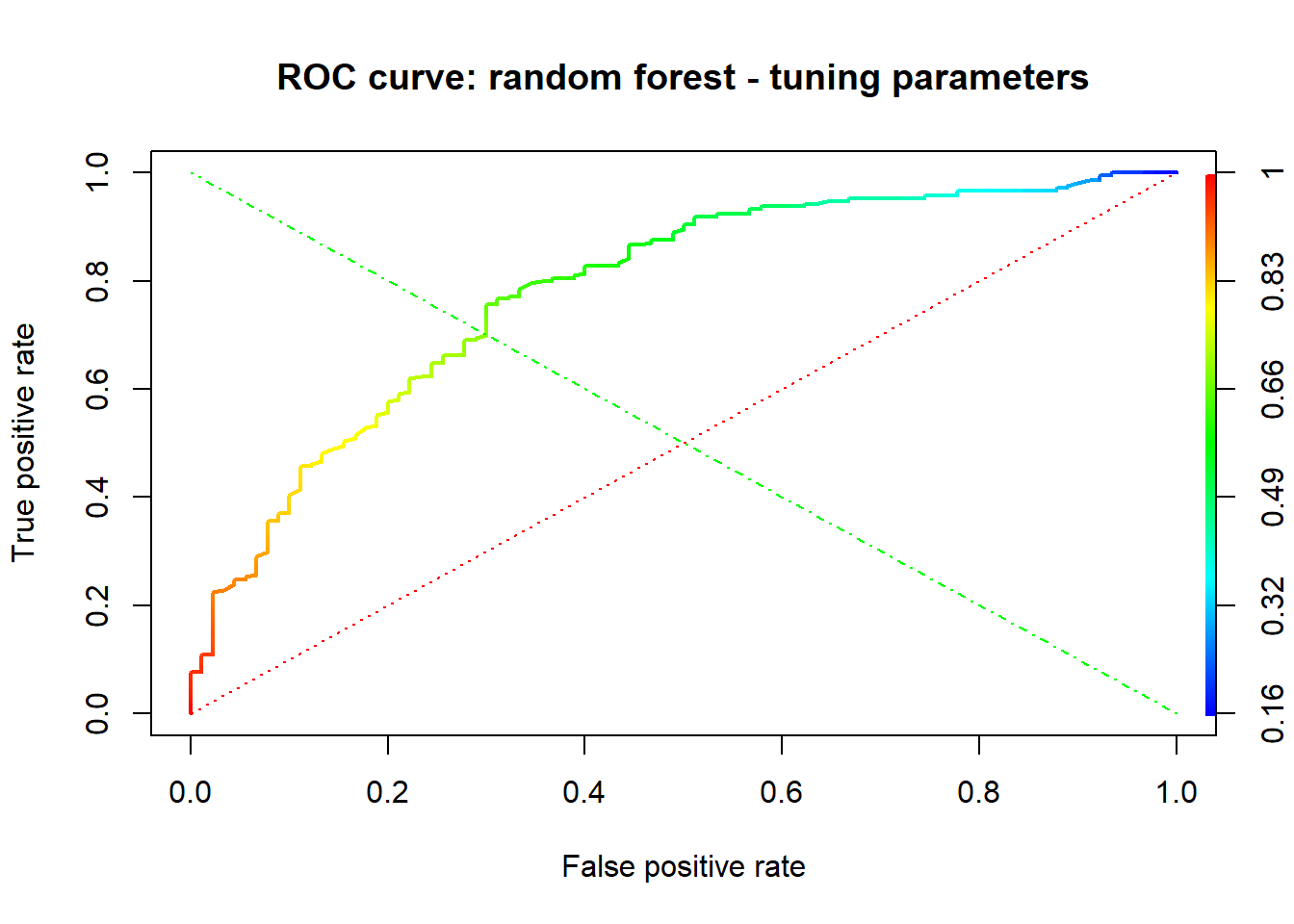
# Plot precision/recall curve
rf_perf_precision <- performance(rf_pred, measure = "prec", x.measure = "rec")
plot(rf_perf_precision , main="rf_model: Plot Precision/recall curve")
rf.best_perf_precision <- performance(model.best_pred, measure = "prec", x.measure = "rec")
plot(rf.best_perf_precision, main="rf_model.best: Plot Precision/recall curve")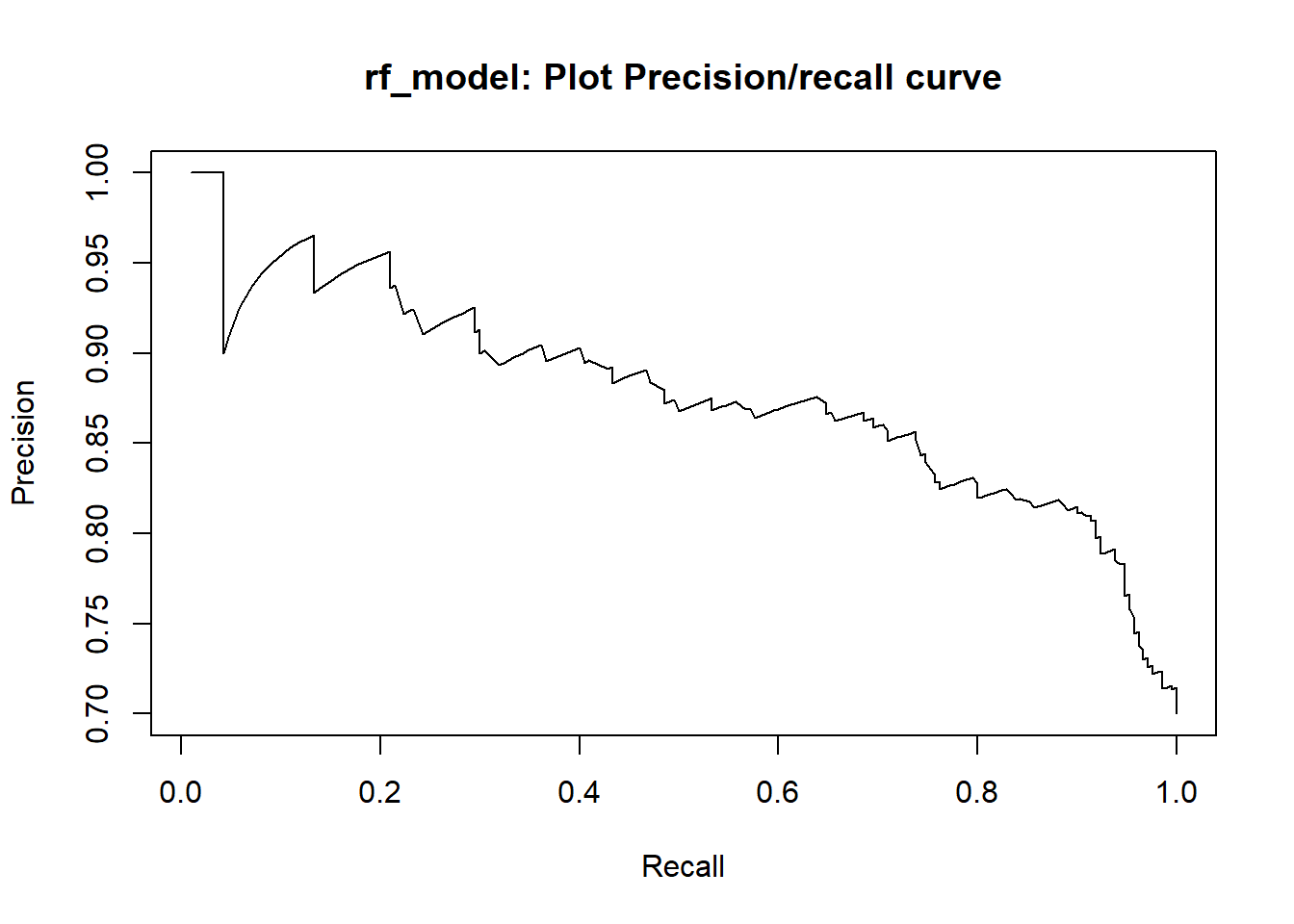
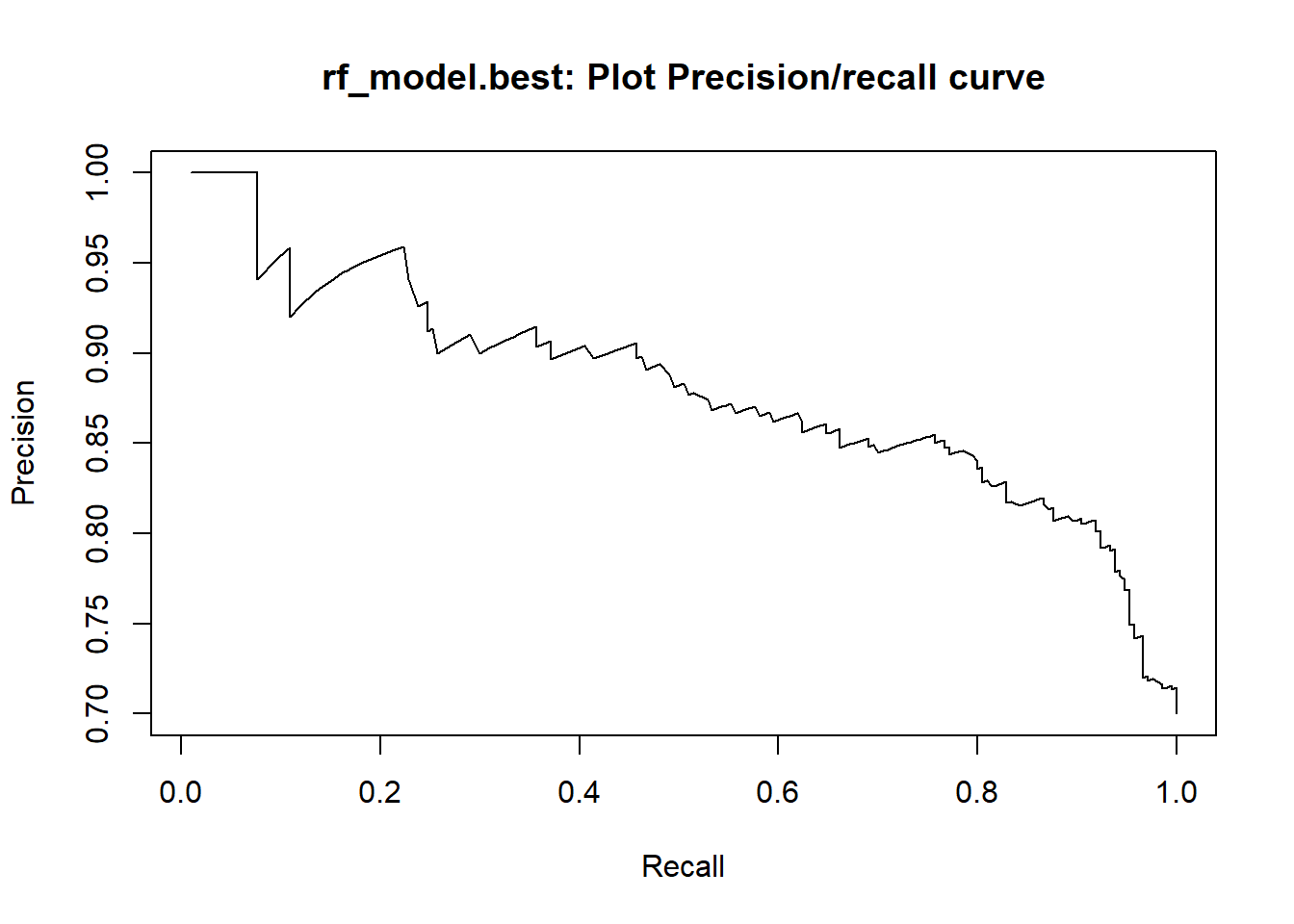
#AUC : random forests models
rf_model.AUROC <- round(performance(rf_pred, measure = "auc")@y.values[[1]], 4)
rf_model.AUROC 0.7805rf_newmodel.AUROC <- round(performance(model.new_pred, measure = "auc")@y.values[[1]], 4)
rf_newmodel.AUROC 0.749rf_bestmodel.AUROC <- round(performance(model.best_pred, measure = "auc")@y.values[[1]], 4)
rf_bestmodel.AUROC 0.7813The optimized random forest model which shows that best parameters are nodesize = 4 , mtry = 3 , ntree = 500 not only indicates a higher overall accuracy than other random forest models, but also a greater AUC value.
Decision tree is encountered with over-fitting problem and ignorance of a variable in case of small sample size and large p-value. Whereas, random forests are a type of recursive partitioning method particularly well-suited to small sample size and large p-value problems.Random forest comes at the expense of a some loss of interpretability, but generally greatly boosts the performance of the final model.
5.1.4.
Support Vector Machines
#we fit a SVM model with radial basis kernel and cost as 100
svm_model <- svm(Risk ~. , data = train, kernel = "radial", gamma = 1, cost = 100)
print(svm_model)
Call:
svm(formula = Risk ~ ., data = train, kernel = "radial", gamma = 1,
cost = 100)
Parameters:
SVM-Type: C-classification
SVM-Kernel: radial
cost: 100
gamma: 1
Number of Support Vectors: 699#prediction on test set
set.seed(1)
svm_predictions <- predict(svm_model, test[,-16], type="class")
cm_svm.m4 <- confusionMatrix(data=svm_predictions, reference=test[,16], positive="0")
cm_svm.m4Confusion Matrix and Statistics
Reference
Prediction 0 1
0 1 2
1 89 208
Accuracy : 0.6967
95% CI : (0.6412, 0.7482)
No Information Rate : 0.7
P-Value [Acc > NIR] : 0.5781
Kappa : 0.0022
Mcnemar's Test P-Value : <2e-16
Sensitivity : 0.011111
Specificity : 0.990476
Pos Pred Value : 0.333333
Neg Pred Value : 0.700337
Prevalence : 0.300000
Detection Rate : 0.003333
Detection Prevalence : 0.010000
Balanced Accuracy : 0.500794
'Positive' Class : 0
C controls the cost of misclassification on the training data. Small C makes the cost of misclassificaiton low (“soft margin”), thus allowing more of them for the sake of wider “cushion”. Large C makes the cost of misclassification high (’hard margin“), thus forcing the algorithm to explain the input data stricter and potentially overfit. Usually a very high number of support vectors like the one we obtained, 699, indicates you are overfitting. This presumably caused by the big value of C (C=100) we used.
We are going to improve our first svm model by finding the top 5 important variables and then adding effects of best tuning parameters of cost and gamma. Then , we are going to use the ksvm function of kernlab package to build a svm model based on vanilladot Linear kernel function.
#important features - selected by 10 fold cv , method = svmRadial
set.seed(1)
control <- trainControl(method="repeatedcv", number=10, repeats=2)
model_svm <- train(Risk ~ ., data=train, method="svmRadial",
trControl=control)
importance_svm <- varImp(model_svm,scale=FALSE)
plot(importance_svm,cex.lab=0.5)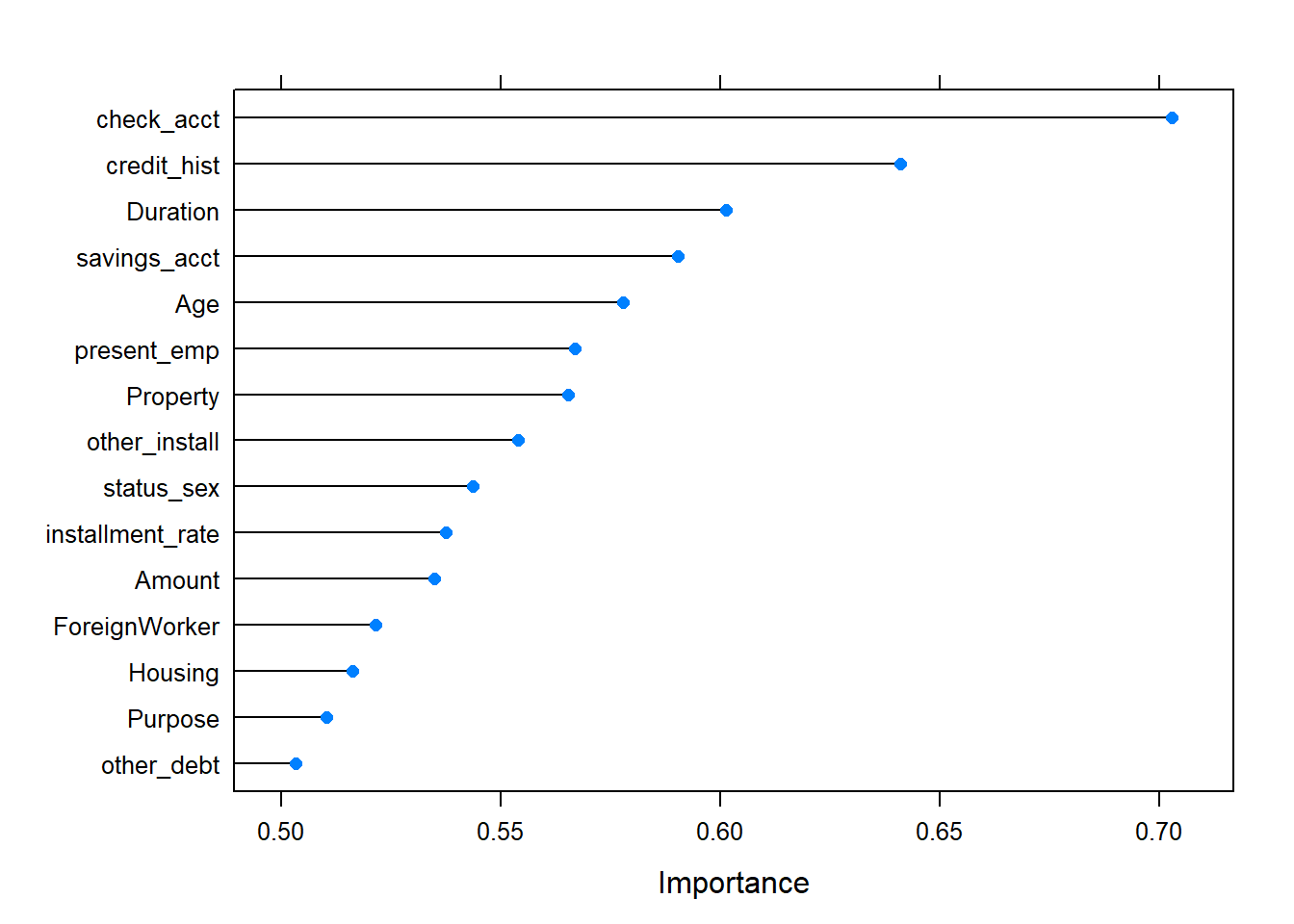
#tuning parameters svm model
set.seed(1)
cost.weights<- c(0.1,10,100)
gamma.weights <- c(0.01,0.25,0.5,1)
tuning.results <- tune(svm,Risk ~ check_acct + credit_hist + Duration + savings_acct + Age, data =train, kernel ="radial", ranges = list(cost=cost.weights, gamma = gamma.weights))
print(tuning.results)
Parameter tuning of 'svm':
- sampling method: 10-fold cross validation
- best parameters:
cost gamma
100 0.01
- best performance: 0.2685714 plot(tuning.results)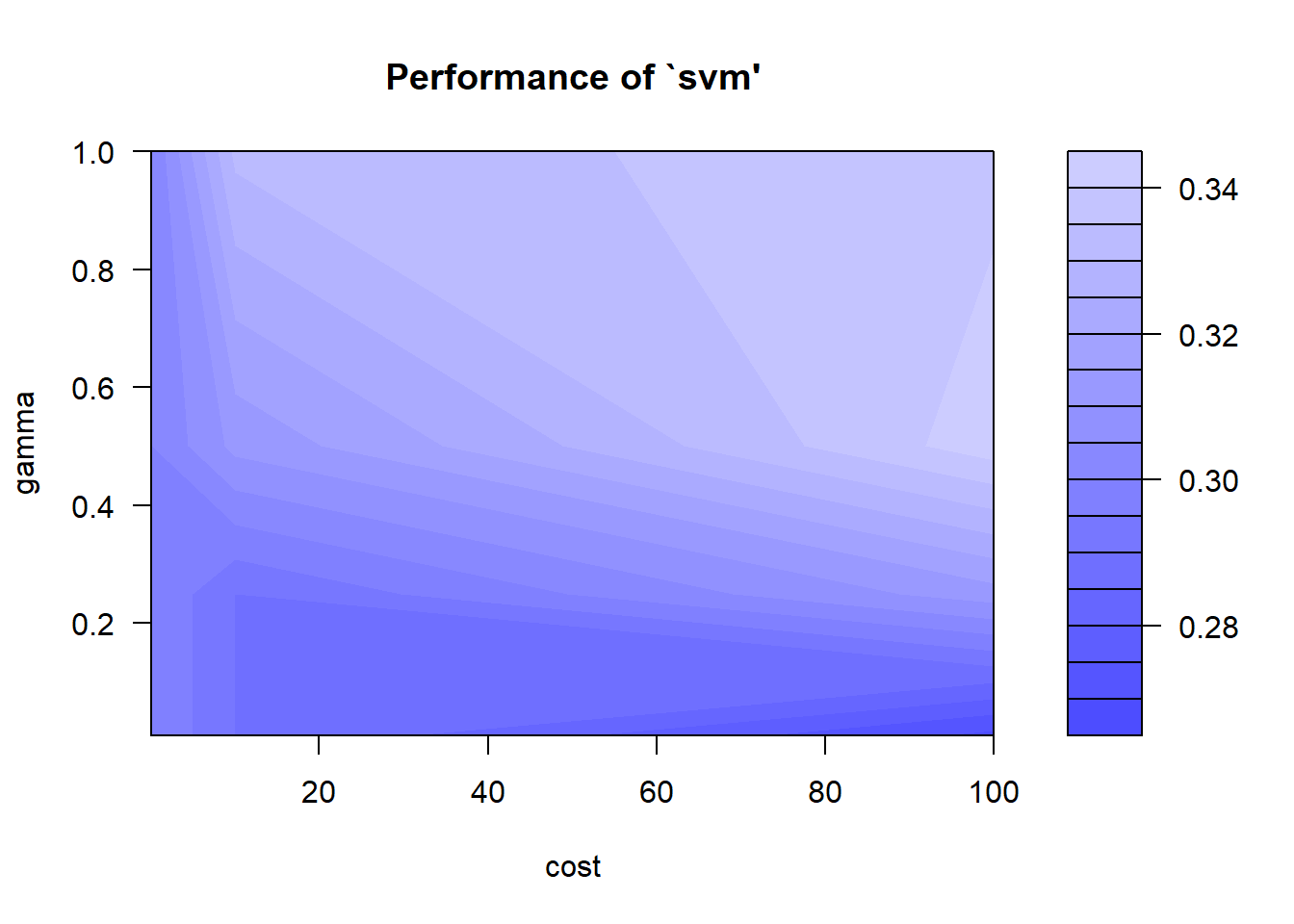
#prediction on unseen data , test set
svm_model.best <- tuning.results$best.model
svm_predictions.best <- predict(svm_model.best, test[,-16])
cm_svm.m4_1 <- confusionMatrix(data=svm_predictions.best, reference=test[,16], positive="0")
cm_svm.m4_1Confusion Matrix and Statistics
Reference
Prediction 0 1
0 26 12
1 64 198
Accuracy : 0.7467
95% CI : (0.6935, 0.7949)
No Information Rate : 0.7
P-Value [Acc > NIR] : 0.04285
Kappa : 0.2776
Mcnemar's Test P-Value : 4.913e-09
Sensitivity : 0.28889
Specificity : 0.94286
Pos Pred Value : 0.68421
Neg Pred Value : 0.75573
Prevalence : 0.30000
Detection Rate : 0.08667
Detection Prevalence : 0.12667
Balanced Accuracy : 0.61587
'Positive' Class : 0
“svm_model.best” shows a great improvement of overall accuracy value with respect to “svm_model”
#fitted svm model based on vanilladot Linear kernel function
set.seed(1)
svm_model.vanilla <- ksvm(Risk ~., data = train, kernel = "vanilladot") Setting default kernel parameters print(svm_model.vanilla)Support Vector Machine object of class "ksvm"
SV type: C-svc (classification)
parameter : cost C = 1
Linear (vanilla) kernel function.
Number of Support Vectors : 374
Objective Function Value : -346.6312
Training error : 0.208571 #prediction on test set
svm_predictions.vanilla <- predict(svm_model.vanilla, test[,-16])
cm_svm.m4_2 <- confusionMatrix(data=svm_predictions.vanilla, reference=test[,16], positive="0")
cm_svm.m4_2Confusion Matrix and Statistics
Reference
Prediction 0 1
0 46 29
1 44 181
Accuracy : 0.7567
95% CI : (0.704, 0.8041)
No Information Rate : 0.7
P-Value [Acc > NIR] : 0.01741
Kappa : 0.3917
Mcnemar's Test P-Value : 0.10130
Sensitivity : 0.5111
Specificity : 0.8619
Pos Pred Value : 0.6133
Neg Pred Value : 0.8044
Prevalence : 0.3000
Detection Rate : 0.1533
Detection Prevalence : 0.2500
Balanced Accuracy : 0.6865
'Positive' Class : 0
#Model performance plot
#define performance
# score test data/model scoring for ROc curve - svm_model
svm_predictions.values <- predict(svm_model,test,type="decision", decision.values =TRUE)
svm_pred <- prediction(attributes(svm_predictions.values)$decision.values,test$Risk)
svm_perf <- performance(svm_pred,"tpr","fpr")
# score test data/model scoring for ROc curve - svm_model.best
svm.best_predictions.values <- predict(svm_model.best,test,type="decision", decision.values =TRUE)
svm.best_pred <- prediction(attributes(svm.best_predictions.values)$decision.values,test$Risk)
svm.best_perf <- performance(svm.best_pred,"tpr","fpr")
# score test data/model scoring for ROc curve - svm_model.vanilla
svm.van_predictions.values <- predict(svm_model.vanilla,test,type="decision")
svm.van_pred <- prediction(svm.van_predictions.values,test$Risk)
svm.van_perf <- performance(svm.van_pred,"tpr","fpr")Based on their overall accuracy values, we plot the ROC curves of potential best two models. (svm.best_model & svm_model.vanilla) .
#plot roc curves
#svm_model.best
plot(svm.best_perf, lwd=2, colorize=TRUE, main="SVM: ROC curve - radial basis,important features")
lines(x=c(0, 1), y=c(0, 1), col="red", lwd=1, lty=3);
lines(x=c(1, 0), y=c(0, 1), col="green", lwd=1, lty=4)
#svm_model.vanilla
plot(svm.van_perf , lwd=2, colorize=TRUE, main="SVM: ROC curve - vanilladot")
lines(x=c(0, 1), y=c(0, 1), col="red", lwd=1, lty=3);
lines(x=c(1, 0), y=c(0, 1), col="green", lwd=1, lty=4) 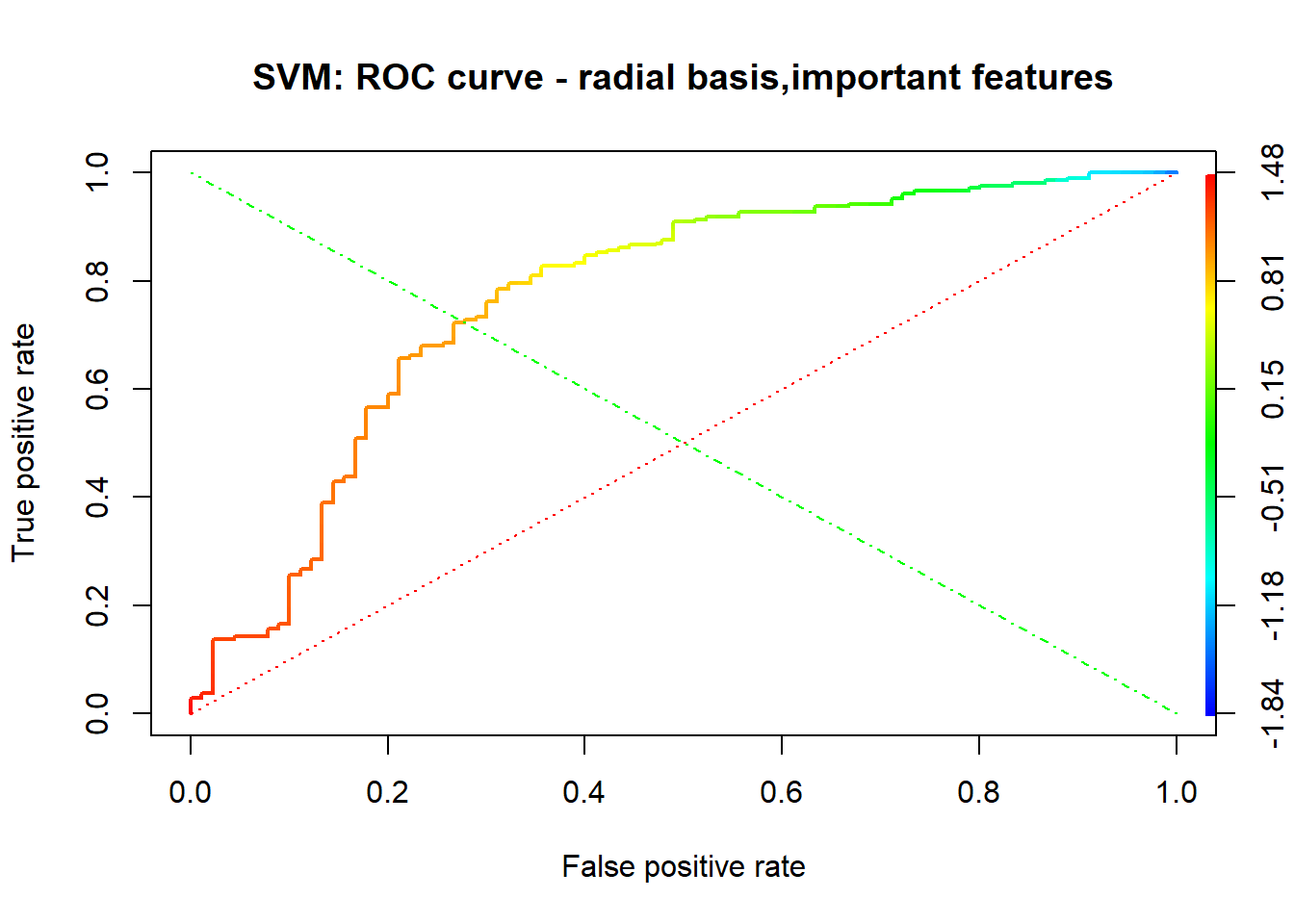
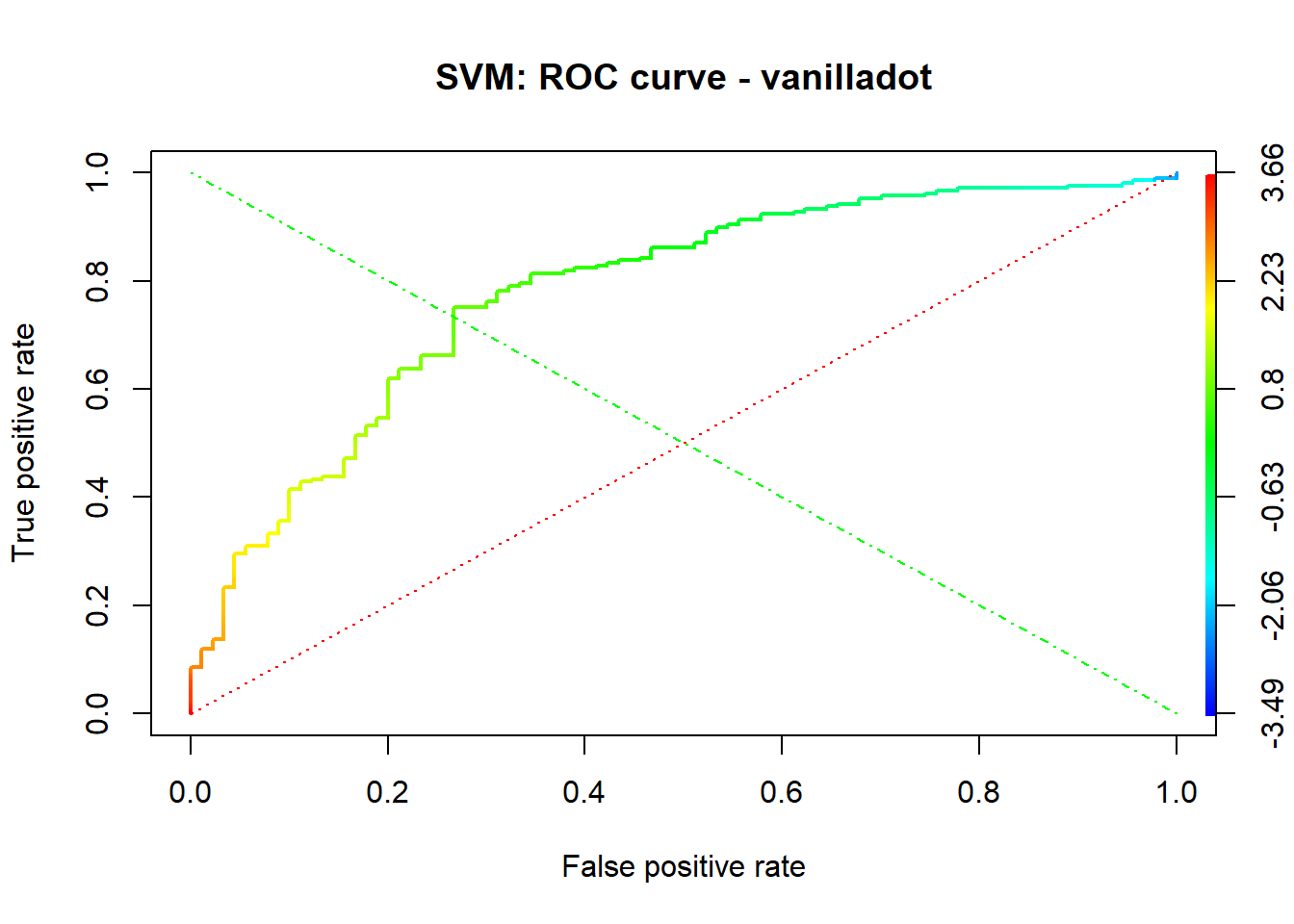
# Plot precision/recall curve
svm.best_perf_precision <- performance(svm.best_pred, measure = "prec", x.measure = "rec")
plot(svm.best_perf_precision, main="svm_model.best: Plot Precision/recall curve")
svm.van_perf_precision <- performance(svm.van_pred, measure = "prec", x.measure = "rec")
plot(svm.van_perf_precision, main="svm_model.van: Plot Precision/recall curve")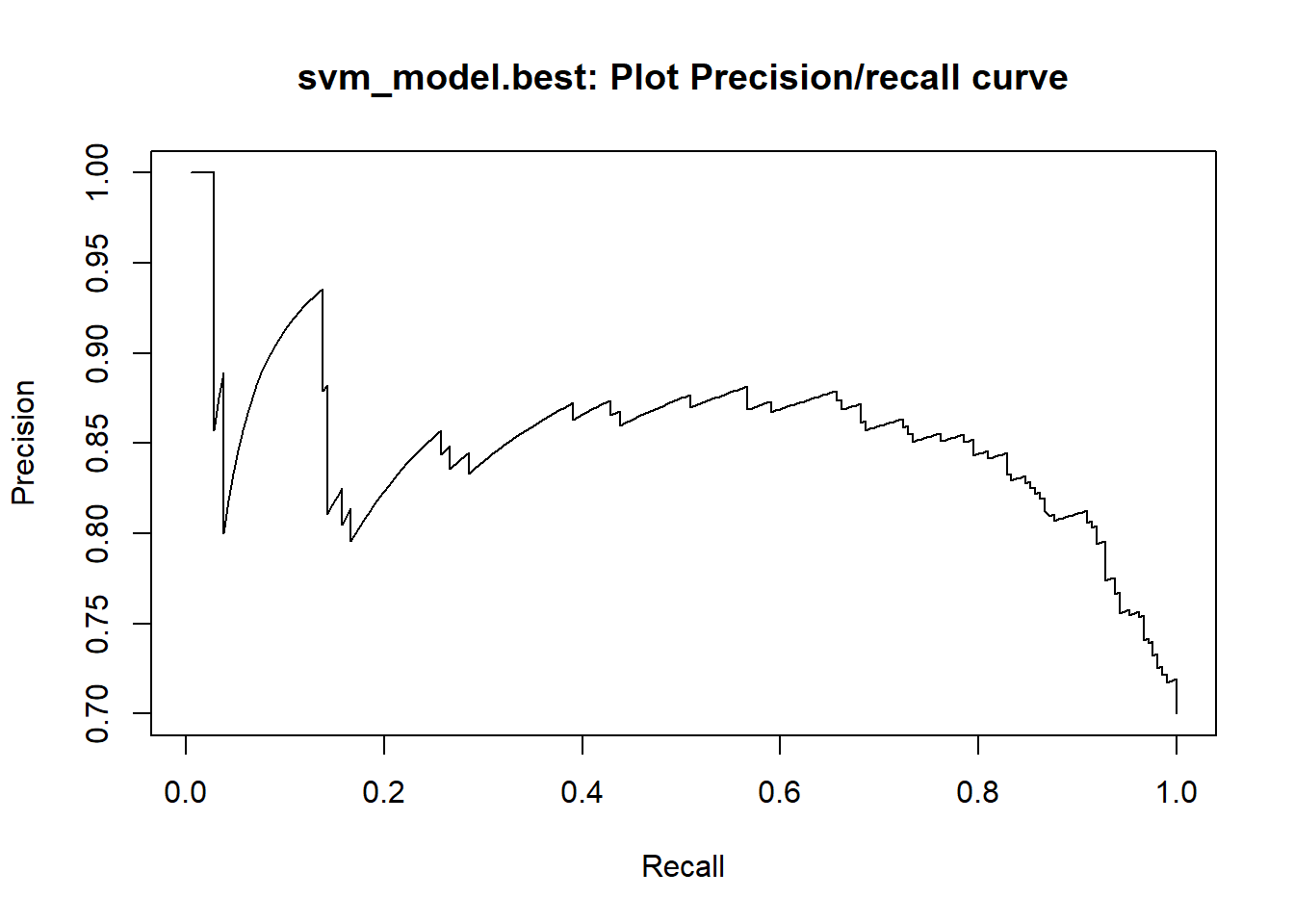
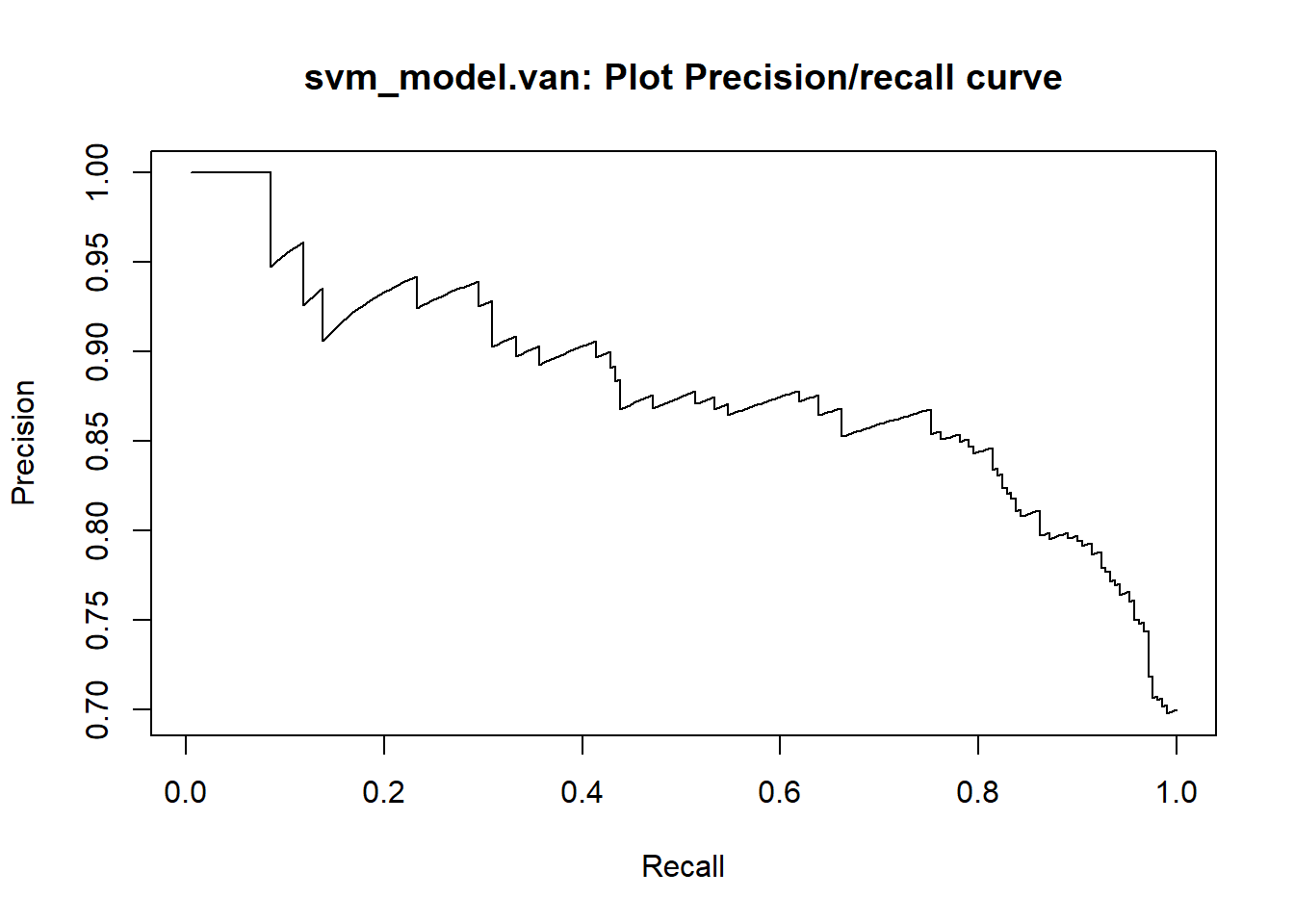
#AUC : svm models
svm_model.AUROC <- round(performance(svm_pred, measure = "auc")@y.values[[1]], 4)
svm_model.AUROC 0.7313svm.best_model.AUROC <- round(performance(svm.best_pred, measure = "auc")@y.values[[1]], 4)
svm.best_model.AUROC 0.7692svm.van_model.AUROC <- round(performance(svm.van_pred, measure = "auc")@y.values[[1]], 4)
svm.van_model.AUROC 0.7794SVMs are great classifiers for specific situations when the groups are clearly separated. They also do a great job when your data is non-linearly separated. You could transform data to linearly separate it, or you can have SVMs convert the data and linearly separate the two classes right out of the box. This is one of the main reasons to use SVMs. You don’t have to transform non-linear data yourself. One downside to SVMs is the black box nature of these functions. The use of kernels to separate non-linear data makes them difficult (if not impossible) to interpret. Understanding them will give you an alternative to GLMs and decision trees for classification.
5.1.5.
Neural Networks
To perform neural network models we need numeric data .Normally, a neural network doesn’t fit well with low number of observations. First avoid, we are going to perform a specific Data pre-processing using the original data copy “german.copy” instead of “german.copy2” . Then, we’ll fit the neural network model with the nnet function.
Why neural network needs normalization/standardization ? : If the input variables are combined linearly, as in an MLP, then it is rarely strictly necessary to standardize the inputs, at least in theory. The reason is that any rescaling of an input vector can be effectively undone by changing the corresponding weights and biases, leaving you with the exact same outputs as you had before. However, there are a variety of practical reasons why standardizing the inputs can make training faster and reduce the chances of getting stuck in local optima. Also, weight decay and Bayesian estimation can be done more conveniently with standardized inputs. Standardizing inputs variables tends to make the training process better behaved by improving the numerical condition (see ftp://ftp.sas.com/pub/neural/illcond/illcond.html) of the optimization problem and ensuring that various default values involved in initialization and termination are appropriate.
read more here or at this link
# Data pre-processing for Neural network models
#retain from the german.copy data only the numerical target "risk_bin" and "keep$Variables" from the IV statistic.
# german.copy3 <- german.copy %>%
# select(-c(Risk))
german.copy3 <- german.copy[,c(keep$Variable,"risk_bin")]
# Read a numeric copy: Numeric data for Neural network
german.copy3 <- as.data.frame(sapply(german.copy3, as.numeric ))
# For neural network we would need continuous data
# Sampling for Neural Network - It can be used for Lasso regression too
set.seed(1)
idx <- createDataPartition(y = german.copy3[,16], p = 0.7, list = F)
# Training Sample for Neural Network
train_num <- german.copy3[idx,] # 70% here
# Test Sample for Neural Network
test_num <- german.copy3[-idx,] # rest of the 30% data goes here
#structures of new train/test sets
str(train_num)'data.frame': 700 obs. of 16 variables:
$ check_acct : num 1 2 1 1 4 2 1 1 1 4 ...
$ credit_hist : num 5 3 3 4 3 3 3 5 3 3 ...
$ Duration : num 6 48 42 24 24 12 48 24 15 24 ...
$ savings_acct : num 5 1 1 1 3 1 1 1 1 3 ...
$ Purpose : num 4 4 3 1 3 1 10 1 1 4 ...
$ Age : num 67 22 45 53 53 25 24 60 28 31 ...
$ Property : num 1 1 2 4 2 3 2 3 3 3 ...
$ Amount : num 1169 5951 7882 4870 2835 ...
$ present_emp : num 4 2 3 2 4 1 1 4 2 4 ...
$ Housing : num 2 2 3 3 2 1 1 2 1 2 ...
$ other_install : num 3 3 3 3 3 3 3 3 3 3 ...
$ status_sex : num 3 2 3 3 3 2 2 3 2 3 ...
$ ForeignWorker : num 2 2 2 2 2 2 2 2 2 2 ...
$ other_debt : num 1 1 3 1 1 1 1 1 1 1 ...
$ installment_rate: num 4 2 2 3 3 3 3 4 2 3 ...
$ risk_bin : num 1 0 1 0 1 0 0 0 1 1 ...str(test_num)'data.frame': 300 obs. of 16 variables:
$ check_acct : num 4 4 2 4 2 2 1 4 1 2 ...
$ credit_hist : num 5 3 3 3 5 3 3 5 1 3 ...
$ Duration : num 12 36 36 12 30 12 24 24 30 24 ...
$ savings_acct : num 1 5 1 4 1 1 2 5 5 1 ...
$ Purpose : num 7 7 2 4 1 4 4 4 10 2 ...
$ Age : num 49 35 35 61 28 22 32 53 25 44 ...
$ Property : num 1 4 3 1 3 3 3 2 3 4 ...
$ Amount : num 2096 9055 6948 3059 5234 ...
$ present_emp : num 3 2 2 3 5 2 2 4 1 4 ...
$ Housing : num 2 3 1 2 2 2 2 2 2 3 ...
$ other_install : num 3 3 3 3 3 3 3 3 1 3 ...
$ status_sex : num 3 3 3 1 4 2 2 3 3 2 ...
$ ForeignWorker : num 2 2 2 2 2 2 2 2 2 2 ...
$ other_debt : num 1 1 1 1 1 1 1 1 1 1 ...
$ installment_rate: num 2 2 2 2 4 1 4 4 2 4 ...
$ risk_bin : num 1 1 1 1 0 1 0 1 1 0 ...# Normalization / scaling
train_num$risk_bin <- as.factor(train_num$risk_bin)
test_num$risk_bin <- as.factor(test_num$risk_bin)
# Function: Normalize using Range
normalize <- function(x) {
return((x - min(x)) / (max(x) - min(x)))
}
train_num_norm <- as.data.frame(lapply(train_num[,1:15], normalize ))
test_num_norm <- as.data.frame(lapply(test_num[,1:15], normalize ))
train_num_norm$risk_bin <- as.factor(ifelse(train_num$risk_bin == 1, 1, 0))
test_num_norm$risk_bin <- as.factor(ifelse(test_num$risk_bin == 1, 1, 0))
# train_num_norm <- as.data.frame(lapply(train_num[,1:24], scale )) # use scale if normal
# test_num_norm <- as.data.frame(lapply(test_num[,1:24], scale )) # use scale if normal
# build the neural network (NN) formula
a <- colnames(train_num[,1:15])
mformula <- as.formula(paste('risk_bin ~ ' , paste(a,collapse='+')))
set.seed(1234567890)
train_nn <- train_num_norm
test_nn <- test_num_norm# Neural network modelling
set.seed(1)
neur.net <- nnet(risk_bin~., data=train_nn,size=20,maxit=10000,decay=.001, linout=F, trace = F)
print(neur.net)a 15-20-1 network with 341 weights
inputs: check_acct credit_hist Duration savings_acct Purpose Age Property Amount present_emp Housing other_install status_sex ForeignWorker other_debt installment_rate
output(s): risk_bin
options were - entropy fitting decay=0.001#prediction of neur.net on test set
neur.net_predictions <- predict(neur.net,newdata=test_nn, type="class") %>% factor()
cm_neuralnet.m5 <- confusionMatrix(data=neur.net_predictions, reference=test_nn[,16], positive="0")
cm_neuralnet.m5Confusion Matrix and Statistics
Reference
Prediction 0 1
0 41 57
1 54 148
Accuracy : 0.63
95% CI : (0.5726, 0.6848)
No Information Rate : 0.6833
P-Value [Acc > NIR] : 0.9786
Kappa : 0.1522
Mcnemar's Test P-Value : 0.8494
Sensitivity : 0.4316
Specificity : 0.7220
Pos Pred Value : 0.4184
Neg Pred Value : 0.7327
Prevalence : 0.3167
Detection Rate : 0.1367
Detection Prevalence : 0.3267
Balanced Accuracy : 0.5768
'Positive' Class : 0
# get the weights and structure in the right format
wts <- neuralweights(neur.net)
struct <- wts$struct
wts <- unlist(wts$wts)
plotnet(wts, struct=struct)
#Model performance plot
#define performance
# score test data/model scoring for ROc curve - neural network model
neur.net_pred <- prediction(predict(neur.net, newdata=test_nn, type="raw"),test_nn$risk_bin)
neur.net_perf <- performance(neur.net_pred,"tpr","fpr")#plot roc curves
plot(neur.net_perf ,lwd=2, colorize=TRUE, main="ROC curve: Neural Network performance")
lines(x=c(0, 1), y=c(0, 1), col="red", lwd=1, lty=3);
lines(x=c(1, 0), y=c(0, 1), col="green", lwd=1, lty=4) 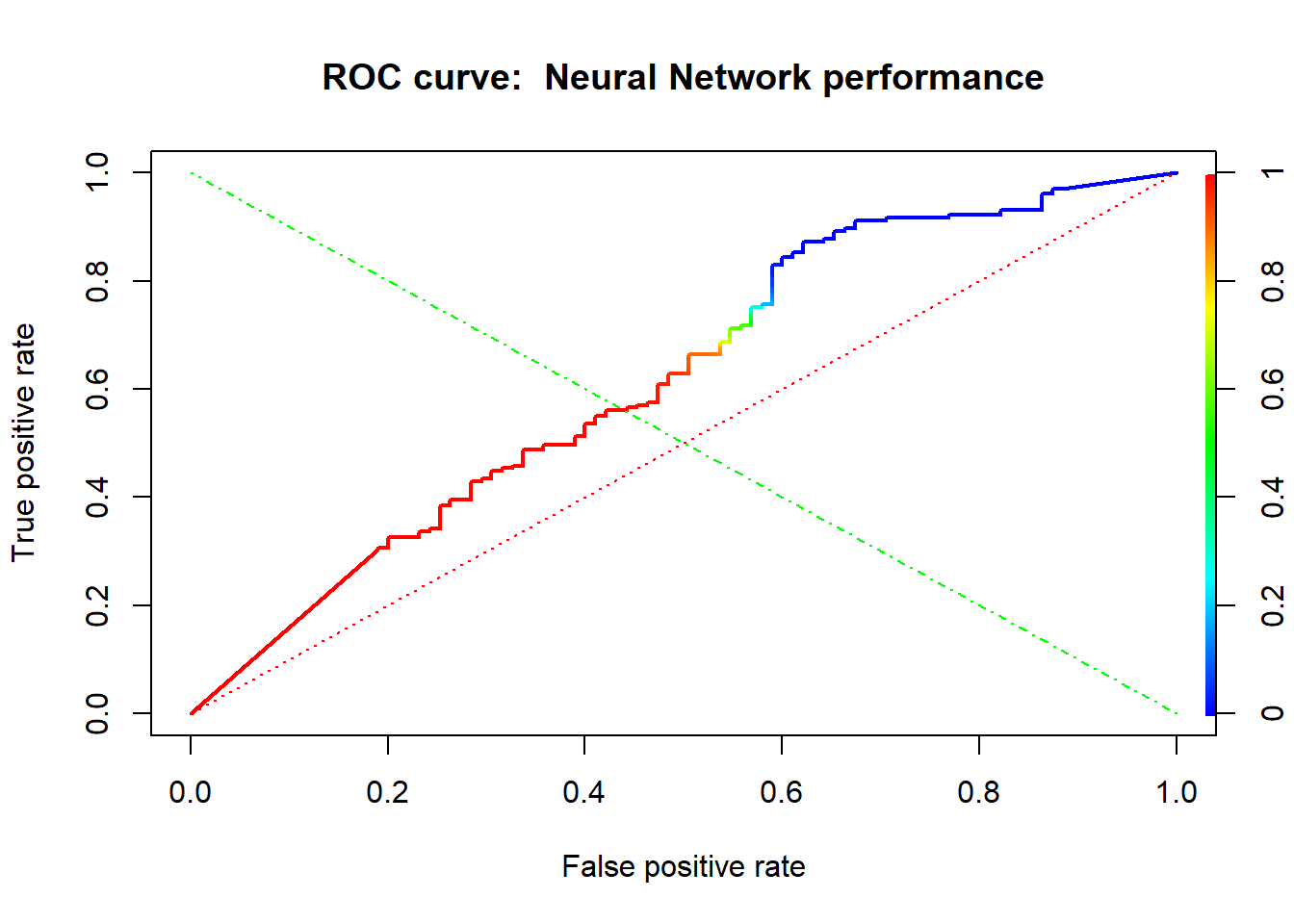
# Plot precision/recall curve
neur.net_perf_precision <- performance(neur.net_pred, measure = "prec", x.measure = "rec")
plot(neur.net_perf_precision, main="neural network: Plot Precision/recall curve")
#AUC : neural network model
neur_model.AUROC <- round(performance(neur.net_pred, measure = "auc")@y.values[[1]], 4)
neur_model.AUROC 0.6185Compared to the previous models, “neur.net” seems to be the less accurate model. It shows an overall accuracy of 0.63.
5.1.6.
Lasso regression
For the lasso regression model, we will use the same train_num and test_num we defined first for the neural network model. However, because the glmnet functions don’t need a regression formula , but input matrices of predictors, we will first construct mat_train and mat_test with the model.matrix function as follow.
mat_train <- model.matrix(risk_bin ~ . , data = train_num ) # convert to numeric matrix
mat_test <- model.matrix(risk_bin ~ . , data = test_num ) # convert to numeric matrixWe fitted a GLM with lasso regularization, performing cross validation to find the optimal lambda. alpha = 1 indicates that is LASSO and not elasticnet regression. We choose as loss measure to use for cross-validation “auc” , that is for two-class logistic regression only, and gives area under the ROC curve.
#fit LASSO model
set.seed(1)
lasso_model <- cv.glmnet(mat_train,as.numeric(train_num$risk_bin), alpha=1, nfolds=10, family="binomial", type.measure = 'auc')
print(lasso_model) 0.1565350927 0.1426289465 0.1299581840 0.1184130571 0.1078935675
[6] 0.0983086003 0.0895751352 0.0816175271 0.0743668509 0.0677603049
[11] 0.0617406662 0.0562557955 0.0512581857 0.0467045498 0.0425554463
[16] 0.0387749377 0.0353302791 0.0321916345 0.0293318184 0.0267260605
[21] 0.0243517910 0.0221884450 0.0202172847 0.0184212368 0.0167847449
[26] 0.0152936345 0.0139349901 0.0126970440 0.0115690736 0.0105413090
[31] 0.0096048482 0.0087515799 0.0079741137 0.0072657154 0.0066202493
[36] 0.0060321246 0.0054962473 0.0050079758 0.0045630810 0.0041577095
[41] 0.0037883500 0.0034518035 0.0031451548 0.0028657479 0.0026111627
[46] 0.0023791942 0.0021678332 0.0019752488 0.0017997732 0.0016398863
[51] 0.0014942033 0.0013614624 0.0012405138 0.0011303100 0.0010298964
[56] 0.0009384032 0.0008550381 0.0007790788 0.0007098676 0.0006468049
[61] 0.0005893446
$cvm
[1] 0.5710319 0.6977412 0.7160305 0.7152162 0.7197872 0.7299857 0.7447013
[8] 0.7495949 0.7557273 0.7600720 0.7626805 0.7652861 0.7677099 0.7699548
[15] 0.7700668 0.7709220 0.7732505 0.7759888 0.7791641 0.7817496 0.7840544
[22] 0.7874060 0.7895120 0.7906726 0.7917014 0.7922798 0.7936065 0.7952416
[29] 0.7952178 0.7944505 0.7936879 0.7932648 0.7932085 0.7935062 0.7941476
[36] 0.7948539 0.7947934 0.7948773 0.7947804 0.7950497 0.7948166 0.7948000
[43] 0.7943998 0.7944270 0.7943607 0.7945550 0.7946475 0.7947427 0.7944365
[50] 0.7947209 0.7948482 0.7946472 0.7946472 0.7944610 0.7942653 0.7942612
[57] 0.7939686 0.7936782 0.7932583 0.7934615 0.7935435
$cvsd
[1] 0.04300289 0.01734456 0.01671123 0.01759359 0.02140464 0.01471195
[7] 0.01614760 0.01703056 0.01809857 0.01837942 0.01912454 0.01964134
[13] 0.01981164 0.02102170 0.02187689 0.02203593 0.02176342 0.02166480
[19] 0.02176843 0.02133350 0.02214582 0.02183725 0.02218276 0.02221030
[25] 0.02216032 0.02253537 0.02294118 0.02286370 0.02300748 0.02333197
[31] 0.02346921 0.02321008 0.02335437 0.02349827 0.02331831 0.02338554
[37] 0.02339704 0.02320197 0.02338284 0.02309179 0.02329735 0.02320673
[43] 0.02320474 0.02322951 0.02335467 0.02334088 0.02328073 0.02320944
[49] 0.02324838 0.02325124 0.02317997 0.02318925 0.02318925 0.02311963
[55] 0.02318522 0.02316493 0.02309257 0.02313453 0.02311762 0.02308301
[61] 0.02311939
$cvup
[1] 0.6140348 0.7150857 0.7327417 0.7328098 0.7411919 0.7446977 0.7608489
[8] 0.7666255 0.7738259 0.7784514 0.7818050 0.7849274 0.7875215 0.7909765
[15] 0.7919437 0.7929579 0.7950139 0.7976536 0.8009325 0.8030831 0.8062002
[22] 0.8092432 0.8116947 0.8128829 0.8138618 0.8148152 0.8165477 0.8181053
[29] 0.8182252 0.8177825 0.8171571 0.8164749 0.8165629 0.8170044 0.8174659
[36] 0.8182395 0.8181905 0.8180793 0.8181632 0.8181415 0.8181139 0.8180068
[43] 0.8176046 0.8176565 0.8177154 0.8178959 0.8179282 0.8179521 0.8176849
[50] 0.8179721 0.8180281 0.8178365 0.8178365 0.8175806 0.8174505 0.8174261
[57] 0.8170612 0.8168127 0.8163759 0.8165445 0.8166629
$cvlo
[1] 0.5280290 0.6803966 0.6993193 0.6976226 0.6983826 0.7152738 0.7285537
[8] 0.7325643 0.7376287 0.7416925 0.7435559 0.7456447 0.7478983 0.7489331
[15] 0.7481899 0.7488860 0.7514871 0.7543239 0.7573956 0.7604161 0.7619085
[22] 0.7655687 0.7673292 0.7684623 0.7695411 0.7697445 0.7706653 0.7723779
[29] 0.7722103 0.7711185 0.7702187 0.7700548 0.7698541 0.7700079 0.7708293
[36] 0.7714684 0.7713964 0.7716754 0.7713975 0.7719579 0.7715192 0.7715933
[43] 0.7711951 0.7711975 0.7710060 0.7712141 0.7713668 0.7715333 0.7711881
[50] 0.7714696 0.7716682 0.7714580 0.7714580 0.7713414 0.7710801 0.7710962
[57] 0.7708760 0.7705436 0.7701407 0.7703785 0.7704241
$nzero
s0 s1 s2 s3 s4 s5 s6 s7 s8 s9 s10 s11 s12 s13 s14 s15 s16 s17
0 1 1 1 1 2 3 3 3 3 4 4 5 6 6 7 9 10
s18 s19 s20 s21 s22 s23 s24 s25 s26 s27 s28 s29 s30 s31 s32 s33 s34 s35
11 11 12 12 12 13 14 14 14 14 15 15 15 15 15 15 15 15
s36 s37 s38 s39 s40 s41 s42 s43 s44 s45 s46 s47 s48 s49 s50 s51 s52 s53
15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15
s54 s55 s56 s57 s58 s59 s60
15 15 15 15 15 15 15
$name
auc
"AUC"
$glmnet.fit
Call: glmnet(x = mat_train, y = as.numeric(train_num$risk_bin), alpha = 1, family = "binomial")
Df %Dev Lambda
[1,] 0 -1.616e-14 0.1565000
[2,] 1 1.663e-02 0.1426000
[3,] 1 3.048e-02 0.1300000
[4,] 1 4.207e-02 0.1184000
[5,] 1 5.177e-02 0.1079000
[6,] 2 6.141e-02 0.0983100
[7,] 3 7.580e-02 0.0895800
[8,] 3 8.964e-02 0.0816200
[9,] 3 1.013e-01 0.0743700
[10,] 3 1.111e-01 0.0677600
[11,] 4 1.200e-01 0.0617400
[12,] 4 1.290e-01 0.0562600
[13,] 5 1.379e-01 0.0512600
[14,] 6 1.459e-01 0.0467000
[15,] 6 1.533e-01 0.0425600
[16,] 7 1.598e-01 0.0387700
[17,] 9 1.677e-01 0.0353300
[18,] 10 1.753e-01 0.0321900
[19,] 11 1.831e-01 0.0293300
[20,] 11 1.898e-01 0.0267300
[21,] 12 1.962e-01 0.0243500
[22,] 12 2.018e-01 0.0221900
[23,] 12 2.065e-01 0.0202200
[24,] 13 2.106e-01 0.0184200
[25,] 14 2.144e-01 0.0167800
[26,] 14 2.178e-01 0.0152900
[27,] 14 2.206e-01 0.0139300
[28,] 14 2.230e-01 0.0127000
[29,] 15 2.252e-01 0.0115700
[30,] 15 2.272e-01 0.0105400
[31,] 15 2.289e-01 0.0096050
[32,] 15 2.303e-01 0.0087520
[33,] 15 2.315e-01 0.0079740
[34,] 15 2.326e-01 0.0072660
[35,] 15 2.334e-01 0.0066200
[36,] 15 2.342e-01 0.0060320
[37,] 15 2.348e-01 0.0054960
[38,] 15 2.353e-01 0.0050080
[39,] 15 2.358e-01 0.0045630
[40,] 15 2.362e-01 0.0041580
[41,] 15 2.365e-01 0.0037880
[42,] 15 2.367e-01 0.0034520
[43,] 15 2.370e-01 0.0031450
[44,] 15 2.371e-01 0.0028660
[45,] 15 2.373e-01 0.0026110
[46,] 15 2.374e-01 0.0023790
[47,] 15 2.375e-01 0.0021680
[48,] 15 2.376e-01 0.0019750
[49,] 15 2.377e-01 0.0018000
[50,] 15 2.378e-01 0.0016400
[51,] 15 2.378e-01 0.0014940
[52,] 15 2.379e-01 0.0013610
[53,] 15 2.379e-01 0.0012410
[54,] 15 2.379e-01 0.0011300
[55,] 15 2.380e-01 0.0010300
[56,] 15 2.380e-01 0.0009384
[57,] 15 2.380e-01 0.0008550
[58,] 15 2.380e-01 0.0007791
[59,] 15 2.380e-01 0.0007099
[60,] 15 2.380e-01 0.0006468
[61,] 15 2.380e-01 0.0005893
$lambda.min
[1] 0.01269704
$lambda.1se
[1] 0.03533028
attr(,"class")
[1] "cv.glmnet"The following plot shows the models (with different lambda values) that glmnet fitted, along with the auc values for each of the models.
plot(lasso_model)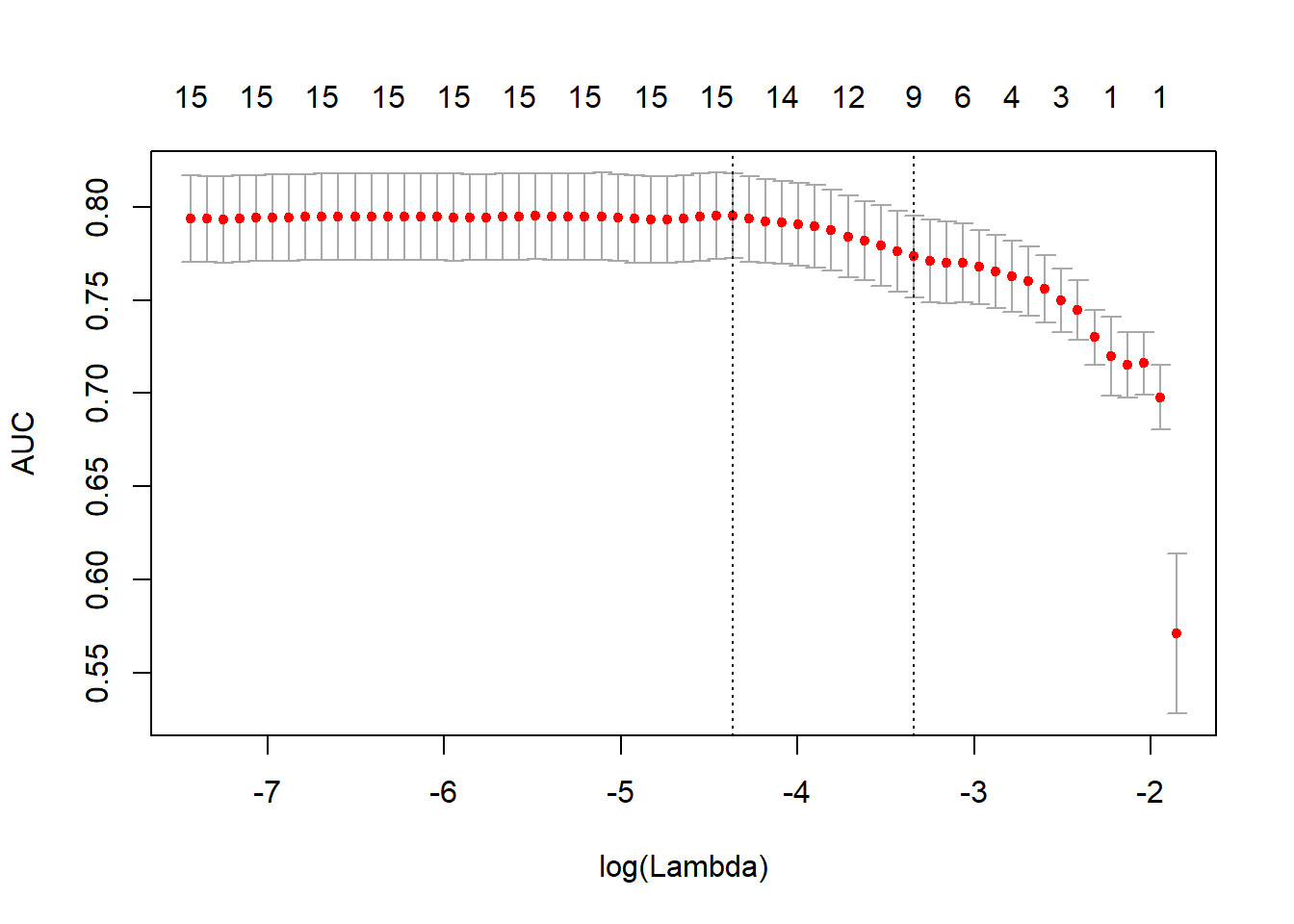
It includes the cross-validation curve (red dotted line), and upper and lower standard deviation curves along the \(λ\) sequence (error bars). Two selected \(λ’s\) are indicated by the vertical dotted lines (see below). We can view the selected \(λ’s\) and the corresponding coefficients. For example, the minimum value of lambda , i.e the one that minimises the auc value corresponds to lasso_model$lambda.min . lambda.min or lambda.1se ? : The lambda.min option refers to value of \(λ\) at the lowest CV error. The error at this value of \(λ\) is the average of the errors over the k folds and hence this estimate of the error is uncertain. The lambda.1se represents the value of \(λ\) in the search that was simpler than the best model (lambda.min), but which has error within 1 standard error of the best model. In other words, using the value of lambda.1se as the selected value for \(λ\) results in a model that is slightly simpler than the best model but which cannot be distinguished from the best model in terms of error given the uncertainty in the k-fold CV estimate of the error of the best model. Read more here
In general though, the objective of regularization is to balance accuracy and simplicity. In the present context, this means a model with the smallest number of coefficients that also gives a good accuracy. To this end, the cv.glmnet function finds the value of lambda that gives the simplest model but also lies within one standard error of the optimal value of lambda. This value of lambda(lambda.1se) is what we’ll use to predict our fitted model on test set.
#prediction on test set
lasso_predictions <- predict(lasso_model, newx = mat_test, s = "lambda.1se", type = "response")
lasso_predictions <- as.factor(ifelse(lasso_predictions>0.5,1,0))
cm_lasso.m6 <- confusionMatrix(data=lasso_predictions, reference=test_num$risk_bin, positive='0')
cm_lasso.m6Confusion Matrix and Statistics
Reference
Prediction 0 1
0 21 8
1 74 197
Accuracy : 0.7267
95% CI : (0.6725, 0.7763)
No Information Rate : 0.6833
P-Value [Acc > NIR] : 0.059
Kappa : 0.2237
Mcnemar's Test P-Value : 7.071e-13
Sensitivity : 0.22105
Specificity : 0.96098
Pos Pred Value : 0.72414
Neg Pred Value : 0.72694
Prevalence : 0.31667
Detection Rate : 0.07000
Detection Prevalence : 0.09667
Balanced Accuracy : 0.59101
'Positive' Class : 0
#Model performance plot
#define performance
# score test data/model scoring for ROc curve - lasso_model
lasso.prob <- predict(lasso_model,type="response", newx =mat_test, s = 'lambda.1se')
lasso_model_pred <- prediction(lasso.prob,test_num$risk_bin)
lasso_model_perf <- performance(lasso_model_pred,"tpr","fpr")#plot roc curves
#lasso_model
plot(lasso_model_perf,colorize=TRUE, main="LASSO: ROC curve - type measure:auc")
lines(x=c(0, 1), y=c(0, 1), col="red", lwd=1, lty=3);
lines(x=c(1, 0), y=c(0, 1), col="green", lwd=1, lty=4)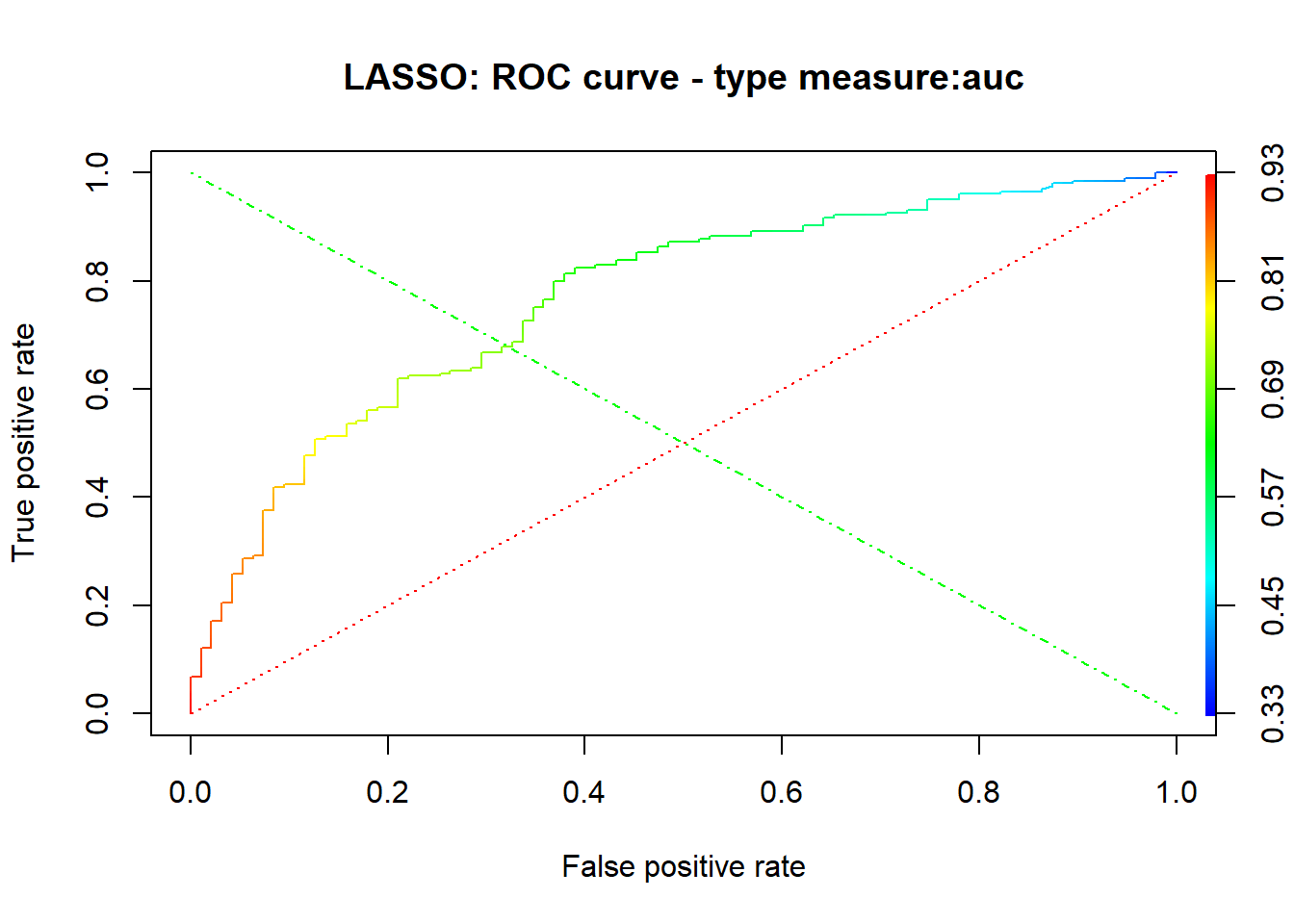
# Plot precision/recall curve
lasso_perf_precision <- performance(lasso_model_pred, measure = "prec", x.measure = "rec")
plot(lasso_perf_precision, main="lasso_model: Plot Precision/recall curve")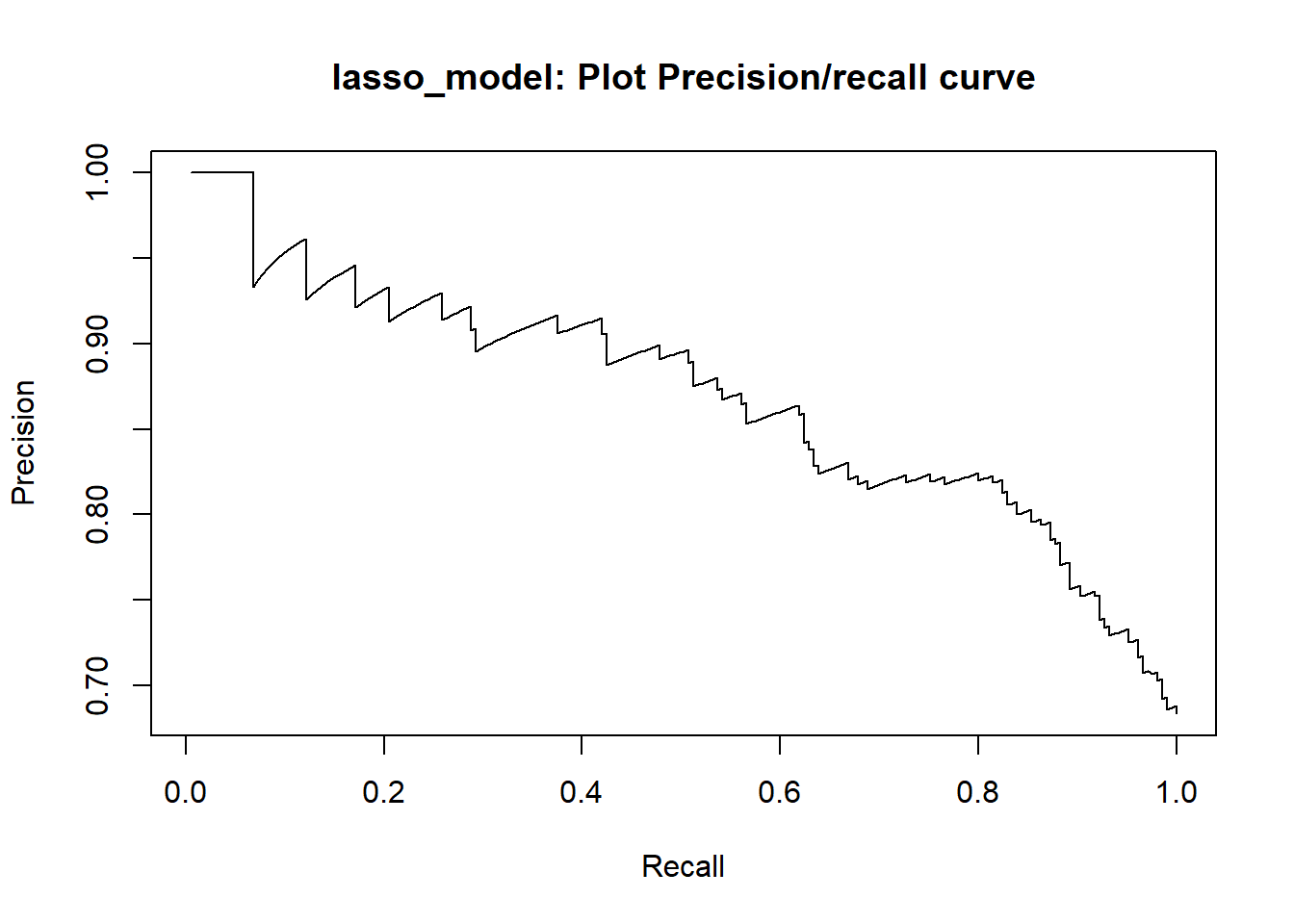
#AUC : Lasso model
lasso_model.AUROC <- round(performance(lasso_model_pred, measure = "auc")@y.values[[1]], 4)
lasso_model.AUROC 0.7675As we can notice, Lasso regression model shows a good overall accuracy and good AUC performance.
5.2. Model optimization
Although we usually recommend studying both specificity and sensitivity, very often it is useful to have a one number summary, for example for optimization purposes. One metric that is preferred over overall accuracy is the average of specificity and sensitivity, referred to as balanced accuracy. Because specificity and sensitivity are rates, it is more appropriate to compute the harmonic average which give us the F1-score.Balanced accuracy is discussed in this paper, while further details for the F1-score are given here.
\[Balanced Accuracy \ (BACC) = \frac{\mbox{sensitivity} + \mbox{specificity}} {2}\]
\[F_1 \ score = 2 \times \frac{\mbox{precision} \cdot \mbox{recall}} {\mbox{precision} + \mbox{recall}}\]
More over, we are going to define two other accuracy metrics KS and Gini that will support results of AUC. The kolmogorov-Smirnov test (KS-test) tries to determine if two classes differ significantly. In our case we are trying to measure whether the model is able to classify “good” class from “bad” class very well. If they are completely separated (i.e AUROC = 100%) then the value of KS will be 1(100%) and if they are same then the value of KS will be 0 (0%) . This means higher the value is better classification power . In simple term , KS= Max distance between distributions of two classes .
KS-Test comparison cumulative Fraction plot
Read more here : Massey(1951)
For the Gini coefficient , we already defined his relationship with the AUROC in paragraph IV.2 ( Gini = 2AUC -1)
5.2.1.
Model Performance Comparision - Measures of Accuracy
- Balanced Accuracy , F1-score, Recall, Precision
# models Performance Table
models <- c('m1:Logistic regression', 'm1_1:Logistic regression - important vars',
'm2:Decision tree','m2_1:Decision tree - pruning',
'm3:Random forest', 'm3_1: Random forest - important vars',
'm3_2: Random forest- tuning parameters',
"m4:SVM,radial", "m4_1:SVM,radial - important vars",
"m4_2:SVM,vanilladot", "m5: Neural net", "m6:Lasso reg")
#i get overall accuracy for each model
avg_acc <- round(c( cm_logreg.m1$overall[['Accuracy']],
cm_logreg.m1_1$overall[['Accuracy']],
cm_dtree.m2$overall[['Accuracy']],
cm_dtree.m2_1$overall[['Accuracy']],
cm_rf.m3$overall[['Accuracy']],
cm_rf.m3_1$overall[['Accuracy']],
cm_rf.m3_2$overall[['Accuracy']],
cm_svm.m4$overall[['Accuracy']],
cm_svm.m4_1$overall[['Accuracy']],
cm_svm.m4_2$overall[['Accuracy']],
cm_neuralnet.m5$overall[['Accuracy']],
cm_lasso.m6$overall[['Accuracy']]),4 )For the balanced accuracy, we can also get it directly from the output of the confusion matrix. cm$byClass[['Balanced Accuracy']] corresponds to the formula we define first. ( (sensitivity + specificity) / 2)
#balanced accuracy
balanced_acc <- round(c(cm_logreg.m1$byClass[['Balanced Accuracy']],
cm_logreg.m1_1$byClass[['Balanced Accuracy']],
cm_dtree.m2$byClass[['Balanced Accuracy']],
cm_dtree.m2_1$byClass[['Balanced Accuracy']],
cm_rf.m3$byClass[['Balanced Accuracy']],
cm_rf.m3_1$byClass[['Balanced Accuracy']],
cm_rf.m3_2$byClass[['Balanced Accuracy']],
cm_svm.m4$byClass[['Balanced Accuracy']],
cm_svm.m4_1$byClass[['Balanced Accuracy']],
cm_svm.m4_2$byClass[['Balanced Accuracy']],
cm_neuralnet.m5$byClass[['Balanced Accuracy']],
cm_lasso.m6$byClass[['Balanced Accuracy']]),4)F1-score : The F_meas function in the caret package computes this summary with beta defaulting to 1 (Irrizary, 2018) .It corresponds to the F1 score formula we defined at the beginning of the paragraph.
#F1score
F1score.m1 <- round(F_meas(data=reg_predictions,reference=test$Risk),4)
F1score.m1_1 <- round(F_meas(data=reg_predictions.new,reference=test$Risk),4)
F1score.m2 <- round(F_meas(data=dt_predictions,reference=test$Risk),4)
F1score.m2_1 <- round(F_meas(data=pruned_predictions,reference=test$Risk),4)
F1score.m3 <- round(F_meas(data=rf_predictions, reference=test$Risk),4)
#2*(0.6734694*0.3666667) / ( 0.3666667 + 0.6734694 )
F1score.m3_1 <- round(F_meas(data=rf_predictions.new, reference=test$Risk),4)
F1score.m3_2 <- round(F_meas(data=rf_predictions.best, reference=test$Risk),4)
F1score.m4 <- round(F_meas(data=svm_predictions, reference=test$Risk),4)
F1score.m4_1 <- round(F_meas(data=svm_predictions.best , reference=test$Risk),4)
F1score.m4_2 <- round(F_meas(data=svm_predictions.vanilla, reference=test$Risk),4)
F1score.m5 <- round(F_meas(data=neur.net_predictions , reference=test_nn$risk_bin),4)
F1score.m6 <- round(F_meas(data=lasso_predictions , reference=test_num$risk_bin),4)
F1_score <- c(F1score.m1, F1score.m1_1,
F1score.m2, F1score.m2_1,
F1score.m3, F1score.m3_1,
F1score.m3_2, F1score.m4,
F1score.m4_1, F1score.m4_2,
F1score.m5, F1score.m6)We can observe that in paragraph IV.2, formula (8) is the same as formula (11). Then we can get recall metric as sensitivity from the output of the confusion matrix. Instead , for the Precision metric, formula(10) , its value in the confusionMatrix output corresponds to the PPV(positive pred value).Read more here
#recall
recall <- round(c(cm_logreg.m1$byClass[['Sensitivity']],
cm_logreg.m1_1$byClass[['Sensitivity']],
cm_dtree.m2$byClass[['Sensitivity']],
cm_dtree.m2_1$byClass[['Sensitivity']],
cm_rf.m3$byClass[['Sensitivity']],
cm_rf.m3_1$byClass[['Sensitivity']],
cm_rf.m3_2$byClass[['Sensitivity']],
cm_svm.m4$byClass[['Sensitivity']],
cm_svm.m4_1$byClass[['Sensitivity']],
cm_svm.m4_2$byClass[['Sensitivity']],
cm_neuralnet.m5$byClass[['Sensitivity']],
cm_lasso.m6$byClass[['Sensitivity']]),4)
#precision
precision <- round(c(cm_logreg.m1$byClass[['Pos Pred Value']],
cm_logreg.m1_1$byClass[['Pos Pred Value']],
cm_dtree.m2$byClass[['Pos Pred Value']],
cm_dtree.m2_1$byClass[['Pos Pred Value']],
cm_rf.m3$byClass[['Pos Pred Value']],
cm_rf.m3_1$byClass[['Pos Pred Value']],
cm_rf.m3_2$byClass[['Pos Pred Value']],
cm_svm.m4$byClass[['Pos Pred Value']],
cm_svm.m4_1$byClass[['Pos Pred Value']],
cm_svm.m4_2$byClass[['Pos Pred Value']],
cm_neuralnet.m5$byClass[['Pos Pred Value']],
cm_lasso.m6$byClass[['Pos Pred Value']]),4)# Combine Recall, Precision, balanced_acc, F1_score
model_performance_metric_1 <- as.data.frame(cbind(models, recall, precision, balanced_acc , F1_score, avg_acc))
# Colnames
colnames(model_performance_metric_1) <- c("Models", "Recall", "Precision", "Balanced Accuracy", "F1-score", "Accuracy")
# kable performance table metrics group1
kable(model_performance_metric_1,caption ="Comparison of Model Performances") %>%
kable_styling(bootstrap_options = "striped" , full_width = F , position = "center") %>%
kable_styling(bootstrap_options = "bordered", full_width = F , position ="center") %>%
column_spec(1,bold = T ,color ="white", background = "blue") %>%
column_spec(2,bold = T , color ="white", background = "lightsalmon") %>%
column_spec(3,bold = T , color ="white", background = "darksalmon") %>%
column_spec(4,bold = T ,color ="white", background = "coral" ) %>%
column_spec(5,bold = T , color ="white", background = "tomato") %>%
column_spec(6,bold =T ,color = "white" , background ="#D7261E")| Models | Recall | Precision | Balanced Accuracy | F1-score | Accuracy |
|---|---|---|---|---|---|
| m1:Logistic regression | 0.4889 | 0.6197 | 0.6802 | 0.5466 | 0.7567 |
| m1_1:Logistic regression - important vars | 0.3333 | 0.5455 | 0.6071 | 0.4138 | 0.7167 |
| m2:Decision tree | 0.4778 | 0.5443 | 0.6532 | 0.5089 | 0.7233 |
| m2_1:Decision tree - pruning | 0.3667 | 0.5593 | 0.6214 | 0.443 | 0.7233 |
| m3:Random forest | 0.4111 | 0.74 | 0.6746 | 0.5286 | 0.78 |
| m3_1: Random forest - important vars | 0.4556 | 0.6406 | 0.673 | 0.5325 | 0.76 |
| m3_2: Random forest- tuning parameters | 0.4222 | 0.7451 | 0.6802 | 0.539 | 0.7833 |
| m4:SVM,radial | 0.0111 | 0.3333 | 0.5008 | 0.0215 | 0.6967 |
| m4_1:SVM,radial - important vars | 0.2889 | 0.6842 | 0.6159 | 0.4062 | 0.7467 |
| m4_2:SVM,vanilladot | 0.5111 | 0.6133 | 0.6865 | 0.5576 | 0.7567 |
| m5: Neural net | 0.4316 | 0.4184 | 0.5768 | 0.4249 | 0.63 |
| m6:Lasso reg | 0.2211 | 0.7241 | 0.591 | 0.3387 | 0.7267 |
Here, we compared models by group, and based on model_performance_metric_1 . The first criteria of comparison is the overall accuracy. Then, further discrimination is through F1-score, Balanced accuracy, precision and recall. For the first group , Logistic regression models, m1 is definitively better with all metrics greater than m1_1. For the second group, decision trees, since m2 and m2_1 have the same overall accuracy, the choice of m2 as better model comes up after comparing Balanced accuracy and F1 score values. For the random forests models, the choice is clear and without ambiguity since m3_2 is also the model which gets among all the fitted models in our study, the highest overall accuracy value, 0.7833. The group of SVM models indicates that m4_2, the support vector machine model with vanilladot Linear kernel function, shows the best overall accuracy value as well as best F1-score and balanced accuracy values.
- AUC, KS, GINI
#selected models
models2 <- c('m1:Logistic regression',
'm2:Decision tree',
'm3_2: Random forest- tuning parameters',
"m4_2:SVM,vanilladot",
"m5: Neural net",
"m6:Lasso reg")
#i store all AUC values in models_AUC
models_AUC <- c (reg_model.AUROC,
dt_model.AUROC,
rf_bestmodel.AUROC,
svm.van_model.AUROC,
neur_model.AUROC,
lasso_model.AUROC)
#i calculate KS-test
#logistic reg
m1.KS <- round(max(attr(reg_model.perf,'y.values')[[1]]-attr(reg_model.perf,'x.values')[[1]])*1, 4)
#decision tree
m2.KS <- round(max(attr(dt_perf,'y.values')[[1]]-attr(dt_perf,'x.values')[[1]])*1, 4)
# random forest
m3_2.KS <- round(max(attr( rf.best_perf,'y.values')[[1]]-attr( rf.best_perf,'x.values')[[1]])*1, 4)
#SVM
m4_2.KS <- round(max(attr(svm.van_perf,'y.values')[[1]]-attr( svm.van_perf,'x.values')[[1]])*1, 4)
#Neural network
m5.KS <- round(max(attr(neur.net_perf,'y.values')[[1]]-attr( neur.net_perf,'x.values')[[1]])*1, 4)
#Lasso regression
m6.KS <- round(max(attr(lasso_model_perf,'y.values')[[1]]-attr(lasso_model_perf,'x.values')[[1]])*1, 4)
#i store all KS values in models_KS
models_KS <- c(m1.KS,
m2.KS,
m3_2.KS,
m4_2.KS,
m5.KS,
m6.KS)
#Gini : i calculate GINI values for each fitted model , 2*AUROC - 1
# Log. reg
m1.Gini <- (2 * reg_model.AUROC - 1)
# decision tree
m2.Gini <- (2 * dt_model.AUROC - 1)
# random forests
m3_2.Gini <- (2*rf_bestmodel.AUROC - 1)
# SVM
m4_2.Gini <- (2*svm.van_model.AUROC- 1)
#Neural net
m5.Gini <- (2*neur_model.AUROC -1)
#Lasso
m6.Gini <- (2*lasso_model.AUROC -1 )
#i store all GINI values in models_Gini
models_Gini <- c(m1.Gini,
m2.Gini,
m3_2.Gini,
m4_2.Gini,
m5.Gini,
m6.Gini)
# Combine AUC, KS, GINI
model_performance_metric_2 <- as.data.frame(cbind(models2, models_AUC, models_KS, models_Gini))
# Colnames
colnames(model_performance_metric_2) <- c("Models", "AUC", "KS", "Gini")
#kable performance table metrics group2
kable(model_performance_metric_2,caption ="Comparison of Model Performances") %>%
kable_styling(bootstrap_options = "striped" , full_width = F , position = "center") %>%
kable_styling(bootstrap_options = "bordered", full_width = F , position ="center") %>%
column_spec(1,bold = T ,color ="white", background = "blue" ) %>%
column_spec(2,bold = T ,color ="white", background = "coral" ) %>%
column_spec(3,bold = T , color ="white", background = "tomato") %>%
column_spec(4,bold =T ,color = "white" , background ="#D7261E")| Models | AUC | KS | Gini |
|---|---|---|---|
| m1:Logistic regression | 0.7741 | 0.4635 | 0.5482 |
| m2:Decision tree | 0.7477 | 0.446 | 0.4954 |
| m3_2: Random forest- tuning parameters | 0.7813 | 0.4571 | 0.5626 |
| m4_2:SVM,vanilladot | 0.7794 | 0.4857 | 0.5588 |
| m5: Neural net | 0.6185 | 0.2521 | 0.237 |
| m6:Lasso reg | 0.7675 | 0.4357 | 0.535 |
From the comparative study , we found that random forests-tuning parameters performing better than other methods with given set-up. This random forest model is constitued by the 5 top variables based on MeanDecrease Gini , which is an average mean of a variable’s total decrease in node impurity, weighted by the proportion of samples reaching that node in each individual decision tree in the random forest. A higher mean decrease in GIni indicates a higher variable importance. This model shows a good overall accuracy, 0.7833 and the highest performance on AUC and Gini values , i.e 0.7813 and 0.5626, respectively.(Even if its KS value is the third after the one of m4_2 and m1 models). Also, we found that the SVM-vanilladot results to be the second best classifier after m3_2, since to equal overall accuracy value with Logistic regression model m1, it shows higher values of AUC, KS and GINI, i.e 0.7794, 0.4857 and 0.5588, respectively. Finally, comparing m1 and m6 metrics values, at first eye, we could choose logistic regression model as better model.
So, why we prefer Lasso than logistic? : The output of coef(lasso_model,s=lambda_1se) (see below) shows that 9 out of 12 variables that we had determined to be significant based on the basis of p-values (in m1 model) have non-zero coefficients. The coefficients of other variables have been set to zero by the algorithm. Lasso has reduced the complexity of the fitting function massively. That explained too the effect on the overall accuracy value of m6 , which is a less than what we got with m1. So, we get a similar out-of-sample accuracy (0,7567 m1 vs 0.7267 m6, i.e a difference of only 0.039%) as we did before, and we do so using a way simpler function(9 non-zero coefficients) than the orginal one( 12 non zero coefficients, 15 non zero coefficients if we take into account all predictors in m1,significant or not). What this means is that the simpler function does at least as good a job fitting the signal in the data as the more complicated one. The bias-variance tradeoff tell us that the simpler function should be preferred because it is less likely to overfit the training data. Read more here
Thats why, at the end, after models m3_2 and m4_2, we choose as third best classifier the lasso regression model , m6.
lambda_1se <- lasso_model$lambda.1se
coef(lasso_model, s=lambda_1se)17 x 1 sparse Matrix of class "dgCMatrix"
1
(Intercept) -0.90543365
(Intercept) .
check_acct 0.42029673
credit_hist 0.23474145
Duration -0.02074873
savings_acct 0.08818443
Purpose .
Age .
Property -0.04136937
Amount .
present_emp 0.01521461
Housing .
other_install 0.12194408
status_sex 0.02845865
ForeignWorker -0.05414408
other_debt .
installment_rate . 5.2.2.
Model Performance Comparison - ROC curves
In paragraph 4.2, we already defined and explained what is the Receiver Operating Characteristic (ROC) curve. Here, we drew a model performance comparison based on the ROC curves of selected most accurate models: m1, m2, m3_2, m4_2, m6. We also added the ROC curve of the Neural network model (m5), the least accurate model. The “ROC curves: Model performance comparison” plot confirms our previous analysis.
#Compare ROC Performance of Models
plot(reg_model.perf, col='blue', lty=1, lwd=2,
main='ROC curves: Model Performance Comparison') # logistic regression
plot(dt_perf, col='green',lty=2, add=TRUE,lwd=2); #simple decision tree
plot(rf.best_perf, col='red',add=TRUE,lty=3,lwd=2.5); # random forest - tuning parameters
plot(svm.van_perf, col='Navy',add=TRUE,lty=4,lwd=2); # SVM, vanilladot
plot(neur.net_perf, col='gold',add=TRUE,lty=5,lwd=2); # Neural Network
plot(lasso_model_perf, col='purple',add=TRUE,lty=6,lwd=2); # Lasso regression
legend(0.55,0.4,
c('m1:Logistic regression',
'm2:Decision tree',
'm3_2:Random forest- tuning parameters',
"m4_2:SVM,vanilladot",
"m5: Neural net",
"m6:Lasso reg"),
col=c("blue","green", "red","Navy", "gold", "purple"),
lwd=3,cex=0.7,text.font = 4);
lines(c(0,1),c(0,1),col = "Black", lty = 4 ) # random line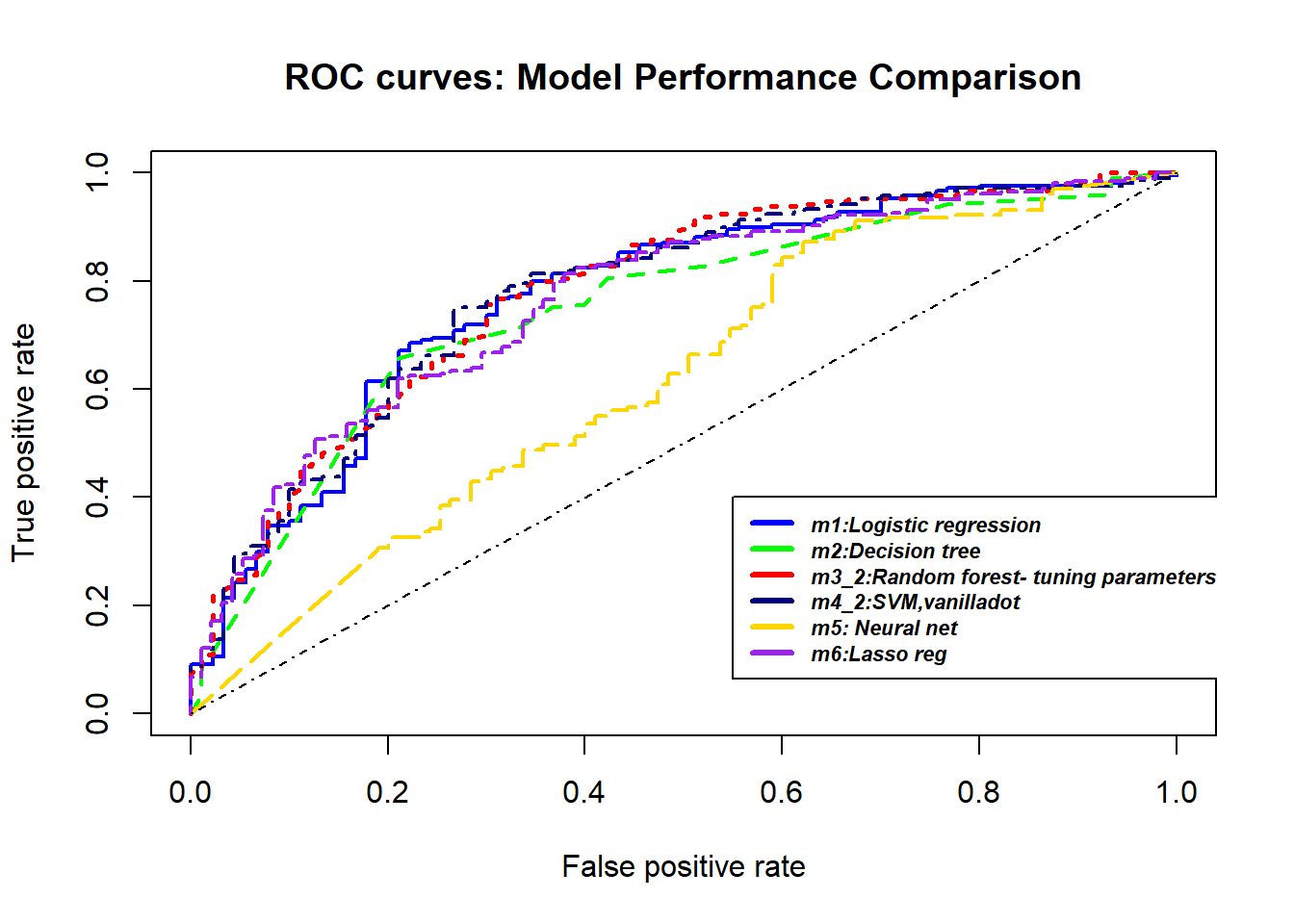
VI. Conclusions and suggestions
This German credit risk project has examined the potential best Machine learning algorithm to classify credit worthiness for the 1000 applicants of the rchallenge version of german credit data. Using the splitted training set and test set, we successively trained different classifiers algorithms (logistic regression, support vector machines, decision trees, Neural networks, Lasso regression) and predict each fitted model on test set. The model evaluation performance through the overall accuracy, F1-score and balanced accuracy values, and optimization through AUC, KS and GINI values showed that random forest with tuning parameters, support vector machine based on vanilla linear kernel function and lasso regression, are the three appropriate machine learning algorithms to classify at best the credit risk of 1000 applicants to loan.
Future work includes further investigations on Ensemble methods by following the work of Wang et al(2011). In fact, in the latter, a comparative assessment of three popular ensemble methods, i.e. Bagging, Boosting, and Stacking, based on four base learners, i.e., Logistic Regression Analysis (LRA), Decision Tree (DT), Artificial Neural Network (ANN) and Support Vector Machine (SVM) could possibly carried out an overall accuracy greater than 0.8. However, we should precise that these results comes up by combining three datasets : German and Australian credit datasets, which are from UCI machine learning repository, and China credit dataset, which is from Industrial and Commercial Bank of China.
Several future research directions also emerge . Firstly, large datasets for experiments and applications, particularly with more exploration of credit scoring data structures, should be collected to further valid the conclusions of our study. Secondly, further analyses are encouraged to explore the reasons why the Neural Network model has the worst performance for all accuracy metrics.
References
Ha, V. S., & Nguyen, H. N. (2016). Credit scoring with a feature selection approach based deep learning. In MATEC Web of Conferences (Vol. 54, p. 05004). EDP Sciences.
Aggarwal, C. C. (Ed.). (2014). Data classification: algorithms and applications. CRC press.
Wang, G., Hao, J., Ma, J., & Jiang, H. (2011). A comparative assessment of ensemble learning for credit scoring. Expert systems with applications, 38(1), 223-230.
Therneau, T. M., & Atkinson, E. J. (2018). An Introduction to Recursive Partitioning Using the RPART Routines.
Vapnik, V. (1998). The nature of statistical learning theory. Springer science & business media.
Karatzoglou, A., Meyer, D., & Hornik, K. (2005). Support vector machines in R.
Chang, C. C., & Lin, C. J. (2011). LIBSVM: A library for support vector machines. ACM transactions on intelligent systems and technology (TIST), 2(3), 27.
Meyer, D., & Wien, F. T. (2015). Support vector machines. The Interface to libsvm in package e1071, 28.
Cortes, C. & Vapnik, V. (1995). Support-vector network. Machine Learning, 20, 1–25.
Ripley, B., Venables, W., & Ripley, M. B. (2016). Package ‘nnet’. R package version, 7, 3-12.
Soni, A. K., & Abdullahi, A. U. (2015). Using neural networks for credit scoring. Int. J. Sci. Technol. Manag, 4.
Liu, Y. (2002). The evaluation of classification models for credit scoring. Institut für Wirtschaftsinformatik, Georg-August-Universitat Göttingen.
Bock, H. H. (2001). Construction and Assessment of Classification Rules. David J. Hand, Wiley, Chichester, 1997. No. of pages: xii+ 214. Price:£ 34.95. ISBN 0â€471â€96583â€9. Statistics in Medicine, 20(2), 326-327.
Sivakumar,S.,2015,German credit Data Analysis,github page, http://srisai85.github.io/GermanCredit/German.html
Liaw A, Wiener M (2002). “Classification and Regression by randomForest.†R News, 2(3),18–22. URL http://CRAN.R-project.org/doc/Rnews/.
Kursa, M. B., & Rudnicki, W. R. (2010). Feature selection with the Boruta package. J Stat Softw, 36(11), 1-13.
Siddiqi, Naeem (2006). Credit Risk Scorecards: Developing and Implementing Intelligent Credit Scoring. SAS Institute, pp 79-83.
Therneau, T. M., & Atkinson, E. J. (2018). An Introduction to Recursive Partitioning Using the RPART Routines.
Hand, David J.; and Till, Robert J. (2001); A simple generalization of the area under the ROC curve for multiple class classification problems, Machine Learning, 45, 171–186.
Hand, D. J., & Henley, W. E. (1997). Statistical classification methods in consumer credit scoring: a review. Journal of the Royal Statistical Society: Series A (Statistics in Society), 160(3), 523-541.
Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological), 58(1), 267-288.
Massey Jr, F. J. (1951). The Kolmogorov-Smirnov test for goodness of fit. Journal of the American statistical Association, 46(253), 68-78.
Günther, F., & Fritsch, S. (2010). neuralnet: Training of neural networks. The R journal, 2(1), 30-38.
Beck, M. W. (2018). NeuralNetTools: Visualization and analysis tools for neural networks. Journal of statistical software, 85(11), 1.
Soni, A. K., & Abdullahi, A. U. (2015). Using neural networks for credit scoring. Int. J. Sci. Technol. Manag, 4.